实验二 :HIve数据定义操作实验
一、实验目的
(1)练习数据库操作。
(2)练习数据表操作。
二、实验环境
要首先自行搭建由3 台虚拟机构成的Hadoop环境及Hive环境。
三、实验内容
请参考《第5章 HiveQL:数据定义》文档进行Hive数据库操作实验及Hive数据表操作实验,要有实验步骤与实验截图,实验内容与截图不能实验指导手册内容相同。实验报告雷同一律零分。
5.Hive中的数据库
如果⽤户没有显示指定数据库,那么将会使⽤默认的数据库default。
5.1
5.1.1创建数据库


说明创建的数据库将被保存在⽬录/user/hive/warehouse下,数据库的名称为/user/hive/warehouse/*.db。Hive会为每个数据库创建⼀个⽬录,数据库中表将会以这个数据库⽬录的⼦⽬录形式存储。有⼀个例外就是default数据库中的表,这个数据库本身没有⾃⼰的⽬录。
创建一个数据库,指定数据库在HDFS上存放的位置

查看

5.1.2显示数据库
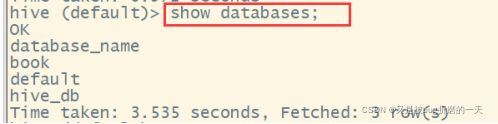
想显示特定的数据库,可以使用通配符*
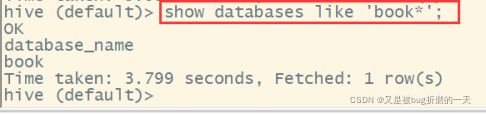
5.1.3查看数据库详情
Describe database语句会显示出这个数据库所在的⽂件⽬录位置路径。
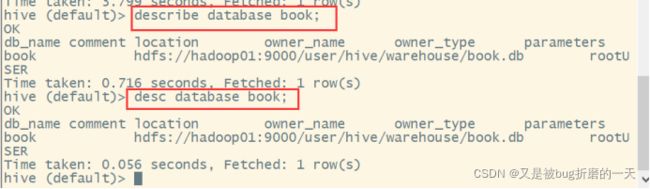
此外,⽤户还可以为数据库增加⼀些和其相关的键-值对属性信息,可以通过DESCRIBE database extended

 5.1.4设置当前数据库
5.1.4设置当前数据库
USE命令⽤于将某个数据库设置为⽤户当前的⼯作数据库,和在⽂件系统中切换⼯作⽬录是⼀个概念。

5.1.5删除数据库

默认情况下,Hive不允许删除⼀个包含有表的数据库,可以采⽤ cascade 命令,强制删除

5.1.6修改数据库
⽤户可以使⽤ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属
性值,来描述这个数据库的属性信息。数据库的其他元数据库信息是不可更改的,包括
数据库名和数据库所在的⽬录位置
没有办法可以删除或者重置数据库属性。

5.2
5.2.1创建表
创建表语法: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(1)CREATE TABLE 创建⼀个指定名称的表。如果相同名字的表已经存在,则抛出异常; ⽤户可以⽤ IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让⽤户创建⼀个外部表,在建表的同时可以指定⼀个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被⼀起删除,⽽外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
可以使⽤以下命令查看表的详细信息:
DESCRIBE EXTENDED|FORMATTED [database_name.]table_name;
(1)创建普通表

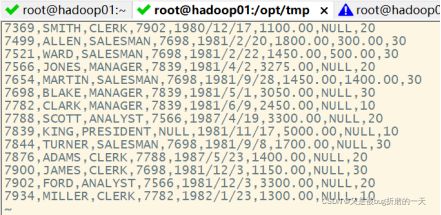
创建emp.txt文件并输入数据


5.2.2管理表
向emp表中导入数据

(2)根据查询结果创建表
查询的结果会添加到新创建的表中

(3)根据已经存在的表结构创建表---只会复制表结构,不会复制内容

(4)查询表的类型
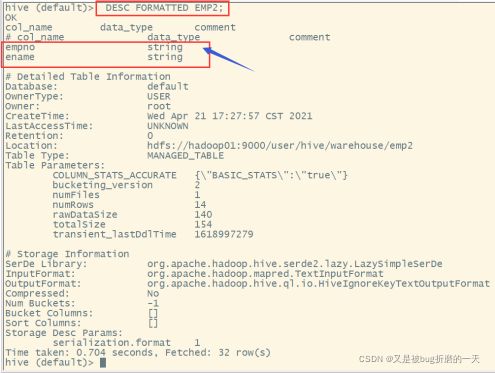
5.2.3 外部表
外部表主要解决数据共享的问题,同⼀份数据可以被多个外部表所引⽤。
在创建外部表的时候,需要指向数据的具体位置,相当于⼀个指针,外部表只是引⽤了数据的地址,访问表时再根据这个地址指针去找到相应的数据。
对于外部表,Hive 并⾮认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不
过描述表的元数据信息会被删除掉。
(1)创建⼀个外部表,其可以读取所有位于/user/hive/warehouse/emp⽬录下以逗号
分隔的数据:

关键字EXTERNAL告诉Hive这个表是外部的,⽽后⾯的LOCATION⼦句则⽤于告诉Hive真正的数据位于哪个路径下,这⾥的LOCATION是指HDFS下的路径。
(2)查看外部表中的数据
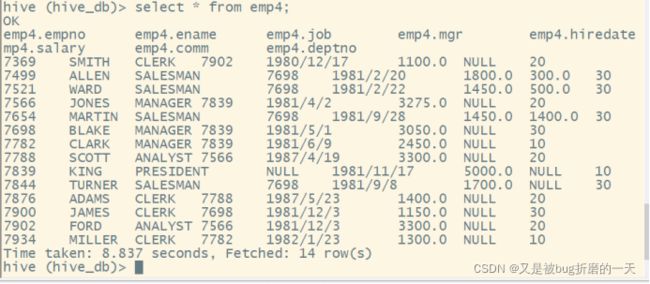
(3)查看表格式化数据

(4)删除外部表---外部表删除后,emp表中的数据还在,但是 metadata 中 emp4 的元数据已被删除。

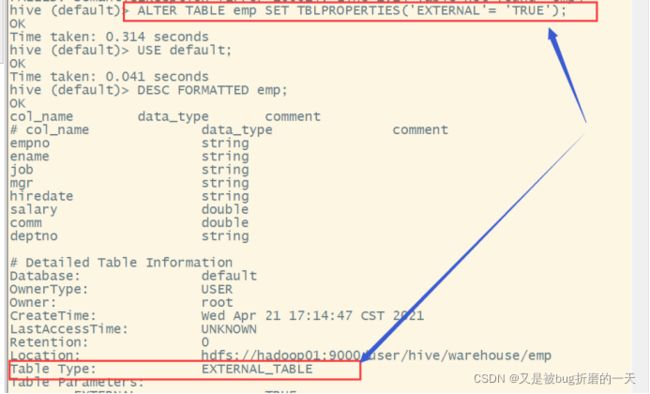
 5.2.4 管理表与外部表的相互转换
5.2.4 管理表与外部表的相互转换
命令:
ALTER TABLE table_name SET TBLPROPERTIES('EXTERNAL' = 'TRUE | FALSE')
注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分⼤⼩写!
 5.2.5分区表
5.2.5分区表
分区表可以将数据以⼀种符合逻辑的⽅式进⾏组织,⽐如分层存储。⼀个分区实际上就是表下的⼀个⽬录,⼀个表可以在多个维度上进⾏分区,分区之间的关系就是⽬录树的关系。
分区表改变了Hive对数据存储的组织⽅式。上⾯我们在default数据库中创建的表emp,
对于这个表只会有⼀个emp⽬录与之对应:hdfs://master/user/hive/warehouse/emp
(1)创建分区表语法

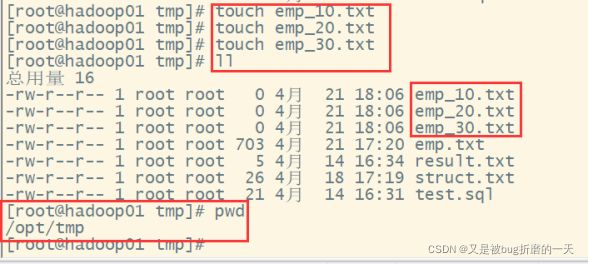
注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。(2)为分区加载数据—提前在/opt/tmp里面创建好emp_10.txt, emp_20.txt, emp_30.txt
![]()

![]()

![]()

(3)向emp1表中导入数据
注意:分区表加载数据时,必须指定分区
LOAD DATA LOCAL INPATH '/opt/tmp/emp_20.txt' INTO TABLE emp1
PARTITION(deptno='20');

 查看
查看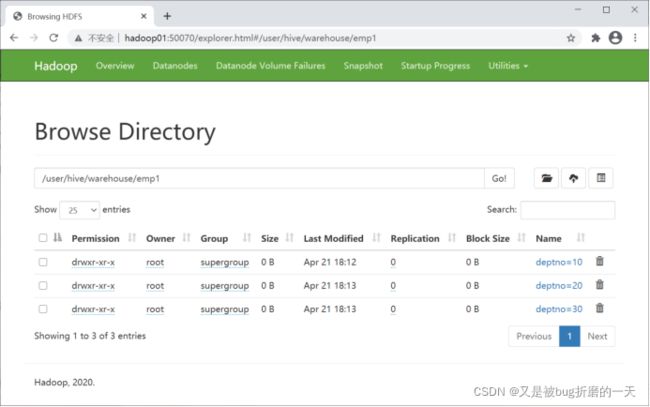
(4)查询分区表中的数据
单分区查询

多分区查询
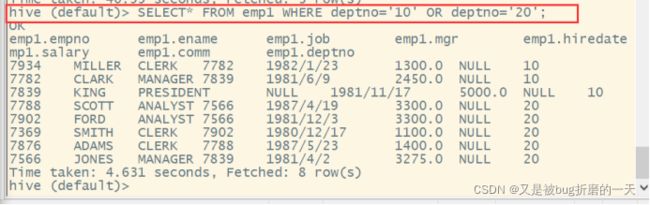
#多分区查询也可以使⽤union关键字来合并两个查询结果。
(5)增加分区
1.创建单个分区

查看
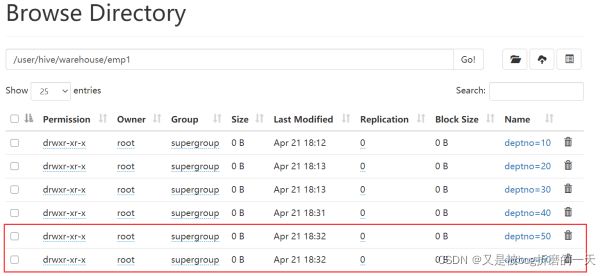
 2.创建多个分区
2.创建多个分区

查看
(6)删除分区
1.删除单个分区

查看

2.删除多个分区

查看
 (7)查看分区表有多少个分区
(7)查看分区表有多少个分区
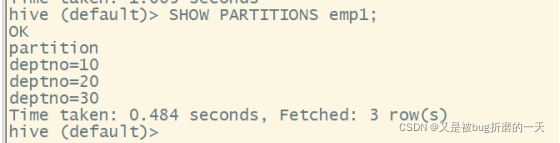
(8)查看分区表的结构

(9)创建多级分区-------先按deptno分区,再按job分区

分区后的⽬录结构如下所示:emp2/deptno=10/job=CLERK
emp2/deptno=10/job=MANAGER
emp2/deptno=10/job=PRESIDENT
emp2/deptno=20/job=ANALYST
emp2/deptno=20/job=CLERK
emp2/deptno=20/job=MANAGER
emp2/deptno=30/job=CLERK
emp2/deptno=30/job=MANAGER
emp2/deptno=30/job=SALESMAN
(10)为多级分区加载数据
提前创建好emp_10_clerk.txt
![]()

LOAD DATA LOCAL INPATH '/opt/tmp/emp_10_clerk.txt' INTO TABLE emp2
PARTITION(deptno='10',job='CLERK');

(11)查询多级分区数据

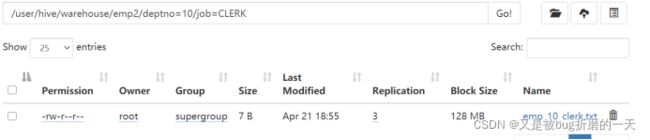
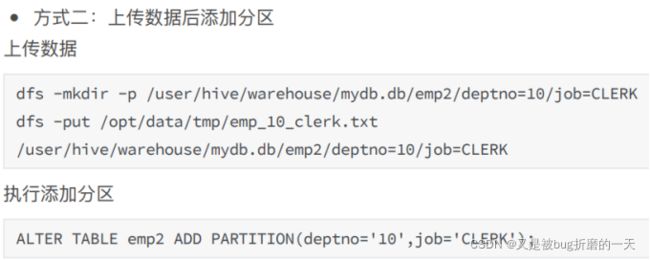
(12)把数据直接上传到分区目录上,让分区表和数据产生关联的两种方式
方式1:上传数据后修复
上传数据

查询数据
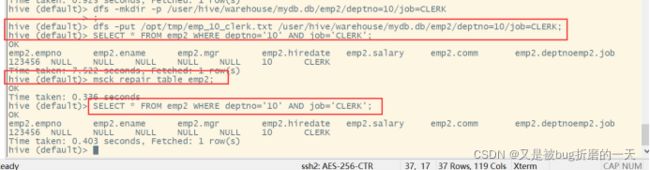
 执行修复命令
执行修复命令

(13)动态分区调整
关系型数据库中,对分区表插⼊数据时候,数据库⾃动会根据分区字段的值,将数据插⼊到相应的分区中,Hive中也提供了类似的机制,即动态分区(Dynamic Partition),使⽤ Hive 的动态分区时需要进⾏相应的配置。
例子:将 emp表中的数据按照deptno、job字段,插⼊到⽬标表 emp3的相应分区中创建⽬标分区表

设置动态分区

设置动态分区时,分区字段deptno、job按顺序放在选择字段的后⾯。选择的字段要和
表结构字段⼀⼀对应。
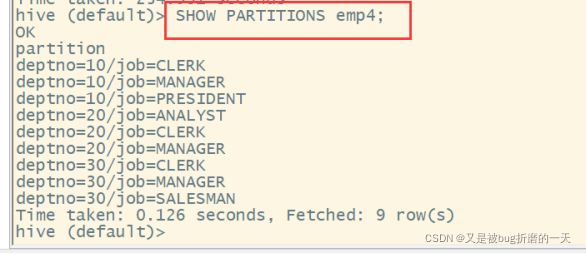
查看目标分区表的分区情况
5.2.6外部分区表
外部表也可以使⽤分区,对外部表进⾏分区是管理⼤型⽣产数据集最常⻅的情况。
例子:下⾯举⼀个⽇志⽂件分析例⼦。
对于⽇志信息,⼀般使⽤⼀个标准的格式,其中有时间戳、严重程序(例如ERROR、WARN、INFO),以及服务器名称和进程ID,后⾯跟着⼀个可以为任何内容的⽂本信息。
假设我们要进⾏数据抽取、数据转换、数据装载以及⽇志⽂件聚合过程,将每条⽇志信息转换为按照制表键分割的记录,并将时间戳解析成年、月、日3个字段,剩余的hms部分作为⼀个字段。
//⼀种⽅式是⽤户可以使⽤Hive或者Pig内置字符串解析函数来完成这个⽇志信息解析过程。另⼀种⽅式是,使⽤较⼩的数值类型来保存时间戳相关的字段以节省空间。
(1)按如下⽅式来定义对应的Hive表:
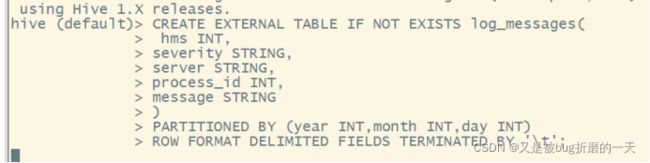
将⽇志数据按照天进⾏划分,划分的数据尺⼨合适,⽽且按天这个粒度进⾏查询速度也
⾜够快
增加⼀个2012年1⽉2⽇的分区

5.2.7删除表

对于管理表,表的元数据信息和表内的数据都会被删除;对于外部表,只有表的元数据
信息会被删除,表内的数据仍会保留。
5.2.8修改表
使⽤ALTER TABLE命令修改元数据,但不会修改数据本身
(1)表重命名

(2)增加、修改和删除表分区
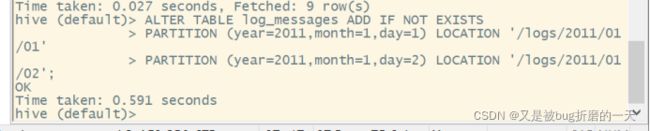
同时,⽤户还可以通过移动位置来修改某个分区的路径:

删除某个分区:


(3)修改列信息
⽤户可以对某个字段进⾏重命名,并修改其位置、类型或者注释:

(4)增加/替换列
注:ADD 是代表新增⼀字段,字段位置在所有列后⾯(partition 列前),REPLACE 则是
表示替换表中所有字段。

(5)修改表属性

四、实验心得体会
写出你在做实验的过程中遇到的问题,是怎么解决的,应该注意什么?
创建数据
![]()

上传数据到hdfs在hdfs手动创建文件夹dly/day=26,上传数据:
![]() 创建外部分区表
创建外部分区表

查看表:
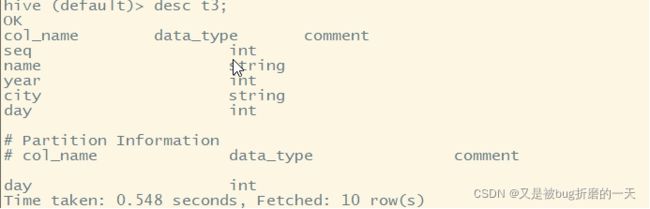
将外部数据指向hdfs数据
![]()
查看指向后的数据
