DirectX12_入门之三角形
为了更加深刻的理解图形API之间的区别,从此文让我们正式开始DirectX12的学习之旅。之前了解过OpenGL、DX11与Vulkan,我们也简单的知道了这些图形API之间的区别和架构上的差异,我们现在来看一下DX12,从使用中了解它与Vulkan的异步架构之间的异同。
具体代码参照DX12龙书github。
一、准备工作
首先需要先了解:DirectX12_基础知识;
为了实现DX12这个目标的大致步骤也跟调用历史版本的D3D11、OpenGL、Vulkan中一样,就是先创建Windows的窗口,接着创建设备对象、准备各种资源,再设置渲染管线的状态,最终在消息循环中不断的调用OnUpdate和OnRender(我的例子中甚至没有封装这两个函数,这里只是让大家先有个框架概念的认识,聪明的你应该一点就通了)。当然这个过程和我们以前学用其他的D3D接口甚至与学用OpenGL接口的过程都是完全一致的。看到这些共同点,我们应该庆幸,同时也应该信心满满的认为,至少这世界还尽在我们掌握之中!
而进一步我们真正要好好注意和学习的就是那些不同点和足以致命的细节了,因为在D3D12中加入了“显存管理”、“多线程渲染”、“异步Draw Call”等的高级概念,所以在具体使用上就有其独特的风格和复杂性了。
1.1 头文件与库
要调用D3D12,第一步就是包含其头文件并链接其lib,那么就在你的代码开头这样来写:
#include 首先,代码中使用了WRL,它给我们带了基础安全的便捷性(就是让我们忘记那些Release调用,也不会带来内存泄漏等问题)。
其次,我们包含了
再次,用#pragma comment(lib, “xxxxxx.xxx”)来引用lib库,对了VS使用的是2017。
又次,项目中包含了"d3dx12.h",这个文件是将D3D12中的结构都派生(说扩展更合适)为简单的类,以便于使用,它的“封装”我认为应该算作是D3D12 sdk的一部分,可以直接从最新的微软D3D12示例中找到。
最后,GRS_THROW_IF_FAILED这个宏其实它就是为了在调用COM接口时简化出错时处理时使用的一个宏,就是为了出错时抛出一个异常,因为只要是有异常机制的语言,程序员们都会使用抛异常来简化。
接下来我们开始看DX12的初始化主要流程阶段:
-
使用 D3D12CreateDevice 函数创建 ID3D12Device
-
创建 ID3D12Fence object 并确认 descriptor 大小
-
检查 4X MSAA quality level 支持
-
创建 command queue, command list allocator, and main command list
-
定义并创建 swap chain
-
创建应用需要的 descriptor heaps
-
重置 back buffer 大小,并为 back buffer 创建 render target view
-
创建 depth/stencil buffer 和 associated depth/stencil view
-
设置 viewport 和 裁剪框
1.2 变量定义
接下来,我们需要进行DX12变量定义:
const UINT nFrameBackBufCount = 3u;
int iWidth = 1024;
int iHeight = 768;
UINT nFrameIndex = 0;
UINT nFrame = 0;
UINT nDXGIFactoryFlags = 0U;
UINT nRTVDescriptorSize = 0U;
HWND hWnd = nullptr;
MSG msg = {};
float fAspectRatio = 3.0f;
D3D12_VERTEX_BUFFER_VIEW stVertexBufferView = {};
UINT64 n64FenceValue = 0ui64;
HANDLE hFenceEvent = nullptr;
CD3DX12_VIEWPORT stViewPort(0.0f, 0.0f, static_cast<float>(iWidth), static_cast<float>(iHeight));
CD3DX12_RECT stScissorRect(0, 0, static_cast<LONG>(iWidth), static_cast<LONG>(iHeight));
ComPtr<IDXGIFactory5> pIDXGIFactory5;
ComPtr<IDXGIAdapter1> pIAdapter;
ComPtr<ID3D12Device4> pID3DDevice;
ComPtr<ID3D12CommandQueue> pICommandQueue;
ComPtr<IDXGISwapChain1> pISwapChain1;
ComPtr<IDXGISwapChain3> pISwapChain3;
ComPtr<ID3D12DescriptorHeap> pIRTVHeap;
ComPtr<ID3D12Resource> pIARenderTargets[nFrameBackBufCount];
ComPtr<ID3D12CommandAllocator> pICommandAllocator;
ComPtr<ID3D12RootSignature> pIRootSignature;
ComPtr<ID3D12PipelineState> pIPipelineState;
ComPtr<ID3D12GraphicsCommandList> pICommandList;
ComPtr<ID3D12Resource> pIVertexBuffer;
ComPtr<ID3D12Fence> pIFence;
struct GRS_VERTEX
{
XMFLOAT3 position;
XMFLOAT4 color;
};
其中我们目标是要画一个三角形,所以要先定义我们的3D顶点数据结构GRS_VERTEX,当然其中的XMFLOAT3和XMFLOAT4来自DirectXMath库,等价于float[3]和float[4]。当然如果你之前有了解过关于shader优化的一些专题的话,那么在正式的项目中你应该至少保持4*sizeof(float)边界对齐,这样可以提高GPU访问这些数据的效率。
1.3 创建窗口
// 创建窗口
{
WNDCLASSEX wcex = {};
wcex.cbSize = sizeof(WNDCLASSEX);
wcex.style = CS_GLOBALCLASS;
wcex.lpfnWndProc = WndProc;
wcex.cbClsExtra = 0;
wcex.cbWndExtra = 0;
wcex.hInstance = hInstance;
wcex.hCursor = LoadCursor(nullptr, IDC_ARROW);
wcex.hbrBackground = (HBRUSH)GetStockObject(NULL_BRUSH); //防止无聊的背景重绘
wcex.lpszClassName = GRS_WND_CLASS_NAME;
RegisterClassEx(&wcex);
DWORD dwWndStyle = WS_OVERLAPPED | WS_SYSMENU;
RECT rtWnd = { 0, 0, iWidth, iHeight };
AdjustWindowRect(&rtWnd, dwWndStyle, FALSE);
// 计算窗口居中的屏幕坐标
INT posX = (GetSystemMetrics(SM_CXSCREEN) - rtWnd.right - rtWnd.left) / 2;
INT posY = (GetSystemMetrics(SM_CYSCREEN) - rtWnd.bottom - rtWnd.top) / 2;
hWnd = CreateWindowW(GRS_WND_CLASS_NAME
, GRS_WND_TITLE
, dwWndStyle
, posX
, posY
, rtWnd.right - rtWnd.left
, rtWnd.bottom - rtWnd.top
, nullptr
, nullptr
, hInstance
, nullptr);
if (!hWnd)
{
return FALSE;
}
ShowWindow(hWnd, nCmdShow);
UpdateWindow(hWnd);
}
注意代码中指定的窗口风格WS_OVERLAPPEDWINDOW,这里因为我们不处理OnSize事件(众所周知,窗口重绘需要动态修改,以后再详细处理吧)。
二、创建DXGI
这些基础的工作做完了,我们就要开始正式调用D3D12接口了。根据前面的简要描述这里就该创建设备对象接口了,在D3D12中,一个重要的概念是将设备对象概念进行了扩展。将原来在D3D9中揉在一起的图形子系统(从硬件子系统角度抽象),显示器,适配器,3D设备等对象进行了分离,而分离的标志就是使用IDXGIFactory来代表整个图形子系统,它主要的功用之一就是让我们创建适配器、3D设备等对象接口用的,因此它的名字就多了个Factory,这估计也是暗指Factory设计模式之故。这个对象接口就是我们要创建的第一个接口:
CreateDXGIFactory2(nDXGIFactoryFlags, IID_PPV_ARGS(&pIDXGIFactory5));
// 关闭ALT+ENTER键切换全屏的功能,因为我们没有实现OnSize处理,所以先关闭
GRS_THROW_IF_FAILED(pIDXGIFactory5->MakeWindowAssociation(hWnd, DXGI_MWA_NO_ALT_ENTER));
在D3D中,如果你了解COM的话,你就会知道所有D3D12对象接口的初始化创建不能再使用COM规范的CoCreateInstance函数了,这是你必须忘记的第一个招式。这里你要记住的就是D3D12仅仅利用了COM的接口概念而已,其它的都忽略了。这样我们在使用这些接口时就可以简单的理解为是系统提供的只有公有函数的类的对象指针即可
三、创建设备对象接口
有了IDXGIFactory的接口,我们就需要枚举并选择一个合适的显示适配器(显卡)来创建D3D设备接口。这里要说明的是为什么我们要选择枚举这种啰嗦的方式来创建我们的设备接口呢?因为对于现代的很多PC系统来说CPU中往往集成了显卡,同时系统中还会有一个独立的显卡。另外大多数笔记本系统中,为节能之目的,往往会把集显作为默认的显示适配器,而由于集显功能性能限制的问题,所以在有些示例中可能会引起一些问题,尤其是将来准备使用DXR渲染的时候。
所以基于这样的原因,这里就使用比较繁琐的枚举显卡适配器的方式来创建3D设备对象。另外这也是为将来使用多显卡渲染示例的需要做准备的。代码如下:
for (UINT adapterIndex = 0
; DXGI_ERROR_NOT_FOUND != pIDXGIFactory5->EnumAdapters1(adapterIndex, &pIAdapter)
; ++adapterIndex)
{
DXGI_ADAPTER_DESC1 desc = {};
pIAdapter->GetDesc1(&desc);
if (desc.Flags & DXGI_ADAPTER_FLAG_SOFTWARE)
{//软件虚拟适配器,跳过
continue;
}
//检查适配器对D3D支持的兼容级别,这里直接要求支持12.1的能力,注意返回接口的那个参数被置为了nullptr,这样
//就不会实际创建一个设备了,也不用我们啰嗦的再调用release来释放接口。这也是一个重要的技巧,请记住!
if (SUCCEEDED(D3D12CreateDevice(pIAdapter.Get(), D3D_FEATURE_LEVEL_12_1, _uuidof(ID3D12Device), nullptr)))
{
break;
}
}
//创建D3D12.1的设备
GRS_THROW_IF_FAILED(D3D12CreateDevice( pIAdapter.Get() , D3D_FEATURE_LEVEL_12_1 ,IID_PPV_ARGS( &pID3DDevice )));
特别需要提醒的是,你在代码的创建循环中的if (desc.Flags & DXGI_ADAPTER_FLAG_SOFTWARE)语句上设置断点,然后仔细查看desc中的内容,确认你用于创建设备对象的适配器是你系统中最强的一块显卡。一般系统中默认序号0的设备是集显,如果不是独显,那就请你修改adapterIndex这个循环初值,比如改为1或2过更高的值试试,当然前提是你的系统中确定有那么多适配器(也就是显卡),直到使用了性能最强的一个适配器来创建设备。这样做的目的不是为了跑性能,而是目前我发现集显在运行一些高级功能时会出现一些问题,很多高级功能是不支持的,用功能比较强的独显是不错的一个方法。
四、创建命令队列接口
再接下去如果你熟悉D3D11的话,我们就需要创建DeviceContext对象及接口了,而在D3D9中有了设备接口就相当于有了一切,直接就可以加载资源,设置管线状态,然后开始渲染。
其实我一直觉得在D3D11中这个接口对象及名字DeviceContext不是那么直观。在D3D12中就直接改叫CommandQueue了。这是为什么呢?其实现代的显卡上或者说GPU中,已经包含多个可以同时并行执行命令的引擎了,不是游戏引擎,可以理解为执行某类指令的专用微核。也请注意这里的概念,一定要理解并行执行的引擎这个概念,因为将来的重要示例如多线程渲染,多显卡渲染示例等中还会用到这个概念。
这里再举个例子来加深理解这个概念,比如支持D3D12的GPU中至少就有执行3D命令的引擎,执行复制命令的引擎(就是从CPU内存中复制内容到显存中或反之或GPU内部以及引擎之间),执行通用计算命令的引擎(执行Computer Shader的引擎)以及可以进行视频编码解码的视频引擎等。而在D3D12中针对这些不同的引擎,就需要创建不同的命令队列接口来代表不同的引擎对象了。这相较于传统的D3D9或者D3D11设备接口来说,不但接口被拆分了,而且在对象概念层级上都进行了拆分。
因为我们的目标是绘制一个三角形,因此我们第一个要创建的引擎(命令队列)就是3D图形命令队列(暂时我们也只需要这个)。创建的代码如下:
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
GRS_THROW_IF_FAILED(pID3DDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&pICommandQueue)));
这段代码中较特别的地方之一就是我们需要一个结构来传递参数给创建函数,这是一种函数设计风格,之所以这里要重点强调这个,是因为在D3D12中这种风格被大量使用。比之用参数列表来调用函数的方式,这种方式在可写性修改性上有很大的改观,对于不用的参数,不赋值即可。这也是与Vulkan相似的地方。
另一个需要注意的细节就是我们创建3D图形命令队列(引擎)的标志是D3D12_COMMAND_LIST_TYPE_DIRECT从其名字几乎看不出是什么意思,其实这个标志的真正含义是说,我们创建的不只是能够执行3D图形命令的队列那么简单,而是说它是图形设备的“直接”代表物,本质上还可以执行几乎所有的命令,包括图形命令、复制命令、计算命令甚至视频编解码命令,还可以执行捆绑包(这个也是以后介绍),因此它是3D图形命令队列(引擎)的超集,基本就是代表了整个GPU的执行能力,固名直接。
五、创建交换链
有了命令队列对象,接下去我们就可以创建交换链了。与之前的D3D版本不同,尤其是与D3D9等古老接口不同,D3D12中交换链更加的独立了。为了概念上更加清晰,我建议你将交换链理解为一个画板上有很多页画纸,而渲染管线就是画笔颜料等等,虽然他们要组合在一起才能绘画,但本质上是独立的东西,因为画纸我们还可以使用完全不同的别的笔来写字或绘画,比如交换链还可以用于D2D、DirectWrite绘制等,只是在这里我们是用来作为3D渲染的目标。
另外在D3D12中具体创建交换链时就需要指定一个命令队列,这也是最终呈现画面前,交换链需要确定绘制操作是否完全完成了,也就是需要这个命令队列最终Flush(刷新)一下。创建交换链的代码如下:
DXGI_SWAP_CHAIN_DESC1 swapChainDesc = {};
swapChainDesc.BufferCount = nFrameBackBufCount;
swapChainDesc.Width = iWidth;
swapChainDesc.Height = iHeight;
swapChainDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
swapChainDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
swapChainDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
swapChainDesc.SampleDesc.Count = 1;
GRS_THROW_IF_FAILED(pIDXGIFactory5->CreateSwapChainForHwnd(
pICommandQueue.Get(),
hWnd,
&swapChainDesc,
nullptr,
nullptr,
&pISwapChain1
));
上面的代码中没什么特别的,风格上依旧是结构体做函数的主要参数,要注意的就是SwapEffect参数,目前赋值DXGI_SWAP_EFFECT_FLIP_DISCARD即可,在后面的文章中再细聊这个参数的作用,对于一般的应用来说,这样就已经足够了。
有了交换链,那么我们就需要知道当前被绘制的后缓冲序号是哪一个(注意这个序号是从0开始的,并且每个后缓冲序号在新的D3D12中是不变的),调用下面的代码就可以得到当前绘制的后缓冲的序号:
GRS_THROW_IF_FAILED(pISwapChain1.As(&pISwapChain3));
//6、得到当前后缓冲区的序号,也就是下一个将要呈送显示的缓冲区的序号
//注意此处使用了高版本的SwapChain接口的函数
nFrameIndex = pISwapChain3->GetCurrentBackBufferIndex();
这段代码中我们调用了WRL::ComPtr的函数As,其内部就是调用QueryInterface的经典COM方法,没什么稀奇的。我们是使用低版本的SwapChain接口得到了一个高版本的SwapChain接口。目的是为了调用GetCurrentBackBufferIndex方法,而从其来自高版本接口可以知道,这是后来扩展的方法。主要原因就是现在翻转绘制缓冲区到显示缓冲区的方法更高效了,直接就是将对应的后缓冲序号设置为当前显示的缓冲序号即可,比如原来显示的是序号为1的缓冲区,那么下一个要显示的缓冲区就是序号2的缓冲区,如果为2的缓冲区正在显示,那么下一个将要显示的序号就又回到了0,当然这里假设缓冲区数量是3,我们的例子中就正好是3个缓冲区,所以缓冲区的序号就正好是缓冲区数量的余数(MOD)。其他情况依此类推。
前版本的D3D中,拿到了交换链的后缓冲之后,我们就需要创建一个叫做Render Target View(简称RTV,最好背下来)Descriptor渲染目标视图描述符的对象及接口。类似僵尸片中的各种灵符一样,描述符也有一些神奇的功用,比如拿RTV描述符贴在一块纹理上,它立刻就变成了RTV。它的作用是让GPU能够正确识别和使用渲染目标资源,其本质就是描述缓冲区占用的显存,所以从本质上讲只要是可以作为一整块显存来使用的缓冲都可以作为渲染目标, 比如有一些高级渲染技法中就需要渲染到纹理上,当然我们要做的也很简单就是给那些纹理贴上RTV符即可。
因为GPU内部本质上是一个巨大的SIMD架构的处理器,同时考虑到很多微核(可以理解为就是GPU中的多个ALU单元)并行执行的需要,所以它在存储器的使用上是非常细化的,在使用某段存储(内存或显存)之前,就需要通过类似描述符之类的概念等价物说清楚这段存储的用途、大小、读写属性、GPU/CPU访问权限等信息。因为创建交换链的主要目的是用它的缓冲区作为3D图形渲染的目标,所以我们就需要用渲染目标视图描述符告诉GPU这些缓冲区是渲染目标。
六、创建创建RTV描述符堆和RTV描述符
在D3D12中加入了一个重要的概念——描述符堆,首先看到堆这个词我们应当联想到内存管理(如果你想到了数据结构,说明你基本功还可以,这里我们讨论的是D3D12,跟数据结构关系不大,所以应当正确联想到内存管理中的堆栈);其次在D3D12中凡是套用了堆(Heap)这个概念的对象,目前应当将他们理解为固定大小的数组对象,而不是真正意义上可以管理任意大小内存块并能够自动伸缩大小的内存堆栈。未来不好说D3D中会不会实现全动态的显存堆管理。在目前我们就理解为它是数组即可。
这也是D3D12在功能上较之前版本的D3D接口扩展出来的重要概念——显存管理(或称之为存储管理更合适,这里用显存是为了强调与传统系统内存管理的区别)的一个重要表现。
渲染目标视图描述符堆的代码如下:
D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc = {};
rtvHeapDesc.NumDescriptors = nFrameBackBufCount;
rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
GRS_THROW_IF_FAILED(pID3DDevice->CreateDescriptorHeap(&rtvHeapDesc, IID_PPV_ARGS(&pIRTVHeap)));
//得到每个描述符元素的大小
nRTVDescriptorSize = pID3DDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
上述代码在风格上依旧是结构体做参数调用函数的老套路。结构体初始化时Type参数赋值为D3D12_DESCRIPTOR_HEAP_TYPE_RTV,表示我们将创建的堆(数组)是用来存储RTV描述符的堆(数组)。通过NumDescriptors参数我们就指定了堆的大小(实质上是数组元素的个数),Flags参数暂时不介绍,像这里赋值就OK。堆创建完了之后我们就调用D3D设备接口的GetDescriptorHandleIncrementSize方法得到实际上每个RTV描述的大小,也就是数组元素的真实大小,你可以理解为我们相当于调用了一个sizeof运算符,得到了一个不知道里面存了些啥的复杂结构体的大小,当然计量单位是字节。
有了RTV描述符堆(数组),那么我们就可以创建RTV描述符了,代码如下:
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHandle(pIRTVHeap->GetCPUDescriptorHandleForHeapStart());
for (UINT i = 0; i < nFrameBackBufCount; i++)
{
GRS_THROW_IF_FAILED(pISwapChain3->GetBuffer(i, IID_PPV_ARGS(&pIARenderTargets[i])));
pID3DDevice->CreateRenderTargetView(pIARenderTargets[i].Get(), nullptr, rtvHandle);
rtvHandle.Offset(1, nRTVDescriptorSize);
}
代码中首先我们使用了一个来自D3Dx12.h中扩展的类CD3DX12_CPU_DESCRIPTOR_HANDLE来管理描述堆的当前元素指针位置,概念上你可以将这个对象理解为一个数组元素迭代器,虽然它的名字被定义成了HANDLE但我觉得使用iterator更确切。
接下来就是一个循环,循环上界就是我们创建的交换链中的后缓冲个数,在我们的例子中是3个后缓冲,因此这个循环会执行三次,创建三个RTV描述符。这里要特别注意的是,缓冲的序号和对应描述符的数组元素序号要保持一致,当然代码中已经保证了这一点。循环最后一行Offset则暴漏了这里其实是在操作数组的本质。
七、创建根签名对象接口
再接下来我们就需要创建一个更重要的对象了,就是根签名。在这里首先你要为你能坚持看到这里给自己点个赞,因为D3D12中为完成渲染加入了太多的概念和对象,当然这些概念的加入都是为了提高性能而设计的。当然能看到这里的前提是再次提醒你已经看过我之前写的关于D3D12的相关博客文章了。
从总体上来理解D3D12的话,就是在D3D12中加入了存储管理、所有的调用都是异步并行的方式并且为管理异步调用而加入了同步对象。这里提到的根签名则是为了整体上统一集中管理之前在D3D11中分散在各个资源创建函数参数中的存储Slot和对应寄存器序号的对象。也就是说在D3D12中我们不用在创建某个资源时单独在其参数中指定对应哪个Slot(暂时翻译为存储槽)和寄存器及序号了,而是统一在D3D12中用一个根签名就将这些描述清楚。
熟悉Shader的话,你就知道我们在写shader的时候有时候就需要指定每种数据,比如常量缓冲、顶点寄存器、纹理等资源是对应哪个存储槽和寄存器,及序号的。对于存储槽我们可以理解为一条从内存向显存传输数据的通道,想象成一个流水槽(如果你懂点点PCIe的话,可以将之理解为PCIe的一条通道)。而对于这里的寄存器就不是指CPU上的寄存器了,而是指GPU上的寄存器。根据前面的描述现代的GPU在概念上可以理解为一个巨大的SIMD架构的处理器,由于为高效并行执行指令的需要,它在存储管理上是非常细分的,甚至它的寄存器也是细化分类的,有常量寄存器、纹理寄存器、采样器等等,并且每类寄存器都有若干个,以序号来索引使用,所以在我们从CPU加载资源到GPU上时就需要详细指定那些数据从哪个槽上灌入到哪个序号的寄存器上。
而要达到这个目的就需要在两个方面明确指定这些参数,一方面是从程序代码(CPU侧)调用D3D12相关接口创建资源时指定传输参数(存储槽序号,寄存器序号),另一方面在Shader代码中指定接收参数,并指定Shader代码中具体访问哪个存储槽,哪个寄存器中的数据。或者更准确的说一般Shader中就不用管是哪个Slot了,因为数据肯定都已经到了显存中,Shader中实质关心的只是寄存器和其序号。
或者直接的说根签名就是描述了整个的用于渲染的资源的存储布局。在MSDN官方的描述中也是这样说的:根签名是一个绑定约定,由应用程序定义,着色器使用它来定位他们需要访问的资源。
最终在D3D12中之所以要统一管理这些的目的就是为了方便形成一个统一的管线状态对象(Pipeline States Object PSO),有了管线状态对象,在渲染时,只要资源加载正确,我们只需要在不同的渲染过程间切换设置不同的渲染管线状态对象即可,而在传统的D3D管线编码中,这些工作需要一个个设置管线状态,然后自己编写不同的管线状态管理代码来实现,在代码组织上过于分散和复杂,同时也不利于复杂场景渲染时快速切换不同渲染管线状态的需要。
而根签名对象则是总领一条管线状态对象存储绑定架构的总纲。在我们这里的例子中,因为我们没有用到复杂的数据,只是为了画一个三角形,并且没有纹理、没有采样器等等,所以我们就创建一个都是0索引(序号是1的意思,搞C的你应该明白)的一个根签名,代码如下:
CD3DX12_ROOT_SIGNATURE_DESC rootSignatureDesc;
rootSignatureDesc.Init(0, nullptr, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
ComPtr<ID3DBlob> signature;
ComPtr<ID3DBlob> error;
GRS_THROW_IF_FAILED(D3D12SerializeRootSignature(&rootSignatureDesc
, D3D_ROOT_SIGNATURE_VERSION_1
, &signature, &error));
GRS_THROW_IF_FAILED(pID3DDevice->CreateRootSignature(0
, signature->GetBufferPointer()
, signature->GetBufferSize()
, IID_PPV_ARGS(&pIRootSignature)));
这段代码中我们又用到一个d3dx12.h中扩展的类CD3DX12_ROOT_SIGNATURE_DESC来定义一个根签名的结构,然后编译一下,再创建根签名对象及其接口。这里的根签名参数已经说清楚了我们需要传递网格数据到管线中进行渲染并且要定义对应的Input Layout格式对象。
默认情况下Slot和寄存器序号都使用0。关于根签名的详细内容我们放在后续的教程中专门来细讲,这里先理解到这样就可以了。需要补充的就是,根签名的创建方式主要有两种,一种是使用脚本方式来编写一个根签名(VS中是扩展名为HLSLi的文件),另一种就是我们这里使用的定义一个结构体再编译生成一个根签名的方式。我们示例中使用的是第二种方法,我的建议是两种方法都掌握,这个我们后面的教程都会讲到。但是我们必须要清晰的认识到使用结构体然后调用编译函数在代码中编译的方法的巨大优势,因为这种形式很方便我们定义自己的根签名脚本,也就是脚本化。比如你可以用XML文件定义一个根签名结构,然后加载使用,这样就不会被禁锢于纯代码或纯HLSL脚本的方式中。而是可以自己扩展更灵活和易转换的方式。
八、编译Shader及创建渲染管线状态对象接口
至此,经过了这么多对象创建初始化工作后,我们终于可以看到一点曙光了,接下来我们就要创建渲染管线状态对象了,在D3D12以前,虽然有渲染管线状态这样一个概念,但在接口上它的所有状态设置都是按照渲染阶段来分不同的函数直接放在Device对象接口或Context对象接口中。现在渲染管线状态就被独立了成了一个对象,并用ID3D12PipelineState接口来代表。
从概念上讲,渲染管线状态就是把原来的Rasterizer State(光栅化状态)、Depth Stencil State(深度、蜡板状态)、Blend State(输出alpha混合状态)、各阶段Shader程序(VS、HS、DS、GS、PS、CS),以及输入数据模型(Input Layout)等组合在一个对象中,从而形成一个完整的可重用的Pipeline State Object(PSO 渲染管线状态对象)。这样我们就从每次不同的渲染需要设置不同的管线状态参数的过程中解放了出来,在实际使用时,只需要在开始时初始化一堆PSO,然后根据不同的渲染需要在管线上设置不同的PSO即可开始渲染,渲染部分代码就被大大简化了,从而使游戏引擎的封装实现也大大简化了。
实际上这也是符合现代大多数引擎中关于渲染部分的封装思路的。因为现代光栅化渲染的很多理论算法都已经很成熟很完备了,完全有条件统一为几大类不同的主流PSO,然后重用即可。甚至我们现在在使用一些现代化的游戏引擎开发游戏时基本都不用关注渲染部分的组件,引擎自带的组件已经很强悍了。所以这也是很多会用引擎开发游戏的开发人员往往对渲染部分了解和关注甚少的原因之一。
在D3D12中通过PSO对象,我们也具备了直接封装实现具有现代化水平的引擎渲染部件的能力,当然这需要你在封装设计上有一定功力,在这里我依然强调一下,这个教程中不讲封装,只讲基础。所以我们就直接看看最原始的调用代码是什么样子的:
ComPtr<ID3DBlob> vertexShader;
ComPtr<ID3DBlob> pixelShader;
#if defined(_DEBUG)
UINT compileFlags = D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION;
#else
UINT compileFlags = 0;
#endif
TCHAR pszShaderFileName[] = _T("D:\\Projects_2018_08\\D3DPipelineTest\\D3D12Trigger\\Shader\\shaders.hlsl");
GRS_THROW_IF_FAILED(D3DCompileFromFile(pszShaderFileName, nullptr, nullptr, "VSMain", "vs_5_0", compileFlags, 0, &vertexShader, nullptr));
GRS_THROW_IF_FAILED(D3DCompileFromFile(pszShaderFileName, nullptr, nullptr, "PSMain", "ps_5_0", compileFlags, 0, &pixelShader, nullptr));
D3D12_INPUT_ELEMENT_DESC inputElementDescs[] =
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 },
{ "COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 12, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 }
};
D3D12_GRAPHICS_PIPELINE_STATE_DESC psoDesc = {};
psoDesc.InputLayout = { inputElementDescs, _countof(inputElementDescs) };
psoDesc.pRootSignature = pIRootSignature.Get();
psoDesc.VS = CD3DX12_SHADER_BYTECODE(vertexShader.Get());
psoDesc.PS = CD3DX12_SHADER_BYTECODE(pixelShader.Get());
psoDesc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT);
psoDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT);
psoDesc.DepthStencilState.DepthEnable = FALSE;
psoDesc.DepthStencilState.StencilEnable = FALSE;
psoDesc.SampleMask = UINT_MAX;
psoDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
psoDesc.NumRenderTargets = 1;
psoDesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
psoDesc.SampleDesc.Count = 1;
GRS_THROW_IF_FAILED(pID3DDevice->CreateGraphicsPipelineState(&psoDesc, IID_PPV_ARGS(&pIPipelineState)));
这段代码在结构上比较清晰,也很容易理解,在编译完Shader程序后,就通过初始化一个PSO结构体,然后调用CreateGraphicsPipelineState创建一个PSO对象及其代表接口ID3D12PipelineState。
从PSO结构体的初始化上,你应该看到了D3D12与原来的D3D接口的明显不同,过去这些参数首先是通过调用一个个函数来设置的,并且按照不同的渲染阶段冠以IA、VS、PS、RS、OM等前缀名字,且不说它们看起来有多别扭,光是每次在渲染循环中调用一遍就够复杂了,如果你少设置了一个状态,有可能就引起奇奇怪怪的后果,尤其是复杂的场景中,每种物体都可能需要不同的渲染手法,每种渲染手法就需要这堆函数的不同顺序的组合调用,而每次渲染完一个,你还需要挨个清理掉,以便不影响后续的渲染调用。如果你熟悉Windows GDI的话,你就会发现之前的D3D接口在渲染状态编码的风格上与其十分类似,都是先设置一堆状态,然后绘制,最后再还原这一堆状态到之前的样子。代码上一样的令人作呕,因为一个不留神内存泄漏不说,并且渲染的结果通常也不会正确,所以调试起来像噩梦一样。
另一方面,过去的那种通过不同函数来设置渲染状态参数的方法,非常不利于固化(存储或加载)或脚本化封装(自定义脚本来灵活封装渲染管线),显得很不灵活。而这些对于现代化设计的游戏引擎来说是非常重要的特征。喜大普奔的是,在D3D12中,正如你所见的这些都只是初始化一个巨大的结构体即可。
PSO对象还带来一个更巨大的好处就是非常有利于多线程渲染,可以在不同的渲染线程之间方便的共享不同的PSO对象,而不用考虑怎样去灵活的封装这些渲染状态参数以便于共享。
其中shader简单可见如下:
struct PSInput
{
float4 position : SV_POSITION;
float4 color : COLOR;
};
PSInput VSMain(float4 position : POSITION, float4 color : COLOR)
{
PSInput result;
result.position = position;
result.color = color;
return result;
}
float4 PSMain(PSInput input) : SV_TARGET
{
return input.color;
}
九、加载待渲染数据(三角形顶点)
有了PSO我们就可以正式开始加载网格数据并开始渲染了。我想现在你应该猜到在D3D12中渲染也应该没那么简单吧?如果你猜到了,那说明通过前面的学习你已经有点适应D3D12为我们带来的空前的复杂性了,这很好,这说明你基本已经快爬到学习曲线的坡顶了。
开始正式渲染之前的最后一步就是加载资源了。因为我们要绘制一个三角形,所以我们就直接在代码中准备好这个三角形的数据,代码如下:
// 定义三角形的3D数据结构,每个顶点使用三原色之一
GRS_VERTEX triangleVertices[] =
{
{ { 0.0f, 0.25f * fAspectRatio, 0.0f }, { 1.0f, 0.0f, 0.0f, 1.0f } },
{ { 0.25f * fAspectRatio, -0.25f * fAspectRatio, 0.0f }, { 0.0f, 1.0f, 0.0f, 1.0f } },
{ { -0.25f * fAspectRatio, -0.25f * fAspectRatio, 0.0f }, { 0.0f, 0.0f, 1.0f, 1.0f } }
};
const UINT vertexBufferSize = sizeof(triangleVertices);
GRS_THROW_IF_FAILED(pID3DDevice->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(vertexBufferSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&pIVertexBuffer)));
UINT8* pVertexDataBegin = nullptr;
CD3DX12_RANGE readRange(0, 0);
GRS_THROW_IF_FAILED(pIVertexBuffer->Map(0, &readRange, reinterpret_cast<void**>(&pVertexDataBegin)));
memcpy(pVertexDataBegin, triangleVertices, sizeof(triangleVertices));
pIVertexBuffer->Unmap(0, nullptr);
stVertexBufferView.BufferLocation = pIVertexBuffer->GetGPUVirtualAddress();
stVertexBufferView.StrideInBytes = sizeof(GRS_VERTEX);
stVertexBufferView.SizeInBytes = vertexBufferSize;
上面的代码中,对于三角形的顶点,我们使用了三角形外接圆半径的形式参数化定义了它,这样方便我们调整三角形大小看效果。
接着一个重要的概念就又是与存储管理有关了,在这里就是资源管理了。基本上在D3D12渲染过程中需要的数据都可以被称为资源,在这段代码中我们需要的资源就是三角形的顶点数据,使用的函数是CreateCommittedResource。
首先在一般的场合下,比如我们这里的示例中都可以使用这一个函数来创建资源。其次这个函数是为数不多的几个内部还同步的D3D12函数之一,也就是当这个函数返回时,实际的资源也就分配好了,与我们在之前版本D3D中用的方法类似。因此这个函数返回后,我们就可以像传统做法一样,map然后memcpy数据最后unmap就完成了数据从CPU内存向显存的传递。
幸运的是,CD3DX12_RESOURCE_DESC这个结构体与它在D3D11或D3D9中的前辈很相似,你应该已经很熟悉它了。在后面的系列教程中我们还会详细讲解它的用法。而另一个类CD3DX12_HEAP_PROPERTIES就先暂时不要纠结了,知道在这里它就是为了封装D3D12_HEAP_TYPE_UPLOAD这个属性即可。Upload的意思就是从CPU内存上传到显存中的意思。
代码的最后三行,就是通过结构体对象描述清楚了这个资源的视图,目的是告诉GPU被描述的资源实际是Vertex Buffer。这也与之前的D3D版本中的做法有些区别。在传统的D3D中,是通过调用Device接口的函数明确的创建一个资源视图对象的,而在D3D12中只需要在结构体对象中说明即可,主要目的就是为了能够统一实现一个可固化或脚本化的灵活的资源视图对象,与之前说的PSO对象结构体对象来描述的目的相类似。
十、异步渲染原理及命令列表详解
我们做完了渲染管线及渲染管线状态准备工作,同时也“加载”完了我们需要渲染的三角形的数据,终于可以开始渲染了。当然因为D3D12本质上为了支持多线程渲染而采取了异步设计策略的缘故,渲染也与之前版本的D3D有较大的差别。
首先我们需要接触的有一个新的概念就是命令列表,它的接口是
ID3D12GraphicsCommandList。其实在D3D11中它的概念等价物就是 Deferred Device Context,而相应的D3D12中的Command Queues就对应D3D11中的Immediate Device Context。
顾名思义,命令列表其实就是为了记录CPU发给GPU的图形命令的,因此它里面的方法函数就是一个个图形命令了,我们逐一调用命令函数,它就按照我们调用的顺序记录了这些图形命令。
在D3D12中所有的图形命令函数即ID3D12GraphicsCommandList的接口方法都是异步的,就是说一调用就返回,甚至很多方法连返回值都没有,调用时不能判定函数调用是否正确,因为调用的时候函数并没有真正执行,仅是被记录,这个过程被称为录制(Record)。
最终当所有的命令都记录完毕后,必须发送至Command Queue中ExecuteCommandList方法后,也就是将命令列表作为参数传给这个函数,一个命令列表才能去执行。
为了安全控制,也就是防止因多线程渲染带来的不必要冲突,命令列表的状态被分为:录制状态和可Execute状态(也叫关闭状态),命令列表对象通常处在两个状态之一。
通常一个命令列表在被创建时是默认处于录制状态的,此状态下是不能被执行的。录制完成后我们调用命令列表对象的Close方法关闭它,它就变成了可执行状态,就可以提交给Command Queue(命令队列)的ExecuteCommandList方法去执行,待执行完毕后我们又调用命令列表的Reset方法使它恢复到记录状态即可。当然Reset之后,命令列表之前记录的命令也就丢失了,严格来说是这些命令被交给命令队列去执行了,而命令列表不在记录原来的命令了。要理解这个概念,让我们想象命令列表就是我们去饭馆吃饭时服务员用于填写你点的菜的菜单,而命令队列就是饭馆的厨房,当我们点完菜后服务员就将菜单交给了厨房,而他的手里就又是新的一页空白菜单,准备下一位客户点菜了。
理解了命令列表,那么我们还需要在刚才那个饭馆点菜的模型示例基础上进一步来思考一下,那就是我们点菜用的菜单纸是要提前准备的,并且它是需要动态分配的,虽然一般的都是固定大小的,但是也会有客人只点几样小菜,而整个菜单就有很多空白浪费了,也有很多客人可能因为点很多菜而使用了几页菜单纸。在D3D12中,用于最终记录这些命令的“菜单纸”就是命令分配器对象,其接口是ID3D12CommandAllocator。这也是D3D12中加入的诸多关于存储管理概念对象中的一个。从本质上讲,其实不论什么图形命令,最终都是需要GPU来执行,那么这个分配器我们可以理解为本质上是用来管理记录命令用的显存的。不过幸运的是目前这个接口的细节在D3D12的调用过程中是不用过多关注的,因为它目前的设计只是为了体现了命令分配这个概念,实质上并没有什么具体直接的方法需要我们去调用,我们要做的只是说需要创建它,并将它和某个命令列表捆在一起即可。
当然命令分配器和命令列表最好是一对一的,用刚才饭馆点菜模型示例来说,我们肯定希望每个服务员都单独拿一份菜单来给你点菜,所以以此来理解的话,你就明白一对一的意义了。我相信谁都不会喜欢自己点的菜和别人点的菜混在一起吧?
从另一方面说,之所以要这么一个有点像纯概念式的对象接口来表达分配命令存储管理的概念的真正意义何在呢?那就是为了多线程渲染。因为我已经不止一次的强调过D3D12中加入并强化的核心概念就是多线程渲染。注意真正引入多线程渲染是在D3D11中,只不过D3D11中仍然保留了同步化的渲染支持。同时D3D11的多线程渲染貌似用的并不多,也没什么名气,也或者是我孤陋寡闻了。
而在D3D12中,管你喜欢不喜欢,渲染已经完全是多线程化了。彻底整明白多线程渲染的基本编码方式就是这篇教程的核心目的了,这也是我们彻底征服D3D12的基础中的基础。所以这里我也要多费些篇幅。
了解多线程编程的开发者,应该很清楚一个概念,那就是,从本质上说多线程其实不难。比如在Windows上调用CreateThread(推荐__beginthread)就可以创建线程,而真正的难点在于如何安全的在多线程环境下使用内存。而在D3D12中,实质为了彻底实现强悍的多线程渲染,最终是加入了大量的存储管理的概念,编程的复杂性也来源于此。在这里实际命令分配器就是典型的存储管理概念的体现。在D3D12中我们一般是为每一个渲染线程创建一个命令列表和一个命令分配器,这样就像我们举得饭馆点菜的例子中一样,大一点的上规模的餐馆中,一般每桌都有专门的服务员为你点菜,并且人手一份菜单,而厨房则通常会有多位不同的厨师负责不同的菜品的烹饪。从这里也可以看出为什么D3D12中非要加入多线程渲染的,那就是为了高效率、高品质、高并行,也就是说你不是再像以前一样开一个也许只有一两个厨师三四个服务员的小餐馆了,而是像现在这样要开大型的餐厅了,几乎每个餐桌都有专门的服务员点菜(多线程生成多个命令列表),后台的厨房中则是n个厨师在并行的为不同桌的客人烹制菜品,甚至厨师的分工都被细化了,有些负责烹制西餐、有些负责粤菜、有些负责凉菜等等(多引擎),想象一下使用了多线程渲染之后,你的引擎也是在异曲同工的绘制复杂大型的场景的情景。而这一切都在高效的D3D12接口的支持下,有条不紊的进行。
十一、创建命令分配器接口、命令列表接口和栅栏对象接口
看过上面那段介绍,在概念上你已经消化吸收了多线程渲染的基本原理。当然在我们现在的例子中,还没有真正用起多线程渲染,将来我们就会用到。提前说这些的真实目的是因为D3D12本质全是异步的,所以我们还是需要将我们这个单线程例子,按照多线程渲染的套路来编写,这也是D3D12编程比较复杂的一个体现。首先我们要像下面这样创建一个命令分配器,然后在创建一个命令列表:
// 12、创建命令列表分配器
GRS_THROW_IF_FAILED(pID3DDevice->CreateCommandAllocator(
D3D12_COMMAND_LIST_TYPE_DIRECT
, IID_PPV_ARGS(&pICommandAllocator)));
// 13、创建图形命令列表
GRS_THROW_IF_FAILED(pID3DDevice->CreateCommandList(0
, D3D12_COMMAND_LIST_TYPE_DIRECT
, pICommandAllocator.Get()
, pIPipelineState.Get()
, IID_PPV_ARGS(&pICommandList)));
从上面代码再结合我们之前讲过的多引擎知识大家应该看明白我们创建了一个“直接”的命令分配器和命令列表,其“直接”的含义与直接命令队列的含义对应,就是用来分配和记录所有种类的命令的。同时在创建命令列表时,我们还要指出它对应的命令分配器对象的指针,这也就是一一对应含义的体现。
接下来因为我们本质上还是在用异步的思路来调用渲染的过程,所以我们就还需要创建控制CPU和GPU同步工作的同步对象——栅栏(Fence),代码如下:
// 14、创建一个同步对象——围栏,用于等待渲染完成,因为现在Draw Call是异步的了
GRS_THROW_IF_FAILED(pID3DDevice->CreateFence(0
, D3D12_FENCE_FLAG_NONE
, IID_PPV_ARGS(&pIFence)));
n64FenceValue = 1;
// 15、创建一个Event同步对象,用于等待围栏事件通知
hFenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);
if (hFenceEvent == nullptr)
{
GRS_THROW_IF_FAILED(HRESULT_FROM_WIN32(GetLastError()));
}
上述代码可以看出创建一个栅栏很简单,当然为了完成真正的同步控制(这里指CPU与GPU渲染间的同步,以后所说的同步都要结合上下文明白我们指的是什么同步),我们还要准备一个称为围栏值的64位无符号整数变量,在示例中就是n64FenceValue,和一个Event(事件)系统内核对象。在这里我们都是先准备好他们,后面我们就会真正用到它。
十二、渲染
终于最后一步就是我们进入消息循环调用渲染了,代码如下:
//创建定时器对象,以便于创建高效的消息循环
HANDLE phWait = CreateWaitableTimer(NULL, FALSE, NULL);
LARGE_INTEGER liDueTime = {};
liDueTime.QuadPart = -1i64;//1秒后开始计时
SetWaitableTimer(phWait, &liDueTime, 1, NULL, NULL, 0);//40ms的周期
//开始消息循环,并在其中不断渲染
DWORD dwRet = 0;
BOOL bExit = FALSE;
while (!bExit)
{
dwRet = ::MsgWaitForMultipleObjects(1, &phWait, FALSE, INFINITE, QS_ALLINPUT);
switch (dwRet - WAIT_OBJECT_0)
{
case 0:
case WAIT_TIMEOUT:
{//计时器时间到
//开始记录命令
pICommandList->SetGraphicsRootSignature(pIRootSignature.Get());
pICommandList->RSSetViewports(1, &stViewPort);
pICommandList->RSSetScissorRects(1, &stScissorRect);
// 通过资源屏障判定后缓冲已经切换完毕可以开始渲染了
pICommandList->ResourceBarrier(1
, &CD3DX12_RESOURCE_BARRIER::Transition(pIARenderTargets[nFrameIndex].Get()
, D3D12_RESOURCE_STATE_PRESENT
, D3D12_RESOURCE_STATE_RENDER_TARGET));
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHandle(pIRTVHeap->GetCPUDescriptorHandleForHeapStart()
, nFrameIndex
, nRTVDescriptorSize);
//设置渲染目标
pICommandList->OMSetRenderTargets(1, &rtvHandle, FALSE, nullptr);
// 继续记录命令,并真正开始新一帧的渲染
const float clearColor[] = { 0.0f, 0.2f, 0.4f, 1.0f };
pICommandList->ClearRenderTargetView(rtvHandle, clearColor, 0, nullptr);
pICommandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
pICommandList->IASetVertexBuffers(0, 1, &stVertexBufferView);
//Draw Call!!!
pICommandList->DrawInstanced(3, 1, 0, 0);
//又一个资源屏障,用于确定渲染已经结束可以提交画面去显示了
pICommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(pIARenderTargets[nFrameIndex].Get(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT));
//关闭命令列表,可以去执行了
GRS_THROW_IF_FAILED(pICommandList->Close());
//执行命令列表
ID3D12CommandList* ppCommandLists[] = { pICommandList.Get() };
pICommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
//提交画面
GRS_THROW_IF_FAILED(pISwapChain3->Present(1, 0));
//开始同步GPU与CPU的执行,先记录围栏标记值
const UINT64 fence = n64FenceValue;
GRS_THROW_IF_FAILED(pICommandQueue->Signal(pIFence.Get(), fence));
n64FenceValue++;
// 看命令有没有真正执行到围栏标记的这里,没有就利用事件去等待,注意使用的是命令队列对象的指针
if (pIFence->GetCompletedValue() < fence)
{
GRS_THROW_IF_FAILED(pIFence->SetEventOnCompletion(fence, hFenceEvent));
WaitForSingleObject(hFenceEvent, INFINITE);
}
//到这里说明一个命令队列完整的执行完了,在这里就代表我们的一帧已经渲染完了,接着准备执行下一帧//渲染
//获取新的后缓冲序号,因为Present真正完成时后缓冲的序号就更新了
nFrameIndex = pISwapChain3->GetCurrentBackBufferIndex();
//命令分配器先Reset一下
GRS_THROW_IF_FAILED(pICommandAllocator->Reset());
//Reset命令列表,并重新指定命令分配器和PSO对象
GRS_THROW_IF_FAILED(pICommandList->Reset(pICommandAllocator.Get(), pIPipelineState.Get()));
//GRS_TRACE(_T("第%u帧渲染结束.\n"), nFrame++);
}
break;
case 1:
{//处理消息
while (::PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
if (WM_QUIT != msg.message)
{
::TranslateMessage(&msg);
::DispatchMessage(&msg);
}
else
{
bExit = TRUE;
}
}
}
break;
default:
break;
}
}
代码中使用了一个精确定时的消息循环。
这里重点讲一下资源屏障的用法和意义。资源屏障的原理在之前Vulkan的文章中已经有过很形象的讲解了。在这段代码中有两处用到资源屏障,我们可以看到资源屏障的运用其实也很简单,它核心的思想就是追踪资源权限的变化,从而同步GPU上前后执行命令对访问资源的操作。代码中第一处:
pICommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(pIARenderTargets[nFrameIndex].Get(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET));
的确切含义就是说我们判定并等待完成渲染目标的资源是否完成了从Present(提交)状态切换到Render Target(渲染目标)状态了。ResourceBarrier是一个同步调用,与一般的同步调用不同,首先它在命令列表记录时也是立即返回的,只是个同步调用记录;其次它的目的是同步GPU上前后命令函数之间对同一资源的访问操作的,再次它真正在Execute之中才是同步执行的,而我们在CPU的代码中是感知不到的;我们唯一能确定的就是在Execute一个命令列表的过程中,如果它被真正执行完了之后,那么就完全可以确定被转换状态的资源已经从其之前命令函数操作要求的状态转换成了之后操作要求的状态了。或者形象的理解这个函数在正在被执行的时候是不能被“跳过”的。那么这里可能难以理解的是为什么说资源访问状态的切换就可以完成一个同步的“等待”操作呢?这就又不得不说GPU构造的特殊性了,因为如前所述我们已经不止一次讲到GPU是一个巨大的SIMD架构的处理器了,因此它上面的所谓命令的执行,往往是由若干个ALU(通常是成千上万个)并行执行访问具体的一个资源(其实就是一块显存)上不同单元来完成的,而且每种命令对同一块资源的访问要求又是完全不同的,比如我们这里就是Present操作,它是只读的要求,而渲染的命令又要求这块资源是Render Target,也就是可写的,所以两个操作直接就需要来回控制这种状态的切换,而GPU本身知道那个操作已经完成可以执行真正的状态切换了,而状态切换成功就说明之前操作已经全部完成,可以进行之后的操作了。这样一来其实Transition这个函数的含义也就明白了。当然这里的CD3DX12_RESOURCE_BARRIER类也是来自d3d12.h中,也是其基本结构的扩展,真实的结构体中就是要求我们指明是那块资源,并且指明之前操作要求的访问状态是什么,以及之后的访问状态是什么,而这个类的封装就使初始化这个结构体更加的简便和直观了。
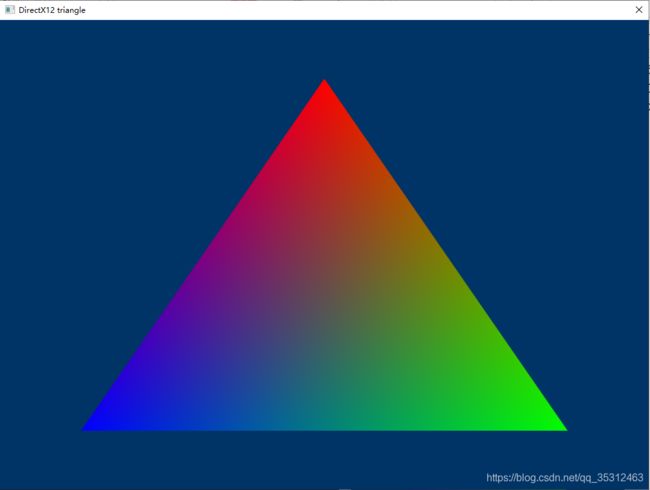
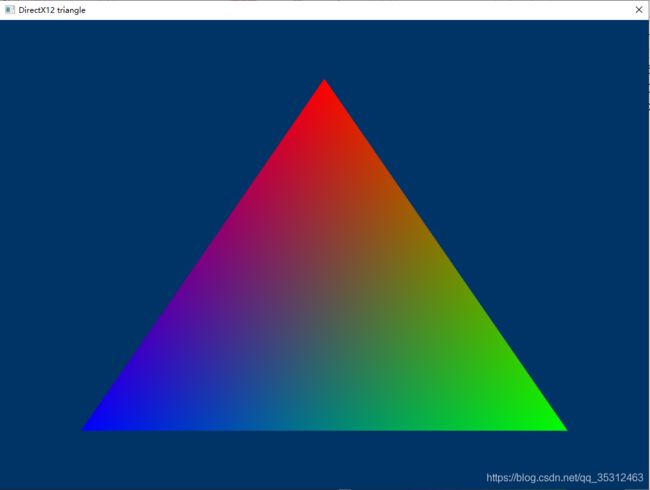
运行即可见如下结果: