Llama2部署、微调、集成Langchain过程记录
目录
一、模型部署
1. 环境配置
2. pip和conda源
3. 下载模型到本地
4. 下载并部署gradio
5. 使用gradio运行模型
6. text generation webui
二、模型微调
1. 下载和预处理微调训练数据
2. 运行微调文件
3. 执行代码合并
4. 使用gradio运行微调后模型
三、使用LangChain外挂本地知识库
1. LangChain介绍
2. 安装和准备
3. 设置知识库
4. 加载模型
5. 知识库的使用 和 构造prompt_template
四、Llama2+LangChain+Gradio部署
1. copy一份gradio_demo.py的文件
2. 加入LangChain的相关包
3. 修改setup()函数
4. 修改generate_prompt()函数
5. 修改predict()函数
6.执行gradio.py
一、模型部署
1. 环境配置
这部分环境配置不过多展开,可以搜一下网上详细教程有很多,注意cuda版本与torch版本对应,安装好conda(建议使用:Miniconda — miniconda documentation)后,在新创建的虚拟环境下进行实验。这里我的环境是:python 3.8.17 + cuda11.7 + torch 2.0.1。
conda常用命令:
创建虚拟环境:conda create -n 环境名称 python=版本号
查看已有虚拟环境:conda env list
激活虚拟环境:conda activate 环境名称
删除虚拟环境:conda remove -n 环境名称 --all
查看当前环境下已安装的包:conda list2. pip和conda源
建议更换南方科技大学的conda源 https://mirrors.sustech.edu.cn/help/anaconda.html#introduction 和pip源https://mirrors.sustech.edu.cn/help/pypi.html#_1-confirm-your-python-environment 具体操作步骤看链接内的说明。
https://mirrors.sustech.edu.cn/help/anaconda.html#introduction 和pip源https://mirrors.sustech.edu.cn/help/pypi.html#_1-confirm-your-python-environment 具体操作步骤看链接内的说明。
3. 下载模型到本地
git clone https://huggingface.co/FlagAlpha/Llama2-Chinese-7b-Chat
4. 下载并部署gradio
1. 把链接中的gradio_demo.py和requirements.txt下载到服务器(本文路径相关部分请根据自己的目录结构修改)https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/inference/gradio_demo.py
2.修改requrement.txt里的torch版本为2.0.1,然后安装requirements.txt:
pip install -r requirements.txt3. 把gradio.py里59、60、61行注释掉,然后手动安装gradio和gradio_demo.py里import的包;

安装gradio:
pip install gradio 安装bitsandbytes:
pip install bitsandbytes安装accelerate:
pip install accelerate安装scipy:
pip install scipy5. 使用gradio运行模型
cd llama-2
python gradio_demo.py --base_model /home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat --tokenizer_path /home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat --gpus 0 运行结果:(这里应该在llama-2文件夹下操作,截错图了)

(注:好像要开才能生成gradio的外部分享链接)
6. text generation webui
这也是一个图形化可交互的大模型Web UI,可以方便地与模型对话、下载模型、训练与微调等,官方给的一键式懒人安装也十分便捷。详细教程可参考下方链接:
oobabooga/text-generation-webui:A Gradio web UI for Large Language Models.支持变压器,GPTQ,美洲驼.cpp(GGUF),美洲驼模型。 (github.com)
中文Llama2 |部署记录——基于text-genration-webui - 知乎 (zhihu.com)
二、模型微调
1. 下载和预处理微调训练数据
1、我们使用BelleGroup提供的50w条中文数据,先下载到llm文件夹下:
cd llm
wget https://huggingface.co/datasets/BelleGroup/train_0.5M_CN/resolve/main/Belle_open_source_0.5M.json原始数据的预览如下{"instruction":"xxxx", "input":"", "output":"xxxx"}:
 2、新建一个文件:split_json.py,然后把下面的代码粘贴进去
2、新建一个文件:split_json.py,然后把下面的代码粘贴进去
import random,json
def write_txt(file_path,datas):
with open(file_path,"w",encoding="utf8") as f:
for d in datas:
f.write(json.dumps(d,ensure_ascii=False)+"\n")
f.close()
with open("/root/autodl-tmp/Belle_open_source_0.5M.json","r",encoding="utf8") as f:
lines=f.readlines()
#拼接数据
changed_data=[]
for l in lines:
l=json.loads(l)
changed_data.append({"text":"### Human: "+l["instruction"]+" ### Assistant: "+l["output"]})
#从拼好后的数据中,随机选出1000条,作为训练数据
#为了演示使用,我们只用1000条,生产环境至少要使用全部50w条
r_changed_data=random.sample(changed_data, 1000)
#写到json中
write_txt("/root/autodl-tmp/Belle_open_source_0.5M_changed_test.json",r_changed_data)
3、新建一个终端,执行下面的代码,把可以随机拆出1000条拼接好的数据给我们测试使用:
python split_json.py拼接好的数据格式如下图{"text":"### Human: xxxx ### Assistant: xxx"}:

2. 运行微调文件
创建一个jupyter notebook.
1、首先要执行安装程序,使用-U强制升级到最新版本
!pip install -q huggingface_hub
!pip install -q -U trl transformers accelerate peft
!pip install -q -U datasets bitsandbytes einops wandb2、登录HF的notebook,需要到:https://huggingface.co/settings/tokens 复制token

然后执行下面的语句,并把token粘贴到输入框里进行登录(需要服务器能)
from huggingface_hub import notebook_login
notebook_login() 

4、初始化wandb (wandb是一个免费的,用于记录实验数据的工具)
需要先到:https://wandb.me/wandb-server 注册wandb
然后到:https://wandb.ai/authorize 复制key出来
然后执行下面的语句后,把key输入到输入框里,回车即可
import wandb
wandb.init()

5、导入相关包
from datasets import load_dataset
import torch,einops
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArguments
from peft import LoraConfig
from trl import SFTTrainer6、加载上面拼接好之后的1000条数据
dataset = load_dataset("json",data_files="/home/yrgu/llm/Belle_open_source_0.5M_changed_test.json",split="train") 
7、配置本地模型
base_model_name ="/home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,#在4bit上,进行量化
bnb_4bit_use_double_quant=True,# 嵌套量化,每个参数可以多节省0.4位
bnb_4bit_quant_type="nf4",#NF4(normalized float)或纯FP4量化 博客说推荐NF4
bnb_4bit_compute_dtype=torch.float16,
)8、配置GPU
device_map = {"": 0}
#有多个gpu时,为:device_map = {"": [0,1,2,3……]}9、加载本地模型
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,#本地模型名称
quantization_config=bnb_config,#上面本地模型的配置
device_map=device_map,#使用GPU的编号
trust_remote_code=True,
use_auth_token=True
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1 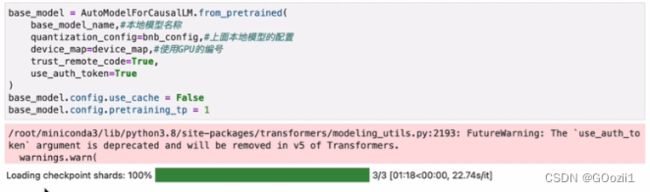
10、配置QLora
#参数是啥意思我也不知道,大家会调库就行了
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)11、对本地模型,把长文本拆成最小的单元词(即token)
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token12、训练参数的配置
output_dir = "./results"
training_args = TrainingArguments(
report_to="wandb",
output_dir=output_dir,#训练后输出目录
per_device_train_batch_size=4,#每个GPU的批处理数据量
gradient_accumulation_steps=4,#在执行反向传播/更新过程之前,要累积其梯度的更新步骤数
learning_rate=2e-4,#超参、初始学习率。太大模型不稳定,太小则模型不能收敛
logging_steps=10,#两个日志记录之间的更新步骤数
max_steps=100#要执行的训练步骤总数
)
max_seq_length = 512
#TrainingArguments 的参数详解:https://blog.csdn.net/qq_33293040/article/details/117376382
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_args,
) 
13、开始进行微调训练
trainer.train()
14、把训练好的模型,保存下来(一般最后一次checkpoint模型是训练效果最好的)
import os
output_dir = os.path.join(output_dir, "final_checkpoint")
trainer.model.save_pretrained(output_dir)3. 执行代码合并
1、新建一个merge_model.py的文件,把下面的代码粘贴进去:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
#设置原来本地模型的地址
model_name_or_path = '/home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat'
#设置微调后模型的地址,就是上面的那个地址
adapter_name_or_path = '/home/yrgu/llm/results/final_checkpoint'
#设置合并后模型的导出地址
save_path = '/home/yrgu/llm/new_model'
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
print("load model success")
model = PeftModel.from_pretrained(model, adapter_name_or_path)
print("load adapter success")
model = model.merge_and_unload()
print("merge success")
tokenizer.save_pretrained(save_path)
model.save_pretrained(save_path)
print("save done.")
2、新建终端,然后执行上述合并代码,进行合并
python merge_model.py
4. 使用gradio运行微调后模型
cd llama-2 #进入llama-2文件夹
python gradio_demo.py --base_model /home/yrgu/llm/new_model --tokenizer_path /home/yrgu/llm/new_model --gpus 0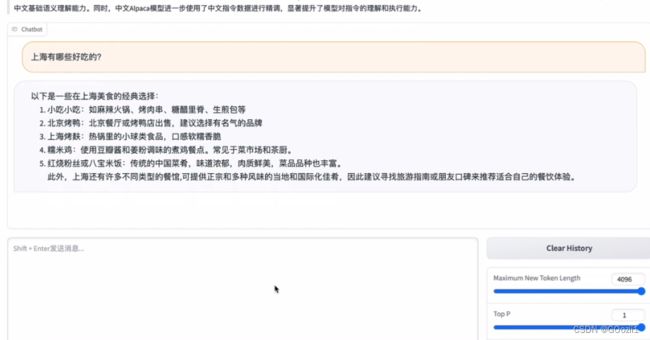
三、使用LangChain外挂本地知识库
1. LangChain介绍
LangChain是一个开源的框架,它可以让AI开发人员把像GPT-4这样的大型语言模型(LLM)和外部数据结合起来。它提供了Python或JavaScript(TypeScript)的包。
你可能知道,GPT模型是用到2021年的数据训练的,这可能会有很大的局限性。虽然这些模型的通用知识很棒,但是如果能让它们连接到自定义的数据和计算,就会有更多的可能性。这就是LangChain做的事情。
你可能觉得LangChain听起来很复杂,但其实它很容易上手。简单来说,LangChain就是把大量的数据组合起来,让LLM能够尽可能少地消耗计算力就能轻松地引用。它的工作原理是把一个大的数据源,比如一个50页的PDF文件,分成一块一块的,然后把它们嵌入到一个向量存储(Vector Store)里。

现在我们有了大文档的向量化表示,我们就可以用它和LLM一起工作,只检索我们需要引用的信息,来创建一个提示-完成(prompt-completion)对。
当我们把一个提示输入到我们新的聊天机器人里,LangChain就会在向量存储里查询相关的信息。你可以把它想象成一个专门为你的文档服务的小型谷歌。一旦找到了相关的信息,我们就用它和提示一起喂给LLM,生成我们的答案。
参考链接:LangChain:一个让你的LLM变得更强大的开源框架
2. 安装和准备
1、安装可能会用到的包
!pip install -U langchain unstructured nltk sentence_transformers faiss-gpu2、安装nltk(一个自然语言工具箱)的punkt模块(因为下载速度很慢,所以这里我们手动下载)
-
先在/home/yrgu目录下(按自己的来),建一个文件夹:/home/yrgu/nltk_data/tokenizers
-
到这个网址:http://www.nltk.org/nltk_data/,找到punkt的包

-
在刚创建的tokenizers目录下下载包:wget https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt.zip
- 解压包:unzip punkt.zip

3. 设置知识库
1、在jupyter notebook中导入相关包
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS2、在/home/yrgu/llm目录下创建一个knowledge.txt文件,放一些文本在里面。知识库其实本质上就是一段文本。这里我们使用unstructured这个包,把带格式的文本,读取为无格式的纯文本。
filepath="/home/yrgu/llm/knowledge.txt"
loader=UnstructuredFileLoader(filepath)
docs=loader.load()
#打印一下看看,返回的是一个列表,列表中的元素是Document类型
print(docs)
法律数据来源:中国法律数据集资源
3、对上面读取的文档进行chunk。chunk的意义在于,可以把长文本拆分成小段,以便搜索召回
chunk-size是文本最大的字符数。chunk-overlap是前后两个chunk的重叠部分最大字数。
text_splitter=RecursiveCharacterTextSplitter(chunk_size=50,chunk_overlap=10)
docs=text_splitter.split_documents(docs)
4、下载并部署embedding模型
cd /home/yrgu/llm
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
5、使用text2vec-large-chinese模型,对上面chunk后的doc进行embedding。然后使用FAISS存储到向量数据库
import os
embeddings=HuggingFaceEmbeddings(model_name="/home/yrgu/llm/text2vec-large-chinese", model_kwargs={'device': 'cuda'})
#如果之前没有本地的faiss仓库,就把doc读取到向量库后,再把向量库保存到本地
if os.path.exists("/home/yrgu/llm/my_faiss_store.faiss")==False:
vector_store=FAISS.from_documents(docs,embeddings)
vector_store.save_local("/home/yrgu/llm/my_faiss_store.faiss")
#如果本地已经有faiss仓库了,说明之前已经保存过了,就直接读取
else:
vector_store=FAISS.load_local("home/yrgu/llm/my_faiss_store.faiss",embeddings=embeddings)
#注意!!!!
#如果修改了知识库(knowledge.txt)里的内容
#则需要把原来的 my_faiss_store.faiss 删除后,重新生成向量库4. 加载模型
加载事件稍长,等待一会即可。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
#先做tokenizer
tokenizer = AutoTokenizer.from_pretrained('/home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat',trust_remote_code=True)
#加载本地基础模型
#low_cpu_mem_usage=True,
#load_in_8bit="load_in_8bit",
base_model = AutoModelForCausalLM.from_pretrained(
"/home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat",
torch_dtype=torch.float16,
device_map='auto',
trust_remote_code=True
)
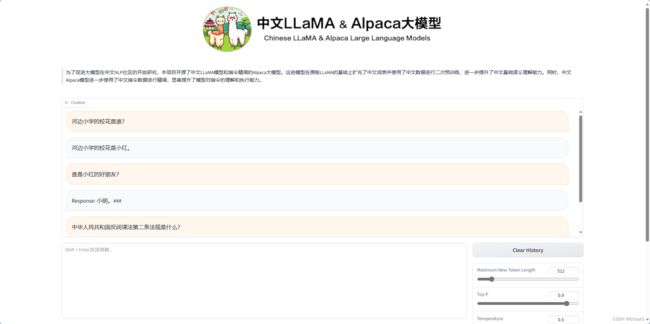
model=base_model.eval()5. 知识库的使用 和 构造prompt_template
1、通过用户问句,到向量库中,匹配相似度高的【知识】
query="河边小学的校花是谁?"
docs=vector_store.similarity_search(query)#计算相似度,并把相似度高的chunk放在前面
context=[doc.page_content for doc in docs]#提取chunk的文本内容
print(context)2、编写prompt_template;把查找到的【知识】和【用户的问题】都输入到prompt_template中
my_input="\n".join(context)
prompt=f"已知:\n{my_input}\n请回答:{query}"
print(prompt)3、把prompt输入模型进行预测
inputs = tokenizer([f"Human:{prompt}\nAssistant:"], return_tensors="pt")
input_ids = inputs["input_ids"].to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":1024,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3
}
generate_ids = model.generate(**generate_input)
new_tokens = tokenizer.decode(generate_ids[0], skip_special_tokens=True)
print("new_tokens",new_tokens)若运行成功可以看到输出了“河边小学的校花是小红”(这里忘记截图了),说明我们的外挂知识库生效了。下面结合gradio图形界面进行部署。
四、Llama2+LangChain+Gradio部署
1. copy一份gradio_demo.py的文件
把/home/yrgu/llm/llama-2/目录下的复制一份到/home/yrgu/llm/目录,并修改以下部分代码。
2. 加入LangChain的相关包
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS 3. 修改setup()函数
3. 修改setup()函数
-
setup()函数,是gradio的初始化函数,在这个函数里会使用gradio加载前端页面、并加载本地模型。
-
这里,我们在setup()函数中,对【知识】进行chunk切分,并存储到本地向量库。如果本地已有向量库,就直接读取本地向量库。
#把 vector_store 设置为全局变量 global tokenizer, model, device, share, port, max_memory, vector_store embeddings=HuggingFaceEmbeddings(model_name="/home/yrgu/llm/text2vec-large-chinese", model_kwargs={'device': 'cuda'}) #如果之前没有本地的faiss仓库,就把doc读取到向量库后,再把向量库保存到本地 if os.path.exists("/home/yrgu/llm/my_faiss_store.faiss")==False: #=======加载知识库======= filepath="knowledge.txt" loader=UnstructuredFileLoader(filepath) docs=loader.load() text_splitter=RecursiveCharacterTextSplitter(chunk_size=50,chunk_overlap=10) docs=text_splitter.split_documents(docs) vector_store=FAISS.from_documents(docs,embeddings) vector_store.save_local("/home/yrgu/llm/my_faiss_store.faiss") #如果本地已经有faiss仓库了,说明之前已经保存过了,就直接读取 else: vector_store=FAISS.load_local("/home/yrgu/llm/my_faiss_store.faiss",embeddings=embeddings)
4. 修改generate_prompt()函数
def generate_prompt(instruction,my_input):
return f"已知:{my_input}\n请问:{instruction}"
5. 修改predict()函数
#history的格式:[[query1,response1],[query2,response2],[query3,response3]……]
docs=vector_store.similarity_search(history[-1][0])
context=[doc.page_content for doc in docs]
#使用下面的方式,把多轮对话转为单轮对话
input = f"### Instruction:{history[-1][0]} ### Response:{history[-1][1]}"
prompt = generate_prompt(input,"".join(context))
6.执行gradio.py
python gradio_demo.py --base_model /home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat --tokenizer_path /home/yrgu/llm/model/FlagAlpha_Llama2-Chinese-7b-Chat --gpus 0
以上就是本文所有内容。