OceanBase架构概览
了解一个系统或软件,比较好的一种方式是了解其架构,下图是官网上的架构图,基于V 4.2.1版本
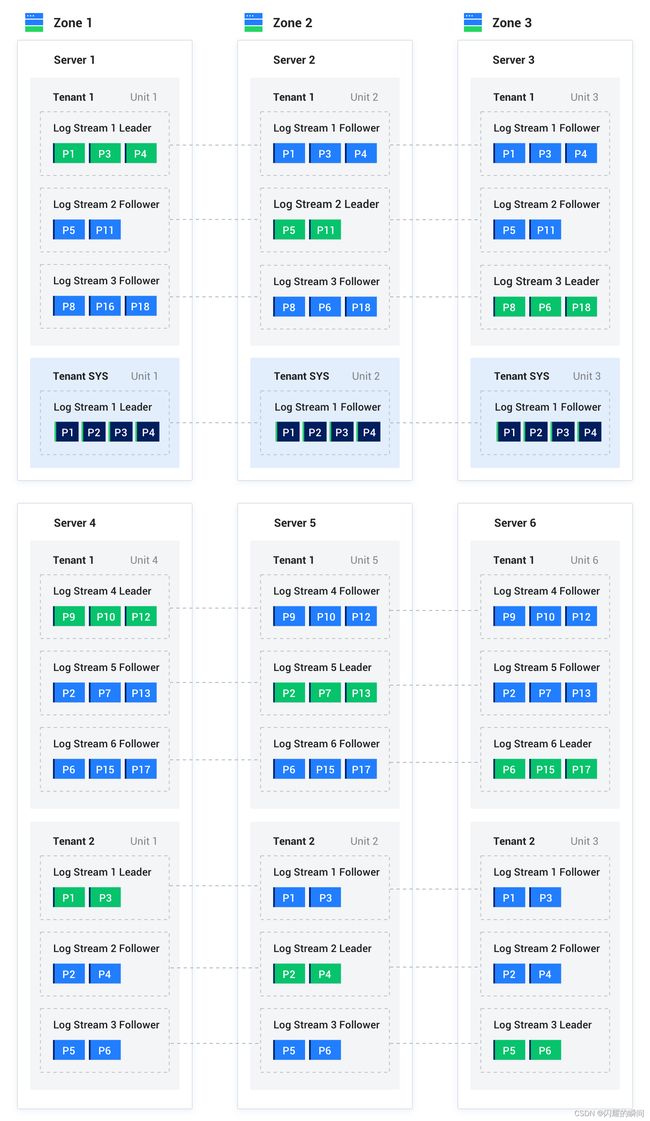
OceanBase 使用通用服务器硬件,依赖本地存储,分布式部署在多个服务器上,每个服务器都是对等的,数据库内的 SQL 执行引擎具有分布式执行能力,每台服务器上运行一个observer单进程数据库实例。
上图中有很多名词,下面名词解释:
Zone
zone代表可用区,由若干个服务器组成,可用区是一个逻辑概念,表示集群内具有相似硬件可用性的一组节点,也可以把zone当成一个数据中心,上图就有3个可用区Zone1、Zone2、Zone3,每个可用区内有2台服务器节点,共6台服务器。
Server
server代表服务器,上图共有6台服务器,属于不同可用区Zone。
Tenant
tenant代表租户,OceanBase内置多租户特性,每个租户是一个独立的数据库,一个租户能够在租户级别设置租户的分布式部署方式。租户之间 CPU、内存和 IO 都是隔离的,上图有3个租户:Tenant1、Tenant2、Tenant SYS。
Tenant SYS为系统租户,集群创建时就自动创建了系统租户,且不可扩容。
Unit
unit是租户在 OBServer 上的容器,描述租户在 OBServer 上的可用资源(CPU、MEMORY 等)。一个租户在一个 OBServer 只能同时存在一个 Unit,如:Tenant1租户,在6台Server上分别都运行了一个Unit。
OceanBase 数据库仅支持创建用户租户,系统租户由集群创建时自动创建。创建用户租户是一系列操作的组合,首先创建资源规格,然后基于该资源规格创建资源池,最后创建租户并指定其资源池。所以创建租户的顺序为:资源规格 -> 资源池 -> 租户。
- 资源规格:用来描述可以使用多少资源(CPU、内存、IO),仅仅是规格定义,不实际分配资源,可以通过
DBA_OB_UNIT_CONFIGS视图查看所有资源规格。 - 资源池:创建资源池时会实际创建 Unit,按照规格定义分配资源,如对应节点预留资源不够将会创建失败,如果创建成功可以通过
DBA_OB_RESOURCE_POOLS视图和DBA_OB_UNITS视图查看资源池及其对应 Unit。资源池不能复用,成功创建租户后指定资源池将会分配给租户。 - 租户:创建租户时通过指定
RESOURCE_POOL_LIST将资源池分配给租户,可以通过DBA_OB_TENANTS视图查看所有租户。可以每个 Zone 一个资源池,使用独立的资源规格。也可以所有 Zone 使用同一个资源池,从而所有 Zone 使用同一个资源规格。除了资源池列表,还有兼容模式、Primary Zone、Locality、连接白名单等其他重要属性和系统变量,其中资源池列表为创建租户时的必填项。
创建租户的顺序为:资源规格 -> 资源池 -> 租户 的命令:
1.使用 root 用户登录到集群的 sys 租户
obclient -h172.30.xx.xx -P2883 -uroot@sys#cluster -p**** -A
2.进入 oceanbase 数据库
USE oceanbase;
3.通过 DBA_OB_UNIT_CONFIGS 视图,获取已有的资源规格信息。
obclient [oceanbase]> SELECT * FROM oceanbase.DBA_OB_UNIT_CONFIGS;
4.创建资源规格:
CREATE RESOURCE UNIT S1_unit_config MEMORY_SIZE = '5G', MAX_CPU = 1, MIN_CPU = 1, LOG_DISK_SIZE = '6G', MAX_IOPS = 10000, MIN_IOPS = 10000, IOPS_WEIGHT=1;
5.查看资源池和创建资源池(mq_pool_01使用上面的资源规格S1_unit_config)
SELECT * FROM oceanbase.DBA_OB_RESOURCE_POOLS;
CREATE RESOURCE POOL mq_pool_01 UNIT='S1_unit_config', UNIT_NUM=1, ZONE_LIST=('zone1','zone2');
6.创建租户
SELECT * FROM oceanbase.DBA_OB_TENANTS;
CREATE TENANT IF NOT EXISTS mq_t1 PRIMARY_ZONE='zone1', RESOURCE_POOL_LIST=('mq_pool_01') set OB_TCP_INVITED_NODES='%';
7.租户登录,默认管理员用户(MySQL 模式为 root,Oracle 模式为 sys)的密码为空,您需要及时修改管理员用户的密码
7.1.登录 mq_t1 租户的 root 用户:obclient -h172.30.xx.xx -P2883 -uroot@mq_t1#cluster -A
7.2.修改 root 用户的密码:ALTER USER root IDENTIFIED BY '****';
8.重新登录:obclient -h172.30.xx.xx -P2883 -uroot@mq_t1#cluster -p**** -A
LogStream
logstream表示日志流,是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,可在上图中看到有LogStream Leader、Follower,且分布在不同Server上,它通过 Paxos 协议实现了多副本日志同步,保证副本间数据的一致性,实现了数据的高可用。
P 表示分区
Partition是用户创建的逻辑对象,是划分和管理表数据的一种机制,分区表会有多个分片,由OceanBase自动管理,单表最多配置8192个分片,所以单表能存储大量数据(官方号称万亿行)。
每个分片默认有3个副本,用于故障容灾,也可以用于分散读取压力,同一个租户在一个可用区内的数据只有一个副本,上图中Tenant1租户P1分片在Unit1、Unit2、Unit3上都存在,且在Unit1上绿色P1是主分片。
OceanBase同时存在两份数据MemTable和SSTable,SQL操作插入、更新、删除等首先写入 MemTable(内存),速度快,依赖 Paxos 协议实现了多副本日志同步,保障数据不丢失,历史存量数据在SSTable里面 ,在每天的业务低峰期,系统会将所有的 MemTable 合并成SSTable,操作历史数据时,由于写到了内存中,而SSTable中也保存了一份,所以根据版本号对同一条数据进行区分,保证数据一致性。
OceanBase 的数据库实例内部由不同的组件相互协作,这些组件从底层向上由存储层、复制层、均衡层、事务层、SQL 层、接入层组成。
存储层
以一张表或者一个分区为粒度提供数据存储与访问,每个分区对应一个用于存储数据的Tablet(分片),用户定义的非分区表也会对应一个 Tablet。
Tablet 的内部是分层存储的结构,总共有 4 层。DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 L0 SSTable。L0 SSTable 个数达到阈值后会将多个 L0 SSTable 合并成一个 L1 SSTable。在每天配置的业务低峰期,系统会将所有的 MemTable、L0 SSTable 和 L1 SSTable 合并成一个 Major SSTable。
每个 SSTable 内部是以 2MB 定长宏块为基本单位,每个宏块内部由多个不定长微块组成。
Major SSTable 的微块会在合并过程中用编码方式进行格式转换,微块内的数据会按照列维度分别进行列内的编码,编码规则包括字典/游程/常量/差值等,每一列压缩结束后,还会进一步对多列进行列间等值/子串等规则编码。编码能对数据大幅压缩,同时提炼的列内特征信息还能进一步加速后续的查询速度。
在编码压缩之后,还可以根据用户指定的通用压缩算法进行无损压缩,进一步提升数据压缩率。
复制层
复制层使用日志流(LS、Log Stream)在多副本之间同步状态。每个 Tablet 都会对应一个确定的日志流,每个日志流对应多个 Tablet,DML 操作写入 Tablet 的数据所产生的 Redo 日志会持久化在日志流中。日志流的多个副本会分布在不同的可用区中,多个副本之间维持了Paxos 协议共识算法,选择其中一个副本作为主副本,其他的副本皆为从副本。
如有故障可自行选主,能够自动应对服务器故障,保障数据库服务的持续可用。
均衡层
新建表和新增分区时,系统会按照均衡原则选择合适的日志流创建 Tablet。当租户的属性发生变更,新增了机器资源,或者经过长时间使用后,Tablet 在各台机器上不再均衡时,均衡层通过日志流的分裂和合并操作,并在这个过程中配合日志流副本的移动,让数据和服务在多个服务器之间再次均衡。
当租户有扩容操作,获得更多服务器资源时,均衡层会将租户内已有的日志流进行分裂,并选择合适数量的 Tablet 一同分裂到新的日志流中,再将新日志流迁移到新增的服务器上,以充分利用扩容后的资源。当租户有缩容操作时,均衡层会把需要缩减的服务器上的日志流迁移到其他服务器上,并和其他服务器上已有的日志流进行合并,以缩减机器的资源占用。
当数据库长期使用后,随着持续创建删除表,并且写入更多的数据,即使没有服务器资源数量变化,原本均衡的情况可能被破坏。最常见的情况是,当用户删除了一批表后,删除的表可能原本聚集在某一些机器上,删除后这些机器上的 Tablet 数量就变少了,应该把其他机器的 Tablet 均衡一些到这些少的机器上。均衡层会定期生成均衡计划,将 Tablet 多的服务器上日志流分裂出临时日志流并携带需要移动的 Tablet,临时日志流迁移到目的服务器后再和目的服务器上的日志流进行合并,以达成均衡的效果。
事务层
事务层保证了单个日志流和多个日志流DML操作提交的原子性,也保证了并发事务之间的多版本隔离能力。
SQL层
SQL 层将用户的 SQL 请求转化成对一个或多个 Tablet 的数据访问。
SQL 层处理一个请求的执行流程是:Parser、Resolver、Transformer、Optimizer、Code Generator、Executor。
Parser 负责词法/语法解析,Parser 会将用户的 SQL 分成一个个的 “Token”,并根据预先设定好的语法规则解析整个请求,转换成语法树(Syntax Tree)。
Resolver 负责语义解析,将根据数据库元信息将 SQL 请求中的 Token 翻译成对应的对象(例如库、表、列、索引等),生成的数据结构叫做 Statement Tree。
Transformer 负责逻辑改写,根据内部的规则或代价模型,将 SQL 改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer 的工作方式是在原Statement Tree 上做等价变换,变换的结果仍然是一棵 Statement Tree。
Optimizer(优化器)为 SQL 请求生成最佳的执行计划,需要综合考虑 SQL 请求的语义、对象数据特征、对象物理分布等多方面因素,解决访问路径选择、联接顺序选择、联接算法选择、分布式计划生成等问题,最终生成执行计划。
Code Generator(代码生成器)将执行计划转换为可执行的代码,但是不做任何优化选择。
Executor(执行器)启动 SQL 的执行过程。
接入层
接入层是客户端应用接入OceanBase的一层,OceanBase数据库代理(OceanBase Database Proxy,ODP)是 OceanBase 数据库的接入层,负责将用户的请求转发到合适的 OceanBase 实例上进行处理。
ODP 是独立的进程实例,独立于 OceanBase 的数据库实例部署。ODP 监听网络端口,兼容 MySQL 网络协议,支持使用 MySQL 驱动的应用直接连接 OceanBase。
ODP 能够自动发现 OceanBase 集群的数据分布信息,对于代理的每一条 SQL 语句,会尽可能识别出语句将访问的数据,并将语句直接转发到数据所在服务器的 OceanBase 实例。
ODP 有两种部署方式,一种是部署在每一个需要访问数据库的应用服务器上,另一种是部署在与 OceanBase 相同的机器上。第一种部署方式下,应用程序直接连接部署在同一台服务器上的 obproxy,所有的请求会由 ODP 发送到合适的 OceanBase 服务器。第二种部署方式下,需要使用网络负载均衡服务将多个 ODP 聚合成同一个对应用提供服务的入口地址。
OceanBase 数据库集群由一个或多个 Region 组成,Region 由一个或多个 Zone 组成,Zone 由一个或多个 OBServer 组成,每个 OBServer 可有若干个 Unit,每个 Unit 可有若干个日志流 Logstream 的 Replica,每个 Logstream 可使用若干个 Tablet。
上面的信息量比较枯燥,下面是OceanBase的部署方案:
方案一:同城三机房三副本部署
特点:
- 同城 3 个机房组成一个集群(每个机房是一个 Zone),机房间网络延迟一般在 0.5 ~ 2 ms 之间。
- 机房级灾难时,剩余的两份副本依然是多数派,依然可以同步 RedoLog 日志,保证 RPO=0。
- 无法应对城市级的灾难。

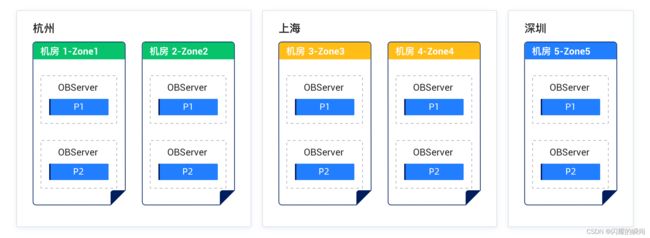
方案二:三地五中心五副本部署
特点:
- 三个城市,组成一个 5 副本的集群。
- 任何一个 IDC 或者城市的故障,依然构成多数派,可以确保 RPO=0。
- 由于 3 份以上副本才能构成多数派,但每个城市最多只有 2 份副本,为降低时延,城市 1 和城市 2 应该离得较近,以降低同步 RedoLog 的时延。
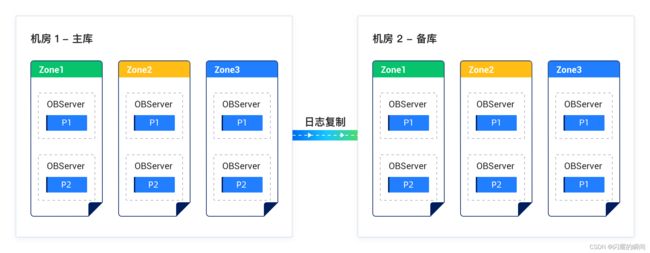
方案三:同城两机房 “主-备” 部署
特点:
- 每个机房都部署一个 OceanBase 集群,一个为主库一个为备库;每个集群有自己单独的 Paxos group,多副本一致性。
- “集群间” 通过 RedoLog 做数据同步,形式上类似传统数据库 “主从复制” 模式,从主库 “异步同步” 到备库,类似 Oracle Data Guard 中的 “最大性能” 模式。
以上内容整合了官网内容和自己的理解,仅供参考