Python爬虫(三)——破解验证码登录
有些网站登录需要验证码,我们可以讲验证码图片进行下载,进行人工肉眼识别或者第三方自动识别。
例如,我们爬取古诗文网,先进行手动登录
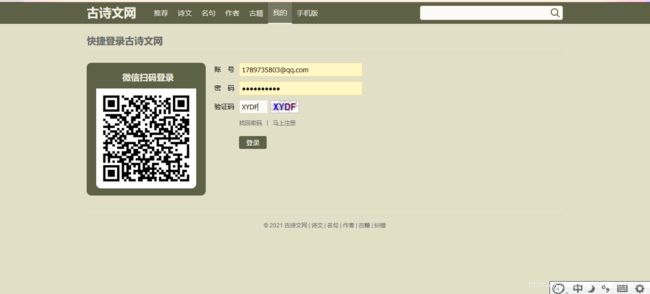
登录之后,在开发者工具上可以得到登录请求,请求参数就有账号密码以及验证码。
 因此,我们可以获得验证码图片,然后将验证码信息作为参数获得请求。
因此,我们可以获得验证码图片,然后将验证码信息作为参数获得请求。
import requests
from lxml import etree
url='https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0"
}
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
src=tree.xpath('//img[@id="imgCode"]/@src')[0]
img_url="https://so.gushiwen.cn"+src
img_text=requests.get(img_url,headers).content
with open("验证码.gif",'wb') as fp:
fp.write(img_text)
code=input()
data={
"VIEWSTATE":"boAsfIdvbpNAx56DO0y1R+NfWzdXFR3f+uhuCdxgt8d5T1lgcAEUTUhS8rH/a1bIG+BznT4mygyoMksB5No+JhznCFuNR48i4Dq3/qT9Gv4LVX7XxGCGpgo1fpQ=",
"VIEWSTATEGENERATOR":"C93BE1AE",
"from":"http://so.gushiwen.cn/user/collect.aspx",
"email":"[email protected]",
"pwd":"1789735803",
"code":code,
"denglu":"登录"
}
login_url='http://so.gushiwen.cn/user/collect.aspx'
login_text=requests.get(url=login_url,headers=headers,data=data).text
with open('古诗文网.html','w',encoding='utf-8') as fp:
fp.write(login_text)

手动输入验证码即可(或者用第三方工具、pytesseract进行自动识别),然后就可以获得登录后的数据了。