python统计分析——随机抽样(np.random.choice)
参考资料:用python动手学统计学,帮助文档
import numpy as np
import pandas as pd
data_set=np.array([2,3,4,5,6,7])
np.random.choice(data_set,size=2)
(1)a,数据源,用一列数据作为抽样的数据源。
(2)size,表示需要抽取的样本数量,如果直接为数字,则按数字抽取对应的样本量;如果为数字组成的元组,则表示抽取样本形成元组对应的数组。如下:

(3)replace,默认为True,表示重置抽样(有放回抽样);False则表示无重置抽样(无放回抽样)。当设置为False时,参数size最大不能超过样本框的容量。


(4)p,用于设置抽样框中各单元被抽中的概率,要求p的设置与数据源有相同的数据量,默认设置为等概率抽样。

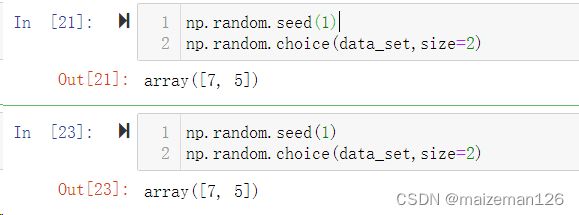
这里介绍一个随机种子(np.random.seed)的设置。
为了能让他人复现自己的操作结果,在各种书籍中在进行随机取样时,通常会设置随机种子。
如果设置了随机种子,则每次执行所得到的样本都是相同的。只要使用随机种子中的参数相同,则随机取样的的结果就是相同的;若参数不同,则随机取样的结果也不同。效果如下: