用通俗易懂的方式讲解:大模型微调方法总结
大家好,今天给大家分享大模型微调方法:LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning。
文末有大模型一系列文章及技术交流方式,传统美德不要忘了,喜欢本文记得收藏、关注、点赞。
文章目录
-
-
- 1、LoRA
- 2、Adapter
- 3、Prefix-tuning
- 4、P-tuning
- 5、prompt-tuning
- 用通俗易懂的方式讲解系列
- 技术交流
- 参考资料
-
1、LoRA
paper:LoRA: Low-Rank Adaptation of Large Language Models(https://arxiv.org/pdf/2106.09685.pdf)
code:[GitHub - microsoft/LoRA: Code for loralib, an implementation of “LoRA: Low-Rank Adaptation of Large Language Models”](https://github.com/microsoft/LoRA “GitHub - microsoft/LoRA: Code for loralib, an implementation of “LoRA: Low-Rank Adaptation of Large Language Models””)
简介
自然语言处理目前存在一个重要范式:一般领域数据的大规模预训练,对特定任务或领域的适应(finetune)。
但是随着预训练语言模型越来越大,这个范式存在以下问题:
● 当我们 finetune 大模型时,由于训练成本太高,不太可能重新训练所有模型参数
● 以前的方法(论文发表于 2021 年)都或多或少有其它性能问题,如 adapter 增加了模型层数,引入了额外的推理延迟;prefix-tuning 比较难训练,效果不如直接 finetune。
基于上述背景,论文作者得益于前人的一些关于内在维度(intrinsic dimension)的发现:模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。假设模型在任务适配过程中权重的改变量是低秩(low rank)的,由此提出低秩自适应(LoRA)方法,LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
方法
LoRA 的实现思想很简单,如下图所示,就是冻结一个预训练模型的矩阵参数,并选择用 A 和 B 矩阵来替代,在下游任务时只更新 A 和 B。

结合图片来看,LoRA 的实现流程如下:
● 在原始预训练语言模型(PLM)旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的内在秩。
● 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B。
● 模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
● 用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵。
实现
接下来我们从公式上解释 LoRA 的实现。
假设要在下游任务微调一个预训练语言模型(如 GPT3),则需要更新预训练模型参数,公式表示如下:
W0 是预训练模型初始化的参数,ΔW 就是需要更新的参数。如果是全参数微调,则它的参数量=W0 参数量(如果是 GPT3,则 ΔW≈175B)。从这可以看出要全参数微调大语言模型,小家小户是不可能的。
由于前人的工作发现预训练的语言模型具有较低的“内部维度(intrinsic dimension)”,在任务适配过程中,即使随机投影到较小的子空间,仍然可以有效地学习。因此,LoRA 做的就是增加小参数模块去学习改变量 ΔW。

在训练过程中,W0 是固定不变的,只有 A 和 B 包含训练参数,是变化的。
而在推理的过程中,只需要把改变量放回原模型,就不会有任何延迟。
如果想切换任务,只需要切换任务的过程中,减去 BA,然后换上用其它任务训练好的 BʹAʹ 就可以了。
总结
总的来说,基于大模型的内在低秩特性,增加旁路矩阵来模拟 full finetuning,LoRA 是一个能达成 lightweight finetuning 的简单有效的方案。目前该技术已经广泛应用于大模型的微调,如 Alpaca,stable diffusion+LoRA,而且能和其它参数高效微调方法有效结合,例如 State-of-the-art Parameter-Efficient Fine-Tuning (PEFT)
2、Adapter
paper: Parameter-Efficient Transfer Learning for NLP (https://arxiv.org/pdf/1902.00751.pdf)
MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer(https://arxiv.org/pdf/2005.00052.pdf)
简介
2019 年,Houlsby N 等人将 Adapter 引入 NLP 领域,作为全模型微调的一种替代方案。Adapter 主体架构下图所示。

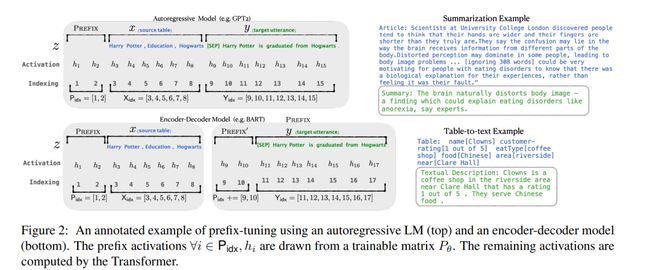
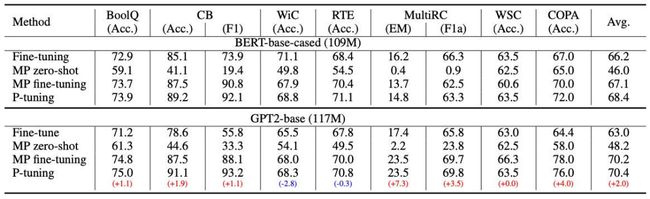
在预训练模型每一层(或某些层)中添加 Adapter 模块(如上图左侧结构所示),微调时冻结预训练模型主体,由 Adapter 模块学习特定下游任务的知识。每个 Adapter 模块由两个前馈子层组成,第一个前馈子层将 Transformer 块的输出作为输入,将原始输入维度 d 投影到 m,通过控制 m 的大小来限制 Adapter 模块的参数量,通常情况下 m< Adapter 算法改进 2020 年,Pfeiffer J 等人对 Adapter 进行改进,「提出 AdapterFusion 算法,用以实现多个 Adapter 模块间的最大化任务迁移」(其模型结构如下图所示)。 AdapterFusion 将学习过程分为两个阶段: ● 1.「知识提取阶段」:训练 Adapter 模块学习下游任务的特定知识,将知识封装在 Adapter 模块参数中。 ● 2.「知识组合阶段」:将预训练模型参数与特定于任务的 Adapter 参数固定,引入新参数学习组合多个 Adapter 中的知识,提高模型在目标任务中的表现。 其中首先,对于 N 的不同的下游任务训练 N 个 Adapter 模块。然后使用 AdapterFusion 组合 N 个适配器中的知识,将预训练参数 Θ 和全部的 Adapter 参数 Φ 固定,引入新的参数 Ψ,使用 N 个下游任务的数据集训练,让 AdapterFusion 学习如何组合 N 个适配器解决特定任务。参数 Ψ 在每一层中包含 Key、Value 和 Query(上图右侧架构所示)。 在 Transformer 每一层中将前馈网络子层的输出作为 Query,Value 和 Key 的输入是各自适配器的输出,将 Query 和 Key 做点积传入 SoftMax 函数中,根据上下文学习对适配器进行加权。在给定的上下文中,AdapterFusion 学习经过训练的适配器的参数混合,根据给定的输入识别和激活最有用的适配器。「作者通过将适配器的训练分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题。Adapter 模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能」。 Adapter Fusion 在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。作者对全模型微调(Full)、Adapter、AdapterFusion 三种方法在各个数据集上进行和对比试验。AdapterFusion 在大多数情况下性能优于全模型微调和 Adapter,特别在 MRPC(相似性和释义任务数据集)与 RTE(识别文本蕴含数据集)中性能显著优于另外两种方法。 paper:Prefix-Tuning: Optimizing Continuous Prompts for Generation(https://arxiv.org/pdf/2101.00190.pdf) code:GitHub - XiangLi1999/PrefixTuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation[1] 简介 前缀微调(prefix-tunning),用于生成任务的轻量微调。前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的 token 不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型 Transformer 和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。 方法 本文考虑两个生成任务:table-to-text 和摘要任务。 对于 table-to-text 任务,本文使用自回归语言模型 GPT-2,输入为 source( x )和 target( y )的拼接,模型自回归地生成: 对于摘要任务,本文使用 BART 模型,编码器输入 source 文本 x ,解码器输入 target 黄金摘要( y ),模型预测摘要文本: 实现 在传统微调方法中,模型使用预训练参数进行初始化,然后用对数似然函数进行参数更新。 关于前缀/提示的设计,我们可以给模型若干的字词作为提示,比如我们想让模型生成“Obama”,那我们可以在其常见的搭配前加上上下文(例如,Barack),那么 LM 就会把更高的可能性分配给想要的单词。但是对于很多生成任务来说,找到合适的离散的前缀进行优化是非常困难的,尽管它的效果是不错的。因此本文将指令优化为连续的单词嵌入,而不是通过离散的 token 进行优化,其效果将向上传播到所有 Transformer 激活层,并向右传播到后续的 token。严格来说,这比离散提示符更具表达性,后者需要匹配嵌入的真实单词。对于自回归模型,加入前缀后的模型输入表示: 对于编解码器结构的模型,加入前缀后的模型输入表示: 本文构造一个矩阵 去存储前缀参数,该前缀是自由参数。 目标函数依旧是公式(2),但是语言模型的参数是固定的,只更新前缀参数。 除此之外,作者发现直接更新前缀参数会出现不稳定的情况,甚至模型表现还有轻微的下降,因此作者对前缀参数矩阵进行重参数化: 其中: paper:[2103.10385\] GPT Understands, Too[2] code:[GitHub - THUDM/P-tuning: A novel method to tune language models. Codes and datasets for paper P-tuning 是稍晚些的工作,主要针对 NLU 任务。对于 BERT 类双向语言模型采用模版(P1, x, P2, [MASK], P3),对于单向语言模型采用(P1, x, P2, [MASK]): 同时加了两个改动: 1、考虑到预训练模型本身的 embedding 就比较离散了(随机初始化+梯度传回来小,最后只是小范围优化),同时 prompt 本身也是互相关联的,所以作者先用 LSTM 对 prompt 进行编码; 2、在输入上加入了 anchor,比如对于 RTE 任务,加上一个问号变成[PRE][prompt tokens][HYP]?[prompt tokens][mask]后效果会更好; p-tuning 的效果很好,之前的 Prompt 模型都是主打小样本效果,而 P-tuning 终于在整个数据集上超越了精调的效果: Prompt-tuning 给每个任务定义了自己的 Prompt,拼接到数据上作为输入,同时 freeze 预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果: 同时,Prompt-tuning 还提出了 Prompt-ensembling,也就是在一个 batch 里同时训练同一个任务的不同 prompt,这样相当于训练了不同「模型」,比模型集成的成本小多了。 技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。 建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。 方式①、微信搜索公众号:机器学习社区,后台回复:技术交流 [1]GitHub - XiangLi1999/PrefixTuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation: https://github.com/XiangLi1999/PrefixTuning [2][2103.10385] GPT Understands, Too: https://arxiv.org/abs/2103.10385
3、Prefix-tuning

![]()

![]()
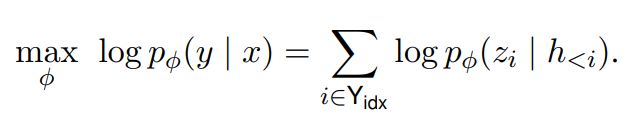
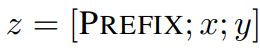
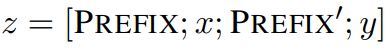
![]()
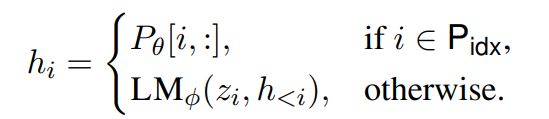
![]()
![]() 在第二维的维数要比
在第二维的维数要比 ![]() 小,然后经过一个扩大维数的 MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留
小,然后经过一个扩大维数的 MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留![]() 。
。4、P-tuning
GPT understands, too''.](https://github.com/THUDM/P-tuning "GitHub - THUDM/P-tuning: A novel method to tune language models. Codes and datasets for paper GPT understands, too’'.")
5、prompt-tuning

用通俗易懂的方式讲解系列
技术交流
方式②、添加微信号:mlc2060,备注:技术交流
参考资料