Qt使用xlnt操作Excel(二):导入Excel
这篇讲如何使用xlnt导入excel,虽然xlnt比Qt自带的ActiveQt库操作更简单,但是使用过程中还是存在一些bug。我当前用的分支是8f39375,导入时有个bug会导致有些情况下编写的Excel文件导入时会报错,不知道官方后面会不会修复,现在我们来重现这个bug并做一个临时的处理办法。
继续用上一篇配置好的XlntTest工程,首先设置源代码路径,这样可以单步调试进源代码

1.读取excel代码
在工程目录下新建2个xlsx文件,1.xlsx和2.xlsx
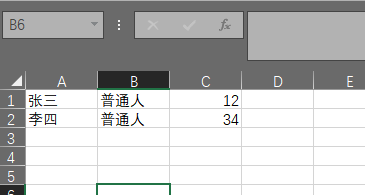
这里1和2中的内容完全相同,但编辑方式不一样,1.xlsx中B1和B2都用键盘手敲,在2.xlsx中B2从B1直接复制粘贴过来
接下来编写导入的代码,新建一个类叫ExcelTool
//ExcelTool.h
#pragma once
#include 2.复现bug
当读取2.xlsx时没有问题

当读取1.xlsx时会在load出报错
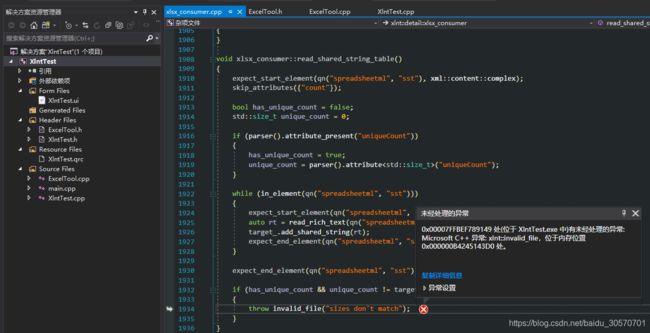
这里错误指向了源代码的xlsx_consumer.cpp中1934行,抛出了一个invalid_file的错误,原因是sizes don’t match,接下来我们分析为什么会抛出这个异常。
3.源代码分析
打开之前编译的xlnt_all工程,找到detail/serialization/xlsx_consumer.cpp,代码里面很明显,是unique_count != target_.shared_strings().size()不成立,unique_count是1919行读取的一个属性叫uniqueCount的值,那这个属性定义在哪里呢
这里先提一下Excel的组成,Excel的编写是Office Open XML标记语言编写的,其实就是office自己定的一些xml约束,本质还是xml,这是官方的部分说明,也就是说,整个Excel文件就是一堆xml打包而成,接下来我们对1.xlsx和2.xlsx进行拆包,最简单的办法就是将1.xlsx后缀直接改成zip,对1.zip解压就能看到所有的xml,里面的文件结构这里就不多说,关键的文件是xl/sharedStrings.xml这个文件,下面是两个文件中sharedStrings.xml文件内容
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="4" uniqueCount="4">
<si>
<t>张三t>
<phoneticPr fontId="1" type="noConversion"/>
si>
<si>
<t>李四t>
<phoneticPr fontId="1" type="noConversion"/>
si>
<si>
<t>普通人t>
<phoneticPr fontId="1" type="noConversion"/>
si>
<si>
<t>普通人t>
<phoneticPr fontId="1" type="noConversion"/>
si>
sst>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="4" uniqueCount="3">
<si>
<t>张三t>
<phoneticPr fontId="1" type="noConversion"/>
si>
<si>
<t>李四t>
<phoneticPr fontId="1" type="noConversion"/>
si>
<si>
<t>普通人t>
<phoneticPr fontId="1" type="noConversion"/>
si>
sst>
这里找到了uniqueCount这个属性,1.xlsx值为4,2.xlsx值为3,而且1.xlsx中出现了重复的标签xlsx_consumer::read_shared_string_table很明显是对sharedStrings.xml内容的读取。unique_count找到了,再看target_.shared_strings变量为什么size不是4,代码里面很明显,1925行和1926行就是对
std::size_t workbook::add_shared_string(const rich_text &shared, bool allow_duplicates)
{
register_workbook_part(relationship_type::shared_string_table);
if (!allow_duplicates)
{
auto it = d_->shared_strings_ids_.find(shared);
if (it != d_->shared_strings_ids_.end())
{
return it->second;
}
}
auto sz = d_->shared_strings_ids_.size();
d_->shared_strings_ids_[shared] = sz;
d_->shared_strings_values_[sz] = shared;
return sz;
}
可以看到rich_text最终装载到这个shared_strings_values_变量里面,allow_duplicates默认值是false,这里d_->shared_strings_ids_.find(shared)对rich_text进行了检查是否存在,当存在相同rich_text时又对end()进行了检查,查看shared_strings_ids_的定义:
//workbook_impl.hpp
std::unordered_map<rich_text, std::size_t, rich_text_hash> shared_strings_ids_;
也就是这个end()就是检查rich_text的hash值,到这里问题很明显了,在1.xlsx中对两个
4.修改源代码
既然对两个
#pragma once
#include 修改rich_text.cpp部分函数:
//...
rich_text &rich_text::operator=(const rich_text &rhs)
{
runs_.clear();
runs_ = rhs.runs_;
unique_index = rhs.unique_index;
return *this;
}
//...
void rich_text::clear()
{
runs_.clear();
unique_index = 0;
}
//...
bool rich_text::operator==(const rich_text &rhs) const
{
if (runs_.size() != rhs.runs_.size()) return false;
for (std::size_t i = 0; i < runs_.size(); i++)
{
if (runs_[i] != rhs.runs_[i]) return false;
}
return unique_index == rhs.unique_index;
}
//...
修改函数xlsx_consumer::read_shared_string_table
void xlsx_consumer::read_shared_string_table()
{
expect_start_element(qn("spreadsheetml", "sst"), xml::content::complex);
skip_attributes({"count"});
bool has_unique_count = false;
std::size_t unique_count = 0;
if (parser().attribute_present("uniqueCount"))
{
has_unique_count = true;
unique_count = parser().attribute<std::size_t>("uniqueCount");
}
uint32_t unique_index = 0;
while (in_element(qn("spreadsheetml", "sst")))
{
expect_start_element(qn("spreadsheetml", "si"), xml::content::complex);
auto rt = read_rich_text(qn("spreadsheetml", "si"));
rt.unique_index = unique_index++;
target_.add_shared_string(rt);
expect_end_element(qn("spreadsheetml", "si"));
}
expect_end_element(qn("spreadsheetml", "sst"));
if (has_unique_count && unique_count != target_.shared_strings().size())
{
throw invalid_file("sizes don't match");
}
}
重新编译生成,可以看到从1.xlsx和2.xlsx中读出的内容相同
下一篇介绍如何导出excel
Microsoft C++ 异常: xlnt::invalid_cell_reference,位于内存位置 xxx 处
先定位到源代码,cell_reference.cpp的split_reference函数:

这里reference_string值“A1048576 C1:C1048576”,查看调用堆栈,上一个函数是cell_reference
cell_reference::cell_reference(const std::string &string)
{
auto split = split_reference(string, absolute_column_, absolute_row_);
column(split.first);
row(split.second);
}
再看上一级调用函数:
range_reference::range_reference(const std::string &range_string)
: top_left_("A1"), bottom_right_("A1")
{
auto colon_index = range_string.find(':');
if (colon_index != std::string::npos)
{
top_left_ = cell_reference(range_string.substr(0, colon_index));
bottom_right_ = cell_reference(range_string.substr(colon_index + 1));
}
else
{
top_left_ = cell_reference(range_string);
bottom_right_ = cell_reference(range_string);
}
}
大概的意思是分割字符串得到行列位置,左上和右下分割靠‘:’分割,这里range_string的值为A1:A1048576 C1:C1048576,跟之前的相比较明显看出这里冒号分割不彻底造成,没有考虑到多个范围的情况,那这个range_string到底从哪里来什么意思呢,再看上级调用,定位到xlsx_consumer::read_worksheet_begin这个函数:
...
if (parser().attribute_present("sqref"))
{
const auto sqref = range_reference(parser().attribute("sqref"));
current_selection.sqref(sqref);
}
...
到这里可以看到是读取了sqref属性的值,再次刨开1.xslx,终于找到罪魁祸首
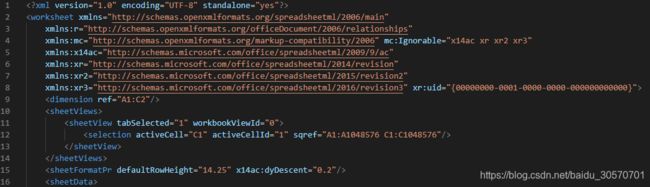
在sheet1.xml中的一个selection段里面"sqref=“A1:A1048576 C1:C1048576"”,在官方文档终于找到这个selection的解释https://docs.microsoft.com/en-us/dotnet/api/documentformat.openxml.spreadsheet.selection?view=openxml-2.8.1,意思就是说用户在活动单元格中选择的不连续引用范围。没错,我在xlsx中选择了两列后再ctrl+s进行保存就触发了这个bug
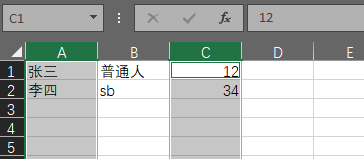
终究的原因在range_reference::range_reference这个函数处理不当造成的,既然我们是导入excel数据,因此不关心用户的选择,稍作修改只认用户第一个选中的cell,忽略其他选中:
range_reference::range_reference(const std::string &range_string)
: top_left_("A1"), bottom_right_("A1")
{
auto colon_index = range_string.find(':');
if (colon_index != std::string::npos)
{
auto space_index = range_string.find(' ');
top_left_ = cell_reference(range_string.substr(0, colon_index));
if (space_index == std::string::npos)
{
bottom_right_ = cell_reference(range_string.substr(colon_index + 1));
}
else
{
bottom_right_ = cell_reference(range_string.substr(colon_index + 1, space_index - colon_index - 1));
}
}
else
{
top_left_ = cell_reference(range_string);
bottom_right_ = cell_reference(range_string);
}
}
Microsoft C++ 异常: xlnt::invalid_sheet_title,位于内存位置 xxx 处
报错的原因很明显,在源代码253行抛出的,原因是tiitle字符串长度太长
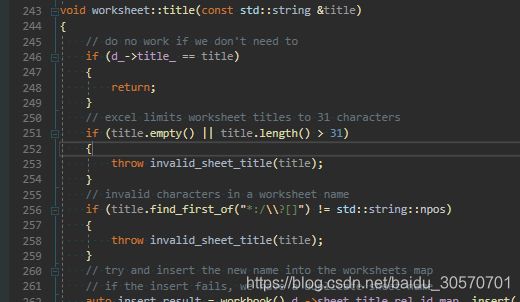
手动修改excel发现sheet表的title名称的确不能超过31个字符,但这里计算没有考虑到Unicode字符串,导致中文超过10个就会抛出异常,稍作修改就可解决
//需要包含2个头文件
#include