PyTorch深度学习快速入门
本文是基于B站博主“我是土堆”发布的深度学习入门教程所编写的相关笔记,主要用于Python小白快速入门深度学习,了解PyTorch的相关理论知识及逻辑代码。不得不说,该博主的视频通俗易懂,同时配备了一套相对完整的数据集,从零基础到一步一步搭建神经网络进行模型训练,讲解得十分仔细,对于神经网络零基础的小白来说非常友好,在这里强烈安利一波:
!!!!PyTorch深度学习快速入门!!!!
!!!!PyTorch深度学习快速入门!!!!
!!!!PyTorch深度学习快速入门!!!!
目录
PyTorch数据加载
Tensorboard的使用
Transforms的使用
基础知识补充
PyTorch数据加载
在进行神经网络训练前都需要进行数据加载,而数据的加载分为两种方式:Dataset和Dataloder。
Dataset是从一堆图像数据中提取出目标数据以及对应的标签,而Dataloder是将已经提取出的目标图像进行打包并分批次训练,为后面的网络提供不同的数据形式。通过help()查看Dataset的相关介绍知道我们需要重写dataset的__getitem__和__len__部分,__getitem__是用于获取每一个数据及其标签,而__len__是得到数据集的长度,由于进行模型训练时,数据集一般会迭代多次,因此需要确保每一次迭代的图像数量与数据集的大小相等,从而进行下一次的迭代训练。
dataset具体实现流程如下:
- __init__部分需要将图像根目录及图像路径传入,有时我们也将包含图像相对路径和标签的txt文本传入,并在初始化部分用os库将两个路径进行连接防止后续路径错误,同时可返回一个列表用于getitem读取具体数据
- __init__部分的参数使用self一般定义为全局变量,用于在整个类中通用的变量(一般多个函数中的相同变量并不会互通)
- __len__一般返回数据集长度,若后续训练数据结果不符时,也可以手动设置返回值
- __getitem__需要索引下标index,通过下标查看具体的图像数据,需要返回image,label两个参数。
相关代码如下:
import os
from PIL import Image
from torch.utils.data import Dataset
class Datasets(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __len__(self):
return len(self.img_path)
def __getitem__(self, index):
img_name = self.img_path[index]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
image = Image.open(img_item_path)
label = self.label_dir
return image, label Tensorboard的使用
TensorBoard是一个可视化工具(同matplotlib),用于分析和可视化深度学习模型的训练过程和结果,显示训练过程中的损失函数和准确率变化曲线,查看模型参数的分布情况,以及观察模型在验证集上的性能指标等。
Tensorboard 中常用的两个方法分别是:add_image()和add_scalars()
add_image:用于显示训练过程任意阶段的图像数据
![]()
- tag:图像的标题
- img_tensor:图像的数据类型,可以为tensor、array、string
- global_step:训练阶段的步长,一个步长对应一个图片,若未正常显示,可加大步长查看
需要注意的是传入的图像数据其类型需为(C,H,W),C 是通道数,H 是高度,W 是宽度,若为(H,W,C)格式则要进行转换,一般来说 OpenCV 读取的图像为(H,W,C)的BGR格式,需要转换为RGB格式进行输入,而PIL读取的图像为RGB格式,直接输入即可。
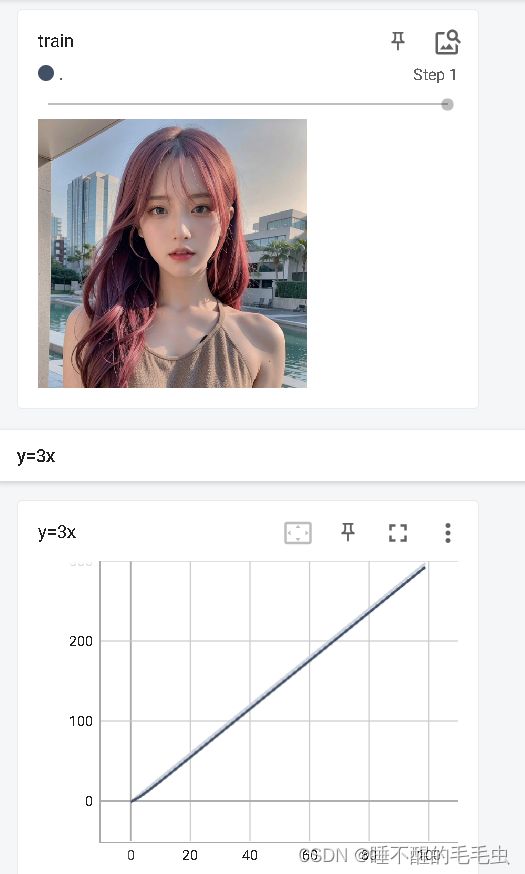
add_scalars:用于描述每一阶段相关参数的变化曲线
![]()
- main_tag:曲线的标题
- tag_scalar_dict:曲线对应的y轴
- global_step:曲线对应的x轴
实现流程如下:
- from torch.utils.tensorboard import SummaryWriter 在pycharm输入该命令行导入模块包,若遇到 module error 可在终端或虚拟环境输入conda install tensorboard 或 pip install tensorboard 进行安装
- 使用SummaryWriter()创建实例,一般可选择是否传入参数,若没有传入,该类会默认文件名为logs,若传入则文件名为传入参数,同时正确读取图像,传入函数运行,最后需要将打开的可视化图关闭
- 运行结束后会在你的目录下生成对应的文件名,然后在pycharm打开终端或虚拟环境,输入tensorboard --logdir=logs生成对应网页链接,点击即可跳转
相关代码如下:
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
path = r'D:\Anaconda3\PYTORCH_\OpenCV\opencv-beginner-master\source\AI.png'
writer = SummaryWriter('Images')
img_PIL = Image.open(path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("train", img_array, 1, dataformats='HWC')
for i in range(100):
writer.add_scalar("y=3x", 3 * i, i)
writer.close()
运行结果:
终端:一般在终端输入 tensorboard --logdir=logs 或改变端口均可以正常跳转,若仍无法正常显示,可以使用文件夹的绝对路径进行指示

Tensorboard:网页显示结果
Transforms的使用
Transforms是指在计算机视觉中对图像进行预处理或后处理的技术。它们用于对图像进行变换、裁剪、旋转、缩放、翻转等操作,以改变图像的外观或几何属性。Transforms在深度学习中被广泛应用,特别是在数据增强和数据预处理方面,以提高模型的性能和鲁棒性。
常见的transforms方法包括:
- Resize: 调整图像尺寸。
- Compose:组合变换
- CenterCrop: 对图像进行中心裁剪。
- RandomCrop: 对图像进行随机裁剪。
- Normalize: 对图像进行归一化。
- ToTensor: 将图像转换为Tensor类型。
通过使用transforms模块,可以方便地对图像进行预处理,从而更好地适应深度学习模型的需求。
如果要具体的查看transforms的内部模块,可用Ctrl+点击鼠标左键进入.py文件。其文件是由多个类编写联合而成,包含各类图像变换的参数传递、使用方法等,请注意各类函数传递的图像数据类型可能不一致,可能为 PIL.Image 或 ndarray 类型,具体使用方法请自行查阅。
transforms实现流程如下:
- 由于transforms是由多个类集合而成,故需要进行实例化并传递相关参数
- 读取图像直接传入后,transforms会自动调用各类里面的__call__方法对图像进行处理
相关代码如下:
transform = transforms.Compose([
transforms.CenterCrop((500,300)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
])
img=Image.open(r"D:\Anaconda3\Pytorch\data\image\002.jpg")
transform_img=transform(img)
image=transforms.ToPILImage()(transform_img)
image.show()该代码是在Compose里面实现了图像的中心裁剪和随机翻转后转换为张量,最后将张量转换为PIL.Image类型的图像进行输出显示。
基础知识补充
本部分是对类的一些内置方法说明:
- __init__.py的用法
__init__.py是实现工程模块化的基础。工程模块化是指将具有一定共性的功能函数封装在一个模块方便调用。在模块中,__init__.py控制着模块内所有包的导入行为,简单来说就是,没有__init__.py就无法导入包。以下为不同的导入方式:这里以ImageDeal模块,imagedeal类,Flip_image函数为例:

- __str__.py的用法
__str__.py在类中用于打印该类的说明,即return的返回值。需要注意的是该返回值必须是字符串,且不允许有输入参数。
- __call__.py的用法
__call__.py是指在创建实例对象后,调用类中的函数时若未明确指明调用的函数名则会自动调用__call__.py函数。简单说就是没指明函数名时把实例对象当做参数传入__call__.py函数使用。
- self的作用
在python构造方法和实例方法中至少要包含一个参数,默认为self。在一个类中可以有多个方法,当有某个对象调用类方法时,该对象会把自身的引用作为第一个参数自动传递给该方法。换句话说就是定义全局变量。