qsort排序&qsort排序模拟实现
摘要:qsort—>quickly sort,即快速排序。qsort是属于c语言标准库的一个库函数,可以实现所有类型的排序。本文的qsort模拟排序不是基于快速排序,而是基于冒泡排序思想。
1.qsort排序的使用
先了解什么是qsort库函数,以下给出网站cplusplus网站的解释:
https://cplusplus.com/reference/cstdlib/qsort/?kw=qsort
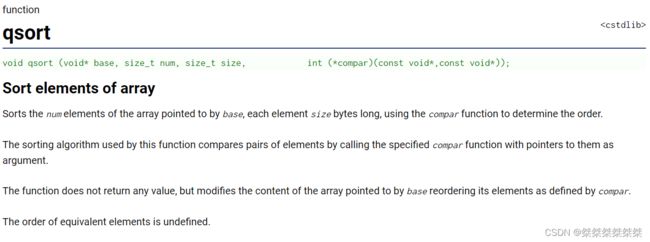
由上可得,qsort传入的参数类型为:
void qsort(
void* base,
size_t num,
size_t size,
int (*compar)(const void* p1,const void* p2)
)由传入的参数可知,我们需要传入四个参数,其中分别为:
void* base:待排序的数组的起始位置(因为不知道传入需要排序的参数为什么,所以定义为void);
size_t num:待排序的数组的元素个数;
size_t size:待排序的数组的元素大小;
int (*compar)(const void* p1,const void* p2):一个函数指针,指向的函数是用来比较待排序的两个元素的,p1指向第一个元素,p2指向第二个元素。
先给出一个qsort的排序实例:
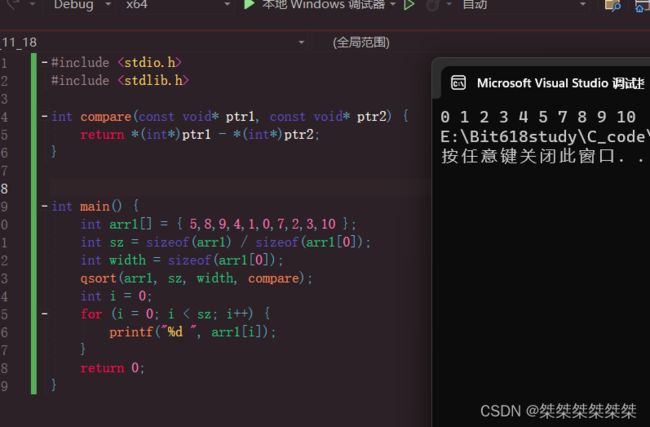
通过以上例子,我们成功将乱序的数组,排序成为升序的数组(若要排成降序,可以将compare内的返回值中相减的顺序调换),由上图可得,我们将数组首地址(待排序数组起始位置)传入qsort中,还有元素个数,以及一个元素的大小,还有compare函数。
对于前三个参数没什么难度,关键是compare函数,为什么需要将第一个值减去第二个值返回呢?因为在qsort内部,需要知道,哪个数更大,qsort将更大的数排在后面(相对而言,交换位置,则排序方式也相反)。那么关于compare函数怎么使用呢?因为compare函数是由我们自己设定,所以需要我们自己返回我们想要排序的相关元素类型的相减的值,如上图,我们需要排序的数组的元素类型为 int ,所以将void*的元素类型,强制转换为int*的元素类型在解引用,但如果我们想排序其他类型的元素呢?以下给出一些实例:
#include
#include
#include
typedef struct Stu {
char name[20];
int age;
int ID;
}stu;
void Print(stu* students,int sz) {
int i = 0;
for (i = 0; i < sz; i++) {
printf("%s %d %d\n", students[i].name, students[i].age, students[i].ID);
}
}
int compare_by_name(const void* ptr1, const void* ptr2) {
int ret = strcmp((*(stu*)ptr1).name , (*(stu*)ptr2).name);
return ret;
}
int compare_by_age(const void* ptr1, const void* ptr2) {
return (*(stu*)ptr1).age - (*(stu*)ptr2).age;
}
int main() {
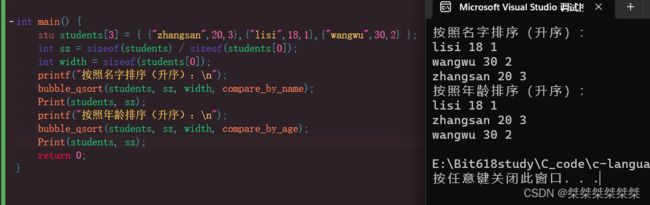
stu students[3] = { {"zhangsan",20,3},{"lisi",18,1},{"wangwu",30,2} };
int sz = sizeof(students) / sizeof(students[0]);
int width = sizeof(students[0]);
printf("按照名字排序(升序):\n");
qsort(students, sz, width, compare_by_name);
Print(students, sz);
printf("按照年龄排序(升序):\n");
qsort(students, sz, width, compare_by_age);
Print(students, sz);
return 0;
}
以上所写代码,包括按照结构体中字符型进行排序,同样也包括按照结构体中整型进行排序,以下是调试结果:
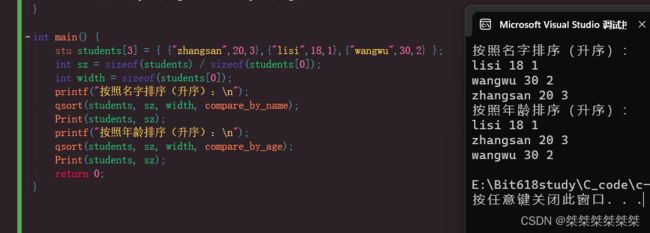
对于其中的按照年排序,我们直接返回他们相减的值就可以了,但是对于字符串类型的排序,我们就不可以直接加减,因为字符串之间是不可以进行加减的。所以这时候我们需要引入另一个库函数 strcmp 这个库函数可以比较两个字符串之间的大小(不是比较字符串长度),通过比较每一位上的元素的ascII码值,比如abcdef 与 abcdd,在前四位都是一样的,但是在第五位e的ASCII码值大于d,所以返回的值大于0,若小于,返回的值小于0,等于则返回0,这和我们qsort函数所需值一样,只需要大于,小于,等于0即可。
2.qsort的模拟实现
接下来将实现qsort基于冒泡排序的实现,所以我们是在冒泡排序的基础上修改。以下是冒泡排序算法(因不是重点,就不解释冒泡排序了):
//冒泡排序
void bubble_sort(int* arr, int length) {
int i = 0;
for (i = 0; i < length-1; i++) {
int j = 0;
for (j = 0; j < length - 1 - i; j++) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}先给出基于冒泡排序算法的qsort排序 :
void swap(char* p1, char* p2,size_t width) {
int i = 0;
for (i = 0; i < width; i++) {
char temp = *p1;
*p1 = *p2;
*p2 = temp;
p1++;
p2++;
}
}
void bubble_qsort(void* base, size_t length, size_t width, int (*compare)(const void* p1, const void* p2)) {
int i = 0;
for (i = 0; i < length - 1; i++) {
int j = 0;
for (j = 0; j < length - i - 1; j++) {
if (compare((char*)base + j * width, (char*)base + (j + 1) * width) > 0) {
swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}对于以上函数,思想和冒泡排序一致,不过改变的是冒泡排序传入的参数以及交换值的方式。现在我们来对代码进行解释。
对于冒泡qsort函数,我们传入需要排序数组的首地址,数组长度,元素大小和比较函数。在长度和元素大小便利我们将每一个值都进行遍历,然而compare函数便于我们得出第一个元素大还是第二个元素。但是在传入compare函数中的参数值时,我们需要将base强制类型转换为char*,因为char*的地址大小为一个字节,当char*的地址,加上一个元素的宽度的时候,其实就是跳过这个元素地址,这样可以达到:不管是什么样的元素,我们都可以进行遍历。
对于swap函数,我们将上述compare传入参数同样传入swap中去,直接在swap传入参数的地方就将元素类型给强制转换为char*类型,便于我们实现一个字节一个字节的交换值,既然是交换元素大小,所我们需要传入元素的大小,然后进行循环遍历。
以下是程序调试结果: