设计一个简易版的数据库路由
- 作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术
- 如果感觉博主的文章还不错的话,请三连支持一下博主哦
- 博主正在努力完成2023计划中:源码溯源,一探究竟
- 联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
文章目录
- 数据库路由
-
- 需求设计
- 方案设计
-
- 基于HashMap实现
- 基于Mybatis实现
-
- Mybatis的工作原理
-
- 构建会话工厂
- 会话运行
-
- Executor(执行器)
- StatementHandler(数据库会话器)
- ParameterHandler (参数处理器)
- ResultSetHandler(结果处理器)
- 说说Mybatis的插件运行原理,如何编写一个插件?
-
- 插件的运行原理?
- 如何编写一个插件?
- MyBatis是如何进行分页的?分页插件的原理是什么?
-
- MyBatis是如何分页的?
- 分页插件的原理是什么?
- 核心代码
-
- 注解
- 配置加载
-
- 数据库连接源的加载
- 配置加载
- 策略使用
-
- 基于HashMap
- 基于Mybatis
- 测试效果
-
- 配置文件
- 基于HashMap
数据库路由
代码链接:https://gitee.com/ni-hongsheng/db-router.git
需求设计
数据库的分库分表的实现算法其实有很多,比如大名鼎鼎的mychat等,都可以解决这个问题,但是他们存在的问题是太重了,这也是众多功能堆积起来的后果。如果从零到一实现数据库分库分表呢?那么传统的思路是什么,都能在什么层面上解决这个问题呢?不如自己来实现一个数据库分库分表的插件出来。
方案设计
当有了需求,需要考虑要在什么层面上实现数据库路由呢,实现分库分表呢?其本质又是什么呢?其本质举个例子:比如说插入一条数据,鬼知道要插入到哪个库那个表里面去,先不考虑任何可扩展的问题,怎么插入,传统的mychat会有取余,哈希等办法吧。对这是一个好办法,但是一定非要这样嘛,现在的开发基本上都是使用SpringBoot + Mybatis的开发吧,如果基于Mybatis来实现这个,是不是也是一个思路呢?所以实现的方案就包含了两种,一种是基于HashMap实现,一种是基于Mybatis实现。
基于HashMap实现
相信能看这篇文章的基本上都了解HashMap的,算得上是必须要熟悉的基础知识了,初始就16个位置的数组,当我们往HashMap中存储的时候,其为了尽可能的避免HashMap碰撞,使其分布的更加均匀,做了很多的工作,如果产生了碰撞,链表和红黑树的优化做的也很好,但是这个终归是备用方案,实际上其HashMap的Hash函数设计的非常的好,其本质上是Hash函数的前十六位与后十六位异或,然后在与(size-1)与。通过这样设计能尽可能的减少碰撞。所以基于HashMap的实现的核心就是将这套方案迁移进算法的实现中。
其中HashMap的基础知识可以参考这篇文章:如果面试也能这样说HashMap,那么就不会有那么多遗憾!-CSDN博客
基于Mybatis实现
关于Mybatis的分库分表的额实现比较复杂,得从Mybatis的工作原理说起
Mybatis的工作原理
我们已经大概知道了MyBatis的工作流程,按工作原理,可以分为两大步: 生成会话工厂 、 会话运行
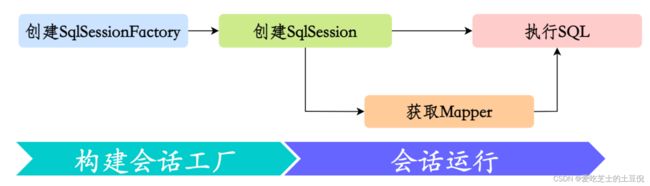
MyBatis是一个成熟的框架,篇幅限制,这里抓大放小,来看看它的主要工作流程。
构建会话工厂
构造会话工厂也可以分为两步:
- 获取配置
获取配置这一步经过了几步转化,最终由生成了一个配置类Configuration实例,这个配置类实例非常重要,主要作用包括:
- 读取配置文件,包括基础配置文件和映射文件
- 初始化基础配置,比如MyBatis的别名,还有其它的一些重要的类对象,像插件、映射器、ObjectFactory等等
- 提供一个单例,作为会话工厂构建的重要参数
- 它的构建过程也会初始化一些环境变量,比如数据源
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
SqlSessionFactory var5;
//省略异常处理
//xml配置构建器
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
//通过转化的Configuration构建SqlSessionFactory
var5 = this.build(parser.parse());
}
- 构建SqlSessionFactory
SqlSessionFactory只是一个接口,构建出来的实际上是它的实现类的实例,一般我们用的都是它的实现类DefaultSqlSessionFactory
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
会话运行
会话运行是MyBatis最复杂的部分,它的运行离不开四大组件的配合:
Executor(执行器)
Executor起到了至关重要的作用,SqlSession只是一个门面,相当于客服,真正干活的是是Executor,就像是默默无闻的工程师。它提供了相应的查询和更新方法,以及事务方法。
Environment environment = this.configuration.getEnvironment();
TransactionFactory transactionFactory =
this.getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//通过Configuration创建executor
Executor executor = this.configuration.newExecutor(tx, execType);
var8 = new DefaultSqlSession(this.configuration, executor, autoCommit);
StatementHandler(数据库会话器)
StatementHandler,顾名思义,处理数据库会话的。我们以SimpleExecutor为例,看一下它的查询方法,先生成了一个StatementHandler实例,再拿这个handler去执行query。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
List var9;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms,
parameter, rowBounds, resultHandler, boundSql);
stmt = this.prepareStatement(handler,ms.getStatementLog());
var9 = handler.query(stmt, resultHandler);
} finally {
this.closeStatement(stmt);
}
return var9;
}
再以最常用的PreparedStatementHandler看一下它的query方法,其实在上面的prepareStatement 已经对参数进行了预编译处理,到了这里,就直接执行sql,使用ResultHandler处理返回结果。
public <E> List<E> query(Statement statement,ResultHandler resultHandler) throws SQLException {
PreparedStatement ps =(PreparedStatement)statement;
ps.execute();
return this.resultSetHandler.handleResultSets(ps);
}
ParameterHandler (参数处理器)
PreparedStatementHandler里对sql进行了预编译处理
public void parameterize(Statement statement) throws SQLException {
this.parameterHandler.setParameters((PreparedStatement)statement);
}
这里用的就是ParameterHandler,setParameters的作用就是设置预编译SQL语句的参数。
里面还会用到typeHandler类型处理器,对类型进行处理。
public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement var1) throwsSQLException;
}
ResultSetHandler(结果处理器)
我们前面也看到了,最后的结果要通过ResultSetHandler来进行处理,handleResultSets这个方法就是用来包装结果集的。Mybatis为我们提供了一个DefaultResultSetHandler,通常都是用这个实现类去进行结果的处理的。
它会使用typeHandle处理类型,然后用ObjectFactory提供的规则组装对象,返回给调用者。
整体上总结一下会话运行:
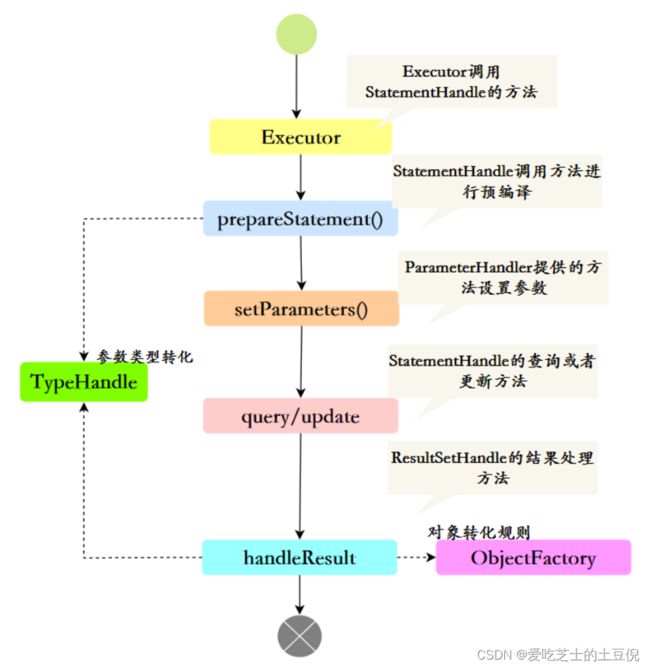
我们最后把整个的工作流程串联起来,简单总结一下:
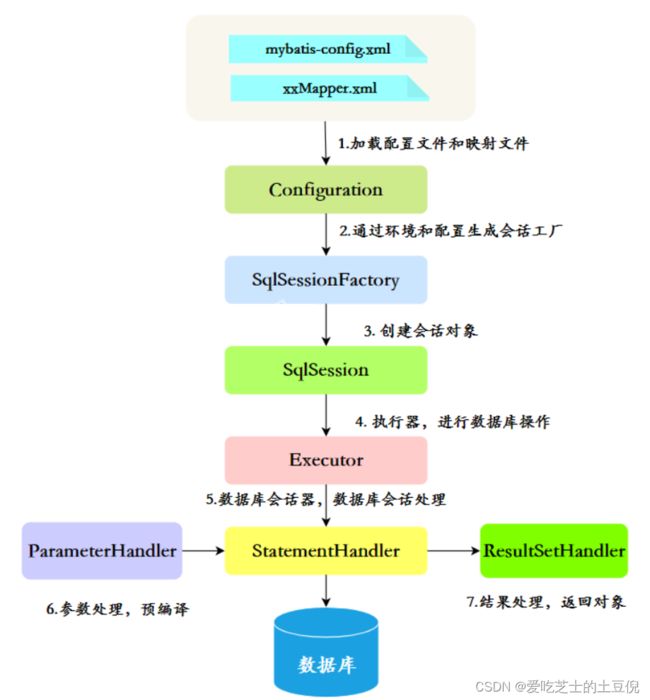
- 读取 MyBatis 配置文件——mybatis-config.xml 、加载映射文件——映射文件即SQL 映射文件,文件中配置了操作数据库的 SQL 语句。最后生成一个配置对象。
- 构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂SqlSessionFactory。
- 创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
- Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
- StatementHandler:数据库会话器,串联起参数映射的处理和运行结果映射的处理。
- 参数处理:对输入参数的类型进行处理,并预编译。
- 结果处理:对返回结果的类型进行处理,根据对象映射规则,返回相应的对象。
讲了这么多Mybatis的工作原理,那么是怎么基于Mybatis实现分库分表的呢?说说Mybatis的插件运行原理,如何编写一个插件?
说说Mybatis的插件运行原理,如何编写一个插件?
插件的运行原理?
Mybatis会话的运行需要ParameterHandler、ResultSetHandler、StatementHandler、Executor这四大对象的配合,插件的原理就是在这四大对象调度的时候,插入一些我我们自己的代码。
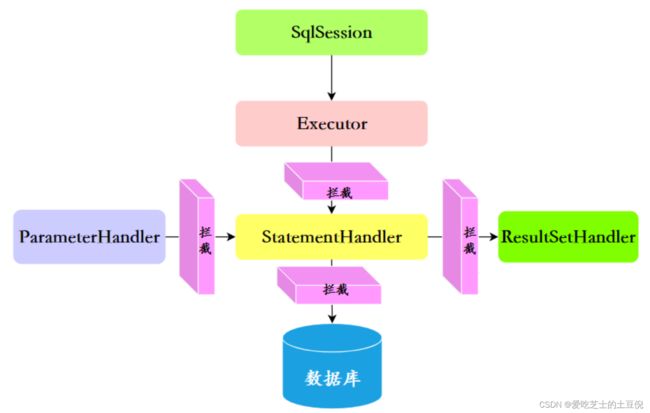
Mybatis使用JDK的动态代理,为目标对象生成代理对象。它提供了一个工具类Plugin ,实现了 InvocationHandler 接口。
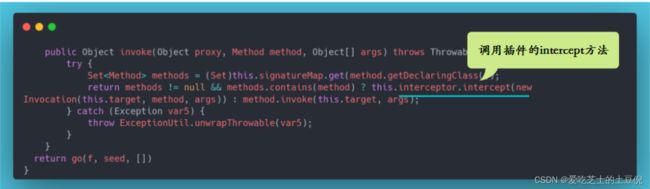
使用 Plugin 生成代理对象,代理对象在调用方法的时候,就会进入invoke方法,在invoke方法中,如果存在签名的拦截方法,插件的intercept方法就会在这里被我们调用,然后就返回结果。如果不存在签名方法,那么将直接反射调用我们要执行的方法。
如何编写一个插件?
我们自己编写MyBatis 插件,只需要实现拦截器接口 Interceptor (org.apache.ibatis.plugin Interceptor ),在实现类中对拦截对象和方法进行处理。
实现Mybatis的Interceptor接口并重写intercept()方法
public class MyInterceptor implements Interceptor {
Properties props=null;
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("before……");
//如果当前代理的是一个非代理对象,那么就会调用真实拦截对象的方法
// 如果不是它就会调用下个插件代理对象的invoke方法
Object obj=invocation.proceed();
System.out.println("after……");
return obj;
}
}
然后再给插件编写注解,确定要拦截的对象,要拦截的方法
@Intercepts({@Signature(
type = Executor.class, //确定要拦截的对象
method = "update", //确定要拦截的方法
args = {MappedStatement.class,Object.class} //拦截方法的参数
)})
public class MyInterceptor implements Interceptor {
Properties props=null;
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("before……");
//如果当前代理的是一个非代理对象,那么就会调用真实拦截对象的方法
// 如果不是它就会调用下个插件代理对象的invoke方法
Object obj=invocation.proceed();
System.out.println("after……");
return obj;
}
}
最后,再MyBatis配置文件里面配置插件
<plugins>
<plugin interceptor="xxx.MyPlugin">
<property name="dbType",value="mysql"/>
plugin>
plugins>
MyBatis是如何进行分页的?分页插件的原理是什么?
MyBatis是如何分页的?
MyBatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页。可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的原理是什么?
- 分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,拦截Executor的query方法
- 在执行查询的时候,拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
- 举例:select * from student,拦截sql后重写为:select t.* from (select * from student) t limit 0, 10
核心代码
注解
@Documented // 元注解表示该注解应该包含在生成的API文档中,以便开发者能够看到并了解它。
@Retention(RetentionPolicy.RUNTIME) // 元注解表示该注解的生命周期将保留到运行时,也就是说,在运行时可以通过反射机制获取并使用该注解。
@Target({ElementType.TYPE, ElementType.METHOD}) // 元注解表示该注解可以应用于类和方法上。
public @interface DBRouter {
String key() default "";
}
// 路由策略,分表标记
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouterStrategy {
boolean splitTable() default false;
}
配置加载
数据库连接源的加载
@Bean
public DataSource dataSource() {
// 创建数据源
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// 设置动态数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
// 设置默认数据源
dynamicDataSource.setDefaultTargetDataSource(new DriverManagerDataSource(defaultDataSourceConfig.get("url").toString(), defaultDataSourceConfig.get("username").toString(), defaultDataSourceConfig.get("password").toString()));
return dynamicDataSource;
}
// 动态数据源的事务管理
@Bean
public TransactionTemplate transactionTemplate(DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dataSource);
TransactionTemplate transactionTemplate = new TransactionTemplate();
transactionTemplate.setTransactionManager(dataSourceTransactionManager);
transactionTemplate.setPropagationBehaviorName("PROPAGATION_REQUIRED");
return transactionTemplate;
}
以上代码动态的配置了数据库的连接 和 事务
配置加载
public class DataSourceAutoConfig implements EnvironmentAware {
......
// 设置数据源,将数据源注入到属性当中
@Override
public void setEnvironment(Environment environment) {
String prefix = "mini-db-router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
routerKey = environment.getProperty(prefix + "routerKey");
// 分库分表数据源
String dataSources = environment.getProperty(prefix + "list");
assert dataSources != null;
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
// 默认数据源
String defaultData = environment.getProperty(prefix + "default");
defaultDataSourceConfig = PropertyUtil.handle(environment, prefix + defaultData, Map.class);
}
策略使用
基于HashMap
// 注入IDBRouterStrategy
// 在这里使用策略模式额外封装了一层,这样可以动态适配多个路由算法
@Bean
public IDBRouterStrategy dbRouterStrategy(DBRouterConfig dbRouterConfig) {
return new DBRouterStrategyHashCode(dbRouterConfig);
}
public class DBRouterStrategyHashCode implements IDBRouterStrategy {
private Logger logger = LoggerFactory.getLogger(DBRouterStrategyHashCode.class);
private DBRouterConfig dbRouterConfig;
public DBRouterStrategyHashCode(DBRouterConfig dbRouterConfig) {
this.dbRouterConfig = dbRouterConfig;
}
@Override
public void doRouter(String dbKeyAttr) {
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// 扰动函数;在 JDK 的 HashMap 中,对于一个元素的存放,需要进行哈希散列。而为了让散列更加均匀,
// 所以添加了扰动函数。
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// 库表索引;相当于是把一个长条的桶,切割成段,对应分库分表中的库编号和表编号
// 公式目的;8个位置,计算出来的是位置在5 那么你怎么知道5是在2库1表。
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// 设置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%03d", tbIdx));
logger.debug("数据库路由 dbIdx:{} tbIdx:{}", dbIdx, tbIdx);
}
@Override
public void setDBKey(int dbIdx) {
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
}
@Override
public void setTBKey(int tbIdx) {
DBContextHolder.setTBKey(String.format("%03d", tbIdx));
}
@Override
public int dbCount() {
return dbRouterConfig.getDbCount();
}
@Override
public int tbCount() {
return dbRouterConfig.getTbCount();
}
@Override
public void clear(){
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
其本质也如注释一般,计算出了扰动因子,然后通过扰动因子动态的计算数据库和表。
基于Mybatis
@Bean
public Interceptor plugin() {
return new DynamicMybatisPlugin();
}
/**
这个和mybatis的执行过程有关
*/
// 第一行标注了该拦截器需要拦截的方法,即prepare方法,
// 该方法在StatementHandler对象上执行。StatementHandler是MyBatis中用于处理预编译的SQL语句的接口。
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})
public class DynamicMybatisPlugin implements Interceptor {
// 使用正则表达式将SQL语句中的表名提取出来。正则表达式的模式为匹配以"from"、"into"或"update"开头的单词,
// 然后紧跟一个或多个空格,再紧跟一个或多个非空字符(即表名)。
private Pattern pattern = Pattern.compile("(from|into|update)[\\s]{1,}(\\w{1,})", Pattern.CASE_INSENSITIVE);
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 在intercept方法中,首先获取到被拦截的StatementHandler对象和相关的元数据信息。
// 获取StatementHandler
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY, SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 获取自定义注解判断是否进行分表操作
// 通过反射获取被拦截的方法对应的类,然后判断该类是否使用了自定义注解DBRouterStrategy,
// 并且该注解的splitTable属性为true。如果没有使用该注解或者splitTable属性为false,则直接返回,不进行分表操作。
String id = mappedStatement.getId();
String className = id.substring(0, id.lastIndexOf("."));
Class<?> clazz = Class.forName(className);
DBRouterStrategy dbRouterStrategy = clazz.getAnnotation(DBRouterStrategy.class);
// 如果使用了DBRouterStrategy注解并且splitTable属性为true,则获取当前SQL语句。
if (null == dbRouterStrategy || !dbRouterStrategy.splitTable()){
return invocation.proceed();
}
// 获取SQL
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
// 替换SQL表名 USER 为 USER_03
// 使用正则表达式将SQL语句中的表名提取出来。正则表达式的模式为匹配以"from"、"into"或"update"开头的单词,
// 然后紧跟一个或多个空格,再紧跟一个或多个非空字符(即表名)。
// 使用正则表达式替换原始SQL语句中的表名为新的表名。
Matcher matcher = pattern.matcher(sql);
String tableName = null;
if (matcher.find()) {
tableName = matcher.group().trim();
}
assert null != tableName;
// 将匹配到的表名与分表键值拼接,生成新的表名。
String replaceSql = matcher.replaceAll(tableName + "_" + DBContextHolder.getTBKey());
// 通过反射修改SQL语句
// 使用反射将修改后的SQL语句设置回BoundSql对象中。
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, replaceSql);
field.setAccessible(false);
// 最后调用invocation.proceed()方法继续执行原始的数据库操作。
return invocation.proceed();
}
// 该拦截器主要用于在满足特定条件时对SQL进行修改,实现动态分表的功能。
// 通过自定义注解DBRouterStrategy和正则表达式匹配,提取表名并进行替换,从而实现对特定表名的分表操作。
}
测试效果
配置文件
# 路由配置
router:
jdbc:
datasource:
dbCount: 2
tbCount: 4
list: db01,db02
db01:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/bugstack_01?useUnicode=true
username: root
password: 123456
db02:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/bugstack_02?useUnicode=true
username: root
password: 123456
基于HashMap
<select id="queryUserInfoByUserId" parameterType="cn.nhs.test.infrastructure.po.User"
resultType="cn.nhs.test.infrastructure.po.User">
SELECT id, userId, userNickName, userHead, userPassword, createTime
FROM user_${tbIdx}
where userId = #{userId}
select>
@Mapper
public interface IUserDao {
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
}
通过这样的路由计算就可以动态的插入到对应的库和表中,而基于Mybatis的更加方便,不需要修改mapper.xml文件即可实现。