TensorRT模型优化部署(四)--Roofline model
系列文章目录
第一章 TensorRT优化部署(一)–TensorRT和ONNX基础
第二章 TensorRT优化部署(二)–剖析ONNX架构
第三章 TensorRT优化部署(三)–ONNX注册算子
第四章 TensorRT模型优化部署(四)–Roofline model
第五章 TensorRT模型优化部署(五)–模型优化部署重点注意
第六章 TensorRT模型优化部署(六)–Quantization量化基础(一)
第七章 TensorRT模型优化模型部署(七)–Quantization量化(PTQ and QAT)(二)
文章目录
- 系列文章目录
- 前言
- 一、模型部署基本知识
-
- 1.1 FLOPS(Floating point number operations per second)
- 1.2 TOPS(Tera operations per second)
- 1.3 性能指标
-
- 1.3.1 计算量
- 1.3.2 计算峰值
- 1.3.3 参数量
- 1.3.4 访存量
- 1.3.5 带宽
- 二、Roofline model(屋顶线模型)
-
- 2.1 为什么要学习Roofline model?
- 2.2 Operational intensity (计算密度)
- 2.3 性能分析
-
- 2.3.1 Operational intensity (计算密度) – kernel size的影响(FP32)
- 2.3.2 Operational intensity (计算密度) – output size的影响(FP32)
- 2.3.3 Operational intensity (计算密度) – channel size的影响(FP32)
- 2.3.4 Operational intensity (计算密度) – group convolution的影响(FP32)
- 2.3.5 Operational intensity (计算密度) – tensor reshape的影响(FP32)
- 2.3.6 Operational intensity (计算密度) – FC的影响(FP32)
- 2.4 模型分析
- 总结
前言
模型优化部署专题内容,后续有补充。
一、模型部署基本知识
1.1 FLOPS(Floating point number operations per second)
指的是一秒钟可以处理的浮动小数点运算的次数, 是衡量计算机硬件性能、计算能力的一个单位。是衡量模型大小的一个指标。
FLOPS = 频率 * core数量 * 每个时钟周期可以处理的FLOPS
Intel i7 Haswell架构 (8核,频率3.0GHz)。那么它的FLOPS在双精度的时候就是:
3.0 * 10^9 Hz * 8 core * 16 FLOPS/clk = 0.38 TFLOPS
那么它的FLOPS在单精度的时候就是:
3.0 * 10^9 Hz * 8 core * 32 FLOPS/clk = 0.76 TFLOPS
FLOPs不能完全衡量模型性能,因为FLOPs只是模型计算大小的单位
还需要考虑
- 访存量
- 与计算无关的DNN部分
- DNN以外的部分
注意:轻量化的模型不一定代码效率越高,推理时间越短。
1.2 TOPS(Tera operations per second)
指的是一秒钟可以处理的整型运算的次数,是衡量计算机硬件性能、计算能力的一个单位。
1.3 性能指标
1.3.1 计算量
单位是FLOPs,表示模型中有多少个floating point operations,是衡量模型大小的标准

Swin Transformer中的FLOPs[1]
1.3.2 计算峰值
单位是FLOPS (也可以是FLOP/s),表示计算机每秒可以执行的 floating point operations。是衡
量计算机性能的标准。
在部署前需要了解计算峰值是多少,可参考
1.3.3 参数量
单位是Byte,表示模型中所有的weights(主要在conv和FC中)的量,是衡量模型大小的标准。
1.3.4 访存量
单位是Byte,表示模型中某一个算子,或者某一层layer进行计算时需要与memory产生read/write的量。是分析模型中某些计算的计算效率的标准之一。
注意:参数量和访存量的单位都是byte,但不一样。conv的参数量就是weight的大小,跟input/ouput无关。 访存量是跟Input/output相关。transformer的参数会根据输入tensor大小改变而改变。
1.3.5 带宽
单位是Byte/s,全称是memory bindwidth,表示的是单位时间内可以传输的数据量的多少。是衡量计算机硬件memor性能的一个标准。
带宽跟以下因素有关:
• memory clock (GHz)
表示单位时间内可以read/write的频率(Hz),一般以GHz为基本单位
• memory bus width (Byte)
表示的是可以同时读写的数据多少,单位是Byte
• memory channel
表示的是通道数量,越多越好
举例:
CPU
Intel Xeon Gold 6000 (server)
memory: DDR4-2666
memory clock: 2666 MHz
memory bus width: 8 Bytes
memory channel: 6
=> memory bindwidth = 2666 MHz * 8 Bytes * 6 = 128GB/s
NVIDIA Quadro RTX 6000
memory: GDDR6
memory clock: 1750 MHz
memory clock effective: 1750 MHz * 8 = 14Gbps
memory interface width: 48 Bytes (384 bits)
=> memory bandwidth = 14 Gbps * 48 Bytes * 1 = 672GB/s
二、Roofline model(屋顶线模型)
2.1 为什么要学习Roofline model?
Roofline model(屋顶线模型)是一种性能建模和优化方法,用于可视化和分析程序在计算资源(特别是内存带宽和计算性能)上的使用情况。
Roofline model的基本思想是以计算核心性能(FLOPs)为横坐标,以内存带宽(GB/s)为纵坐标,将程序的性能和资源使用情况表示为一个“屋顶线”(Roofline)。屋顶线代表了系统硬件资源的限制,即在给定的计算核心性能和内存带宽下,程序能够达到的最大性能。
- 分析3x3 conv, 5x5 conv, 7x7 conv, 9x9 conv, 11x11 conv的计算效率
- 1x1 conv的计算效率
- depthwise conv的计算效率
- 分析目前计算的瓶颈(bottleneck)
- 分析模型的可以优化的上限

不同的AMD架构的计算峰值、计算密度、带宽分析(左Opteron X2, 右Opteron X4)[2]
总结:在模型部署时不单单是将训练好的模型进行部署,而是要在模型创建初期就进行分析,有些计算效率较低的算子可以减少,选择计算密度比较高,同时对精度影响比较大,能够提高精度的算子,使得创建好的模型具备一定的并行性和计算效率。
2.2 Operational intensity (计算密度)
单位是FLOPs/Byte,表示的是传送单位数据可以进行的浮点运算数。
计算密度 =计算量/访存量
我们可以通过提高计算密度,让我们的硬件尽量处于饱和状态,从而提高计算效率。

2.3 性能分析
3080 Ampere架构
Core种类与数量
- 8704 CUDA cores
- 272 Tensor cores
- 68 SMs
计算峰值
- (FP32) 29.8TFLOPS (
- FP16) 119 TFLOPS
- (INT8) 238 TOPS
带宽
- 760.32 GB/s
频率
- 1.7GHz
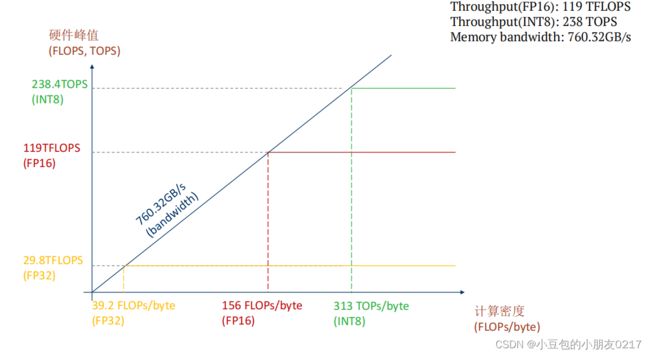
接下来从下面几个方面分析对计算密度的影响
{ k e r n e l s i z e 的影响 ( F P 32 ) o u t p u t s i z e 的影响 ( F P 32 ) c h a n n e l s i z e 的影响 ( F P 32 ) g r o u p c o n v o l u t i o n 的影响 ( F P 32 ) t e n s o r r e s h a p e 的影响 ( F P 32 ) F C 的影响 ( F P 32 ) \left\{ \begin{array}{l} kernel\quad size的影响(FP32)\\ \\ output\quad size的影响(FP32)\\ \\ channel\quad size的影响(FP32)\\ \\ group\quad convolution的影响(FP32) \\ \\ tensor\quad reshape的影响(FP32)\\ \\ FC的影响(FP32)\end{array}\right. ⎩ ⎨ ⎧kernelsize的影响(FP32)outputsize的影响(FP32)channelsize的影响(FP32)groupconvolution的影响(FP32)tensorreshape的影响(FP32)FC的影响(FP32)
2.3.1 Operational intensity (计算密度) – kernel size的影响(FP32)
计算量:2 ∗ 2 ∗ ∗
访存量: 2 ∗ ∗ + 2 ∗ ∗ 4
M: 卷积核输出特征图的H和W。不同的时候可以用Mh, Mw表示K: 卷积核大小

由上表可以看出,k=1时,计算量小(0.205520896),但是计算密度也低(59.16981132),随着kernel_size的增大,计算密度增长率逐渐下降,并不是呈线性增长。
2.3.2 Operational intensity (计算密度) – output size的影响(FP32)
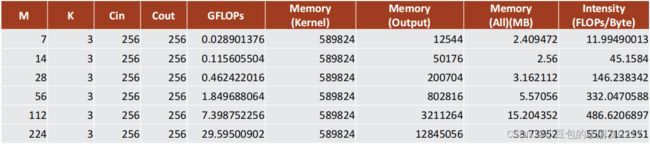
output size对计算密度的影响,随着output size变大,计算密度的增长率逐渐下降。
2.3.3 Operational intensity (计算密度) – channel size的影响(FP32)
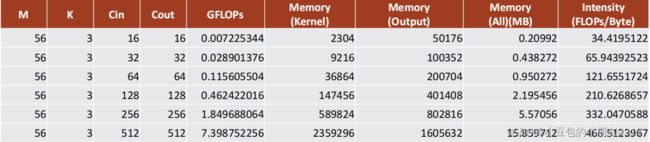
越大的channel size计算密度越高,计算密度的增长率逐渐下降。
2.3.4 Operational intensity (计算密度) – group convolution的影响(FP32)
以depthwise conv为例

group convolution对计算密度的影响。depthwise虽然降低了计算量,但计算密度也下降的很多。
2.3.5 Operational intensity (计算密度) – tensor reshape的影响(FP32)
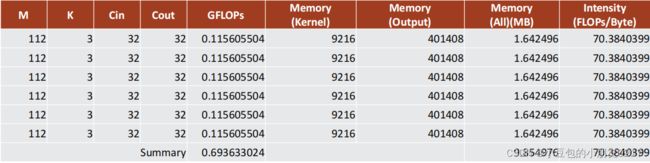
不参与计算的tensor reshape对计算密度的影响(模型中没有tensor reshape)

不参与计算的tensor reshape对计算密度的影响(模型中有3个tensor reshape)
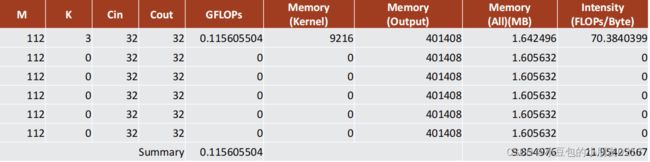
不参与计算的tensor reshape对计算密度的影响(模型中有5个tensor reshape)
计算密度下降的比较厉害,从70—>35—>11
2.3.6 Operational intensity (计算密度) – FC的影响(FP32)
计算量: ∗
访存量: ∗ ∗ 4
M: 卷积核输出特征图的H和W。不同的时候可以用Mh, Mw表示
K: 卷积核大小

(FC的计算密度非常低的原因在于它的大量的访存)
2.4 模型分析
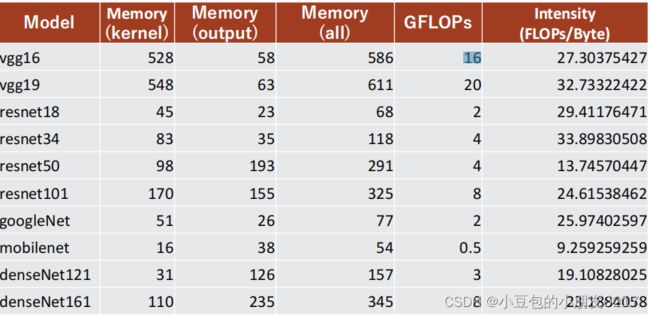
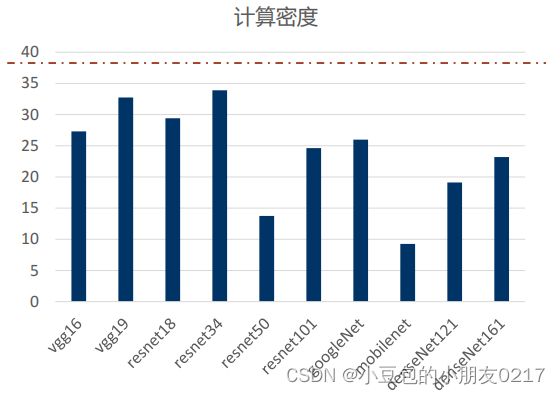
RTX 3080 Ampere架构中FP32的计算在39.2FLOPs/byte才达到计算饱和。所以这些
模型其理论上都没有计算饱和,实际上可能饱和了。
总结
本章为专题内容,主要介绍TensorRT优化部署,可移步专题查看其他内容。
[1]Swin Transformer GitHub
[2]Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures*