【NL】《Non-local Neural Networks》

CVPR-2018
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Non-local Neural Networks
-
- 4.1 Formulation
- 4.2 Instantiations
- 4.3 Non local Block
- 4.4 Video Classification Models
- 5 Experiments
-
- 5.1 Datasets
- 5.2 Experiments on Kinetics (Video Classification)
- 5.3 Experiments on Charades
- 5.4 Experiments on COCO
- 6 Conclusion(own)
1 Background and Motivation
Both convolutional and recurrent operations(eg:CNN 和 RNN) are building blocks that process one local neighborhood at a time(一次操作仅对局部信息进行了加工).
虽然 repeating local operations (eg:CNN 和 RNN)就可以 capturing long-range dependencies(get 到全局信息)
但 repeating local operations has several limitations
1)computationally inefficient
2)optimization difficulties
3)make multi-hop dependency modeling difficult——when messages need to be delivered back and forth between distant positions(跨空域交流困难)
本文借鉴 non-local means 传统图像处理方法,在深度神经网络网络中提出了可 capturing long-range dependencies(利用全局信息) 的 non-local 模块,即插即用,在 video classification、object detection、segmentation、pose estimation 任务中提升明显!

non-local 的好处
1)capture long-range dependencies directly by computing interactions between any two positions, regardless of their positional distance
2)efficient and achieve their best results even with only a few layers(仅用几个 non-local 模块效果就很好)
3)maintain the variable input sizes and can be easily combined with other operations(tensor 怎么进怎么出,即插即用)
2 Related Work
- Non-local image processing
- Graphical models
- Feedforward modeling for sequences
- Self-attention
- Interaction networks
- Video classification architectures
3 Advantages / Contributions
-
在 Neural Networks 上提出 non-local operation,即插即用
-
Non-local Neural Networks 在 Kinetics and Charades 数据集上 SOTA,COCO 数据中的 object detection, segmentation and pose estimation 任务上,均有明显提升
4 Non-local Neural Networks
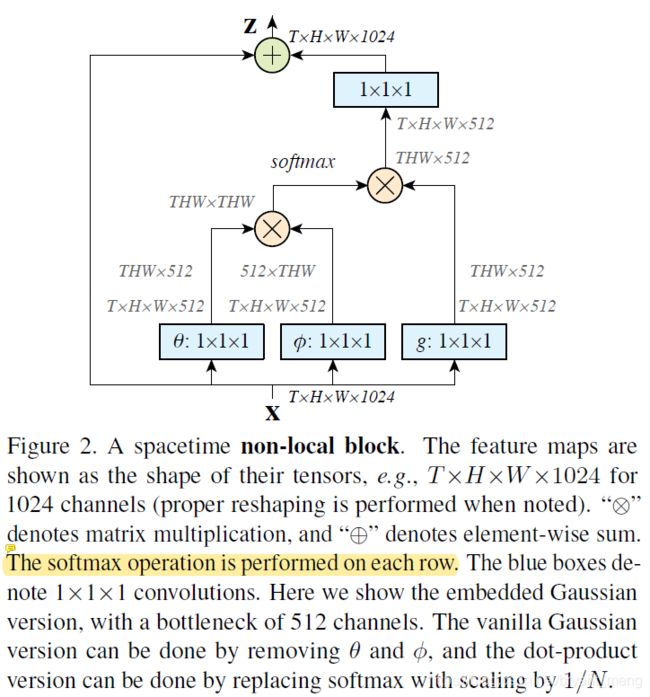
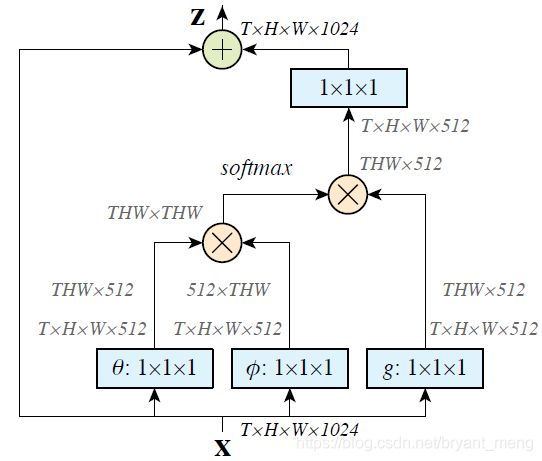
4.1 Formulation

- i i i 是 output position(space,time or spacetime)
- j j j is the index that enumerates all possible positions
- x x x is the input signal (image, sequence, video; often their features)
- y y y is the output signal of the same size as x x x
- f f f is pairwise function computes a scalar (representing relationship) between i i i and all j j j
- g g g is the unary function(一元函数就是只有一个未知量)
- c ( x ) c(x) c(x) 正则化因子
non-local 和 one-local 的本质区别
- 在 ∑ \sum ∑ 的范围上,一个是 ∀ j \forall j ∀j,一个是 eg i − 1 ≤ j ≤ i + 1 i − 1 ≤ j ≤ i + 1 i−1≤j≤i+1 的 8 邻域)
non-local 和 fully connection(fc) 的区别
- the relationship between x j x_j xj and x i x_i xi is not a function of the input data in fc
- non-local supports inputs of variable sizes, 输出和输入的大小相同,而 fc 要求固定的输入输出,且 fc 操作会 loses positional correspondence
4.2 Instantiations
作者把 g g g 函数设计为一个 linear embedding
g ( x j ) = W g x j g(x_j) = W_gx_j g(xj)=Wgxj
W g W_g Wg 是权重,eg:1x1 in space,1x1x1 in spacetime
f f f 函数作者尝试了如下 4 种形式:
1)Gaussian

![]()
2)Embedded Gaussian
compute similarity( x i x_i xi 和 x j x_j xj 之间的) in an embedding space

![]()
![]()
![]()
注意到, 1 C ( x ) f ( x i , x j ) \frac{1}{C(x)}f(x_i,x_j) C(x)1f(xi,xj) 的形式是 the softmax computation along the dimension j j j
![]()
哈哈哈,Embedded Gaussian 这种实例和机器翻译种的 self-attention 如出一辙
关于 attention 的介绍可以参考 【MoCo】《Momentum Contrast for Unsupervised Visual Representation Learning》

We note that the self-attention module recently presented for machine translation is a special case of non-local operations in the embedded Gaussian version.
As such, our work provides insight by relating this recent self-attention model to the classic computer vision method of non-local means, and extends the sequential self-attention network in to a generic space/spacetime non-local network for image/video recognition in computer vision.
3)Dot product

![]()
- N N N is the number of positions in x x x,这样的设定和 ∑ f \sum f ∑f 相比,it simplifies gradient computation
4)Concatenation

![]()
- [ ⋅ , ⋅ ] [·, ·] [⋅,⋅] denotes concatenation

non local models are not sensitive to these choices, indicating that the generic non-local behavior is the main reason for the observed improvements.
也即,non local 的 formulation y i = 1 C ( x ) ∑ ∀ j f ( x i , x j ) g ( x j ) y_i = \frac{1}{C(x)}\sum_{\forall_j} f(x_i,x_j)g(x_j) yi=C(x)1∑∀jf(xi,xj)g(xj) 才是本质,对 instantiations(各种 C C C, f f f) 没那么敏感
4.3 Non local Block
![]()
配合了一个 residual connection
仅在 W z W_z Wz 卷之后,加了一个 BN,BN 的 α \alpha α, β \beta β 参数初始化为 0,保证一开始仅 identity
关于 BN 的原理介绍可以参考 【BN】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
non local block 采用了如下两种压缩参数量的形式
- 通道数: ϕ \phi ϕ 和 θ \theta θ 把通道数砍半了,通过 W z W_z Wz 作用到 x i x_i xi 上还原回来
- 分辨率: y i = 1 C ( x ^ ) ∑ ∀ j f ( x ^ i , x ^ j ) g ( x ^ j ) y_i = \frac{1}{C(\hat{x})}\sum_{\forall_j} f(\hat{x}_i,\hat{x}_j)g(\hat{x}_j) yi=C(x^)1∑∀jf(x^i,x^j)g(x^j), x ^ \hat{x} x^ 是 x x x max pooling 后的结果,作用在 ϕ \phi ϕ 和 θ \theta θ 操作之后
non local 的实现(参考 视觉注意力机制 | Non-local模块与Self-attention的之间的关系与区别?)
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
"""
调用过程
NONLocalBlock2D(in_channels=32),
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
"""
def __init__(self,
in_channels,
inter_channels=None,
dimension=3,
sub_sample=True,
bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
# 进行压缩得到channel个数
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0), bn(self.in_channels))
nn.init.constant_(self.W[1].weight, 0) # 初始化为 0
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
self.phi = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x):
'''
:param x: (bs, c, h, w)
:return:
'''
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1) # [bs, c_i, w*h]
g_x = g_x.permute(0, 2, 1) # [bs, w*h, c_i]
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1) # [bs, c_i, w*h]
theta_x = theta_x.permute(0, 2, 1) # [bs, w*h, c_i]
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1) # [bs, c_i, w*h]
f = torch.matmul(theta_x, phi_x) # [bs, w*h, w*h]
print(f.shape)
f_div_C = F.softmax(f, dim=-1) # The softmax operation is performed on each row
y = torch.matmul(f_div_C, g_x) # [bs, w*h, c_i]
y = y.permute(0, 2, 1).contiguous() # [bs, c_i, w*h]
y = y.view(batch_size, self.inter_channels, *x.size()[2:]) # [bs, c_i, w, h]
W_y = self.W(y) # [bs, c, w, h]
z = W_y + x # w_y 的参数被初始化为了 0
return z
对比下 self-attention 的代码
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1)) # learnable 的缩放因子
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X N X C//8
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C//8 x N
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) ) # 别扭,哈哈,attention 被甩到后面去了,感觉可以 attention, proj_value.permute(0,2,1)
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x # 这个缩放因子还是蛮不错的,non local 中对应的是 W_y
return out,attention
核心部分大同小异
补充知识:
PyTorch里面的torch.nn.Parameter()
torch.bmm() 与 torch.matmul() 3 维情况下一样,batch-size 不变,后两维度二维矩阵乘
pytorch 中 tf.nn.functional.softmax(x,dim = -1) 对参数 dim 的理解

4.4 Video Classification Models
略,
哈哈哈,这部分理解没那么深刻,就不小节了
2D ConvNet baseline (C2D)
Inflated 3D ConvNet (I3D):t×k×k kernel is initialized by the pre-trained k×k weights, rescaled by 1/t.
5 Experiments
5.1 Datasets
-
Kinetics :~246k training videos and 20k validation videos.

-
Charades
-
COCO
5.2 Experiments on Kinetics (Video Classification)
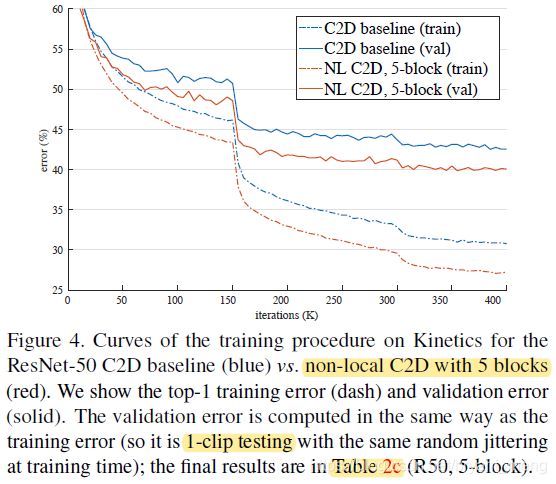
Our network can learn to find meaningful relational clues regardless of the distance in space and time.
1)Instantiations

论文中默认采用的是 Gaussian,embed 的 non local block instantiations
2)Which stage to add non-local blocks?
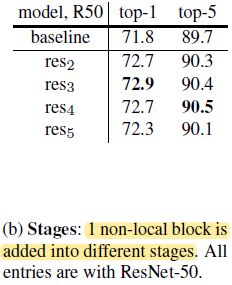
相对来说,non local block 加在 res5 中效果差一些,可能是 insufficient to provide precise spatial information
3)Going deeper with non-local blocks
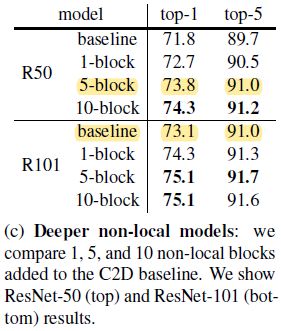
ResNet 50 加了 5 个 non local block 后效果比 ResNet 101 不加 non local block 还好,说明 the improvement of non-local blocks is not just because they add depth
4)Non-local in spacetime

5)Non-local net vs. 3D ConvNet

2D + non local 比 3D 猛
6)Non-local 3D ConvNet
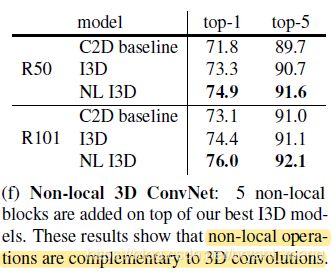
non local 加在 3D 上还有提升
7)Longer sequences

在 f 实验的基础上,把 clips 由 32 frame(64 frames, dropping every other frame) 增加到了 128 frame
work well on longer sequences
8)Comparisons with state-of-the-art results

猛
5.3 Experiments on Charades
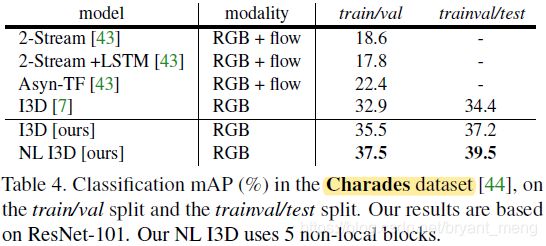
5.4 Experiments on COCO
1)Object detection and instance segmentation
adding one non-local block (right before the last residual block of res4)

加一个 non local block 提升就这么明显,是真的猛
2)Key-point detection
Mask R-CNN used a stack of 8 convolutional layers for predicting the keypoints as 1-hot masks
we insert 4 non-local blocks into the keypoint head (after every 2 convolutional layers)

6 Conclusion(own)
-
our work bridges self-attention for machine translation to the more general class of non-local filtering operations that are applicable to image and video problems in computer vision.
-
multiple non-local blocks can perform long-range multi-hop communication
-
scale jittering

-
non local 的缺点(来自 视觉注意力机制 | Non-local模块与Self-attention的之间的关系与区别?)
1)只涉及到了位置注意力模块,而没有涉及常用的通道注意力机制
2)可以看出如果特征图较大,那么两个 (batch,hxw,512)矩阵乘是非常耗内存和计算量的,也就是说当输入特征图很大存在效率低下问题,虽然有其他办法解决例如缩放尺度,但是这样会损失信息,不是最佳处理办法。 -
来自 如何评价 Kaiming He 最新的 Non-local Neural Networks?

-
non-local Means(非局部均值)降噪算法及快速算法原理与实现
非局部均值滤波由Baudes提出,其出发点应该是借鉴了越多幅图像加权的效果越好的现象,那么在同一幅图像中对具有相同性质的区域进行分类并加权平均得到去噪后的图片,应该降噪效果也会越好。该算法使用自然图像中普遍存在的冗余信息来去噪声。与双线性滤波、中值滤波等利用图像局部信息来滤波不同,它利用了整幅图像进行去噪。即以图像块为单位在图像中寻找相似区域,再对这些区域取平均,较好地滤除图像中的高斯噪声。NL-Means的滤波过程可以用下面公式来表示
