数据结构——顺序二叉树——堆
1.树的相关概念
在介绍二叉树之前,我们首先要明确树是什么。
树用我们的通常认识来判断应该是一种植物,从根向上生长,分出许多的树枝并长出叶子。对于数据结构中的树而言,其结构也正是从树的特征中剥离出来的。树结构是一种非线性数据结构,具有一个根结点,这一个根节点连接着其他若干个结点,这些结点也同样可以连接这其他若干个结点,如此形成的数据结构我们就称为树。

子树即树的子集,我们可以认为根节点延伸出的若干个节点实际上是若干棵子树。注意,在树形结构的定义下子树之间不允许交集的存在,即树中不允许存在环。
一个结点或树具有一些性质,一个结点的度指的是其所含有的子树的个数,而一个树的度指的是这棵树的结点中最大的度;一个结点的层次指的是其对于根节点而言所处的层数,而一个树的高度/深度指的是这棵树的结点中最大的层次。
按照结点的度和层次特点,可以分为:根节点——第一层;叶子结点——度为0;分支结点——度不为0;根据我们生活中的伦理关系延伸,一个结点的前驱结点称为父结点,后继结点称为子节点,同一个父结点的结点称为兄弟节点。
2.二叉树相关概念与存储结构
2.1 二叉树概念
二叉树是一种特殊的树。满足度为2的树就是二叉树,所以对于任意一个二叉树的节点我们都可以将其视为是一个根节点连接着左右两个子树的结构。

满二叉树是一种特殊的二叉树,其每一层结点的个数都是满的。因此对于一个n层的满二叉树,其结点个数为 个。
个。
完全二叉树也是一种特殊的二叉树,其与和满二叉树相似,结点按层依次排序,到所有结点连接前不允许出现空位。
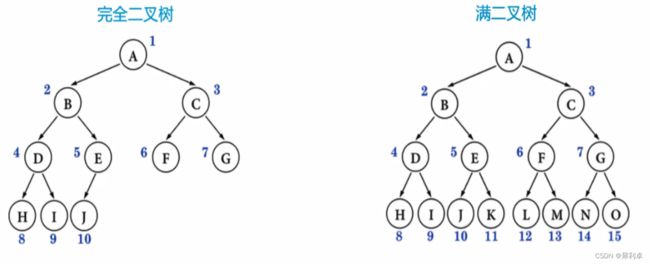
值得注意的是:二叉树的度为0的结点个数一定比度为2的结点个数多一个。
2.2二叉树的存储结构
2.2.1 顺序结构
顺序结构采取数组来存储二叉树。数组根据二叉树按层的顺序将每个结点的值存进数组的对应位置。对于一棵完全二叉树,其父子结点之间在下标上存在固定的递推关系式,对于一个根节点位于下标为0位置的树而言:左孩子下标=父结点下标*2+1;右孩子下标=父结点下标*2+2;父结点下标=孩子结点下标/2。根据这个规律,我们便可以在数组中存下所有的二叉树结点并可以找到结点相关联的其它结点。
可见,顺序二叉树按位置以此存储,这就意味着如果不是完全二叉树,那么在数组中就会出现空位。因此顺序二叉树一般只会用于完全二叉树来避免空间浪费。

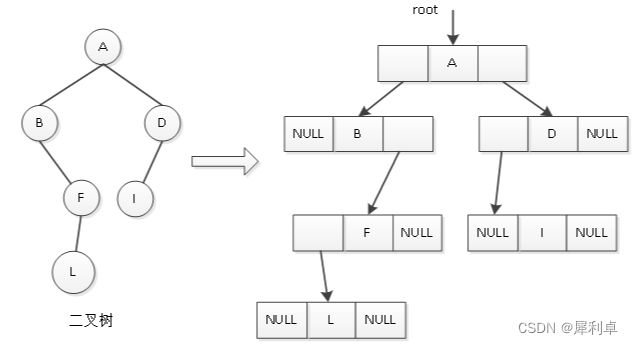
2.2.2 链式结构
链式二叉树使用链表来表示,链就作为二叉树的逻辑关系指示。链式二叉树结点存储着自己的数据和两个指针,指针分别指向左孩子和右孩子,由此组成最后的完整的二叉树。链式二叉树可以存储任意形式的二叉树,我们一般采用二叉链。
2.堆
2.1 堆的概念
对于一个集合k,将其所有元素按照顺序二叉树的方式存入一个一维数组,对任意元素 ,若满足
,若满足![]() 且
且![]() 则为小堆;若满足
则为小堆;若满足![]() 且
且![]() 则为大堆。
则为大堆。
通俗解释来说:堆是一个完全二叉树,当所有的父结点都小于等于自己的子结点时,构成了小堆;当所有的父结点都大于等于自己的子结点时,构成了大堆。

2.2 堆的工程
2.2.1 堆的定义
因为我们已经明确了,堆是使用数组进行存储,所以堆的实现方式应该和顺序表相同。
typedef int HPDataType;
typedef struct Heap
{
HPDataType* data;
int size;
int capacity;
}HP;2.2.2 堆的函数接口
2.2.2.1 堆的初始化与销毁
堆的初始化与销毁和顺序表相同,不再过多叙述。
void HeapInit(HP* php)
{
assert(php);
php->data = NULL;
php->capacity = php->size = 0;
}
void HeapDestroy(HP* php)
{
assert(php);
free(php->data);
php->data = NULL;
php->capacity = php->size = 0;
}2.2.2.2 堆的大小、判空、取堆顶元素
这些都是很基础的操作,与栈和队列相似,也不再详细说道。
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
HPDataType HeapTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->data[php->size - 1];
}2.2.3 堆的数据插入——向上调整
对于一个堆,当我们插入一个数据的时候,这个数据会被插入到数组的尾部,也即二叉树的下一个结点处。但是我们的堆可不是那么随便的结构,小堆大堆数据之间有着自己特定的结构,这样直接在后面插入数据有可能会破坏其原有的结构,所以我们需要考虑如何再插入数据后保持其堆的特性。为此我们引入了向上调整算法。
向上调整算法目的是将新入堆的元素位置与原堆中的元素位置进行调整,使得再次构成一个堆。
对于小堆而言,向上调整就是将子结点与其父亲相比,如果孩子小于父亲,则将二者位置调换,循环往复直到满足堆的条件为止。对于大堆而言,向上调整就是将子结点与其父亲相比,如果孩子大于父亲,则将二者位置调换,循环往复直到满足堆的条件为止。在调整过程中,每次交换后根据父子结点下标关系可以找到新的父结点与子结点。小堆和大堆的向上调整算法只在if语句中判断条件不同。
void AdjustUpMin(int* arr, int size)
{
int child = size - 1;
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])
{
swap(&arr[child], &arr[parent]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
void AdjustUpMax(int* arr, int size)
{
int child = size - 1;
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] > arr[parent])
{
swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}当有了向上调整算法后,我们就可以进行数据插入了。
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HPDataType* tmp = realloc(php->data, sizeof(int) * newcapacity);
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
else
{
php->data = tmp;
}
php->capacity = newcapacity;
}
php->data[php->size] = x;
php->size++;
AdjustUp(php);
}2.2.4 堆的数据删除——向下调整
对于堆来说,堆顶的元素是具有特殊意义的。小堆的堆顶是最小的,大队的堆顶是最大的。所以在对堆进行数据删除时,我们删除数组最后的元素意义不大,我们考虑的是取出堆顶元素后,针对元素堆顶进行删除。同理堆删除数据也会导致堆的结构被破坏,所以需要我们需要想办法恢复其堆的特性。这就需要我们设计向下调整算法。
向下调整算法的目的是将堆顶的元素与原堆中的元素交换位置,使得可以继续满足原来小堆或大堆的特征。
对于小堆而言,向下调整是将其与子结点相比较,因为父结点需要小于子结点,所以我们需要选取左右孩子结点中较小的一个。为此我们可以假设左孩子是较小者,如果右孩子比左孩子小说明假设错误,让child+1即可。之后判断父结点与子结点的大小关系,如果满足小堆的要求就结束,否则将二者调换位置,然后找到新的父结点和子结点下标。如此循环,即可调整成为小堆。而对于大堆,和小堆同理,只是判断标准变成了父结点需要大于子节点,若父结点小于子节点则需要调整位置。
void AdjustDownMin(int* arr, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && arr[child] > arr[child + 1])
{
child++;
}
if (arr[child] < arr[parent])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void AdjustDownMax(int* arr, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && arr[child] < arr[child + 1])
{
child++;
}
if (arr[child] > arr[parent])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = child * 2 + 1;
}
else
{
break;
}
}
}于是乎,我们就可以写出数据删除的函数,这里是将堆顶元素删除,然后用最后一个元素代替堆顶元素,进行向下调整。
void HeapPop(HP* php)
{
assert(php);
Swap(&php->data[0], &php->data[php->size - 1]);
php->size--;
AdjustDown(php);
}