Hive导入数据的五种方法
在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名; 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse; 也可以在建表的时候使用location语句指定任意路径。
不管路径在哪里,只有把数据文件移动到对应的表文件夹下面,Hive才能映射解析成功; 最原始暴力的方式就是使用hadoop fs –put | -mv等方式直接将数据移动到表文件夹下; 但是,Hive官方推荐使用hive命令将数据加载到表中。
本篇文章介绍五种导入数据的方法:Load 加载数据 、Insert插入数据、 As Select加载数据、 Location加载数据、 Import加载数据
一、Load加载数据
Load英文单词的含义为:加载、装载;
所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作。
纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
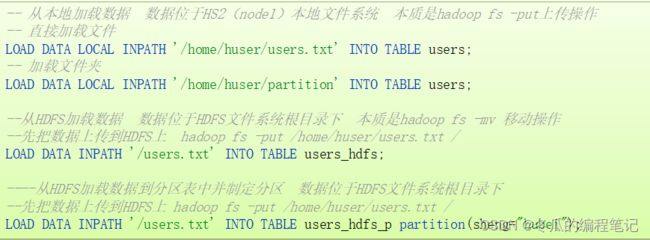
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
语法规则
语法规则之filepath
filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中)。
filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑:
相对路径,例如:project/data1
绝对路径,例如:/home/huser/project/data1
具有schema的完整URI,例如:hdfs://localhost:9000/user/hive/project/data1
语法规则之LOCAL
指定LOCAL, 将在本地文件系统中查找文件路径。
若指定相对路径,将相对于用户的当前工作目录进行解释;
用户也可以为本地文件指定完整的URI-例如:file://user/hive/project/data1。
没有指定LOCAL关键字。
如果filepath指向的是一个完整的URI,会直接使用这个URI;
Hive会使用在hadoop配置文件中参数fs.default.name指定的(一般都是HDFS)。
LOCAL本地是哪里?
本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统。
语法规则之OVERWRITE
如果使用了OVERWRITE关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
代码示例

二、Insert插入数据
insert+select
insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据。
需要保证查询结果列的数目和需要插入数据表格的列数目一致。
如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;

multiple inserts多重插入
翻译为多次插入,多重插入,其核心功能是:
一次扫描,多次插入。 语法目的就是减少扫描的次数,在一次扫描中。完成多次insert操作。

三、As Select加载数据
创建表的同时,可以通过查询语句As Select把已有表中的数据加载到新创建的表中。这种加载数据的方式在创建表时不需要指定列名。

四、Location加载数据
创建表时通过Location指定加载路径来加载数据。这里Location指定数据文件存放位置,不管是通过Select方式还是通过Load方式加载的数据都存放在这个目录下。

五、Import加载数据
通过Import方式可以把数据加载到指定Hive表中。但是这种方法需要先用Export导出后,再将数据导入。
