网络中的网络 NiN
目录
1.NiN
2.代码
1.NiN

卷积层的参数等于输入的通道数*输出的通道数乘以窗口的平方,然而全连接层的参数的大小等于输入的通道乘以图片的大小乘以输出的通道数。全连接层的参数很多,占用很多的内存,占用很多的计算带宽,很容易出现过拟合。收敛会特别快,可以做大一点的正则化不要一层把所有的东西都学到了。NiN的思想就是完全不要全连接层。
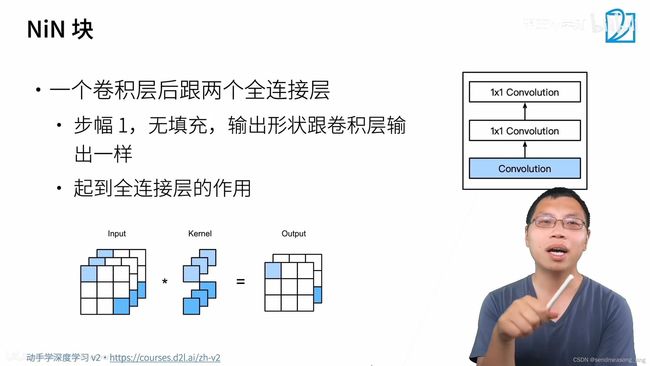
1*1的卷积层等价于全连接层,不会改变输入的形状。

对每一个通道拿出最大的值,如果类是1000类的话,最后的全局池化层输入的通道是1000的话,就把这1000个通道中拿到的值当作这个类别的预测,再加个softmax就会得到概率。最后也不需要使用全连接层。

2.代码
import torch
from torch import nn
from d2l import torch as d2l
"""NiN块"""
def nin_block(in_chanels,out_chanels,kernel_size,strides,padding):
return nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),nn.ReLU())
"""NiN模型"""
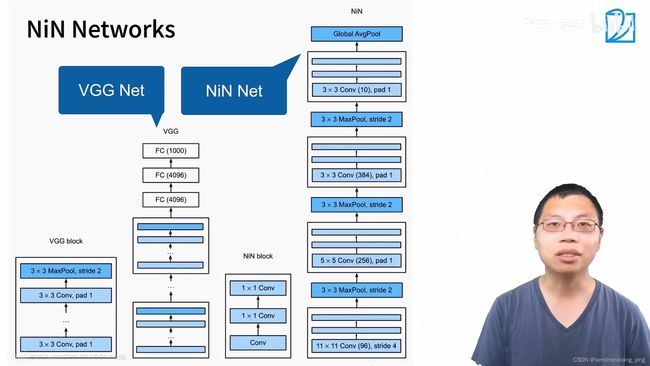
# NiN使用窗口形状为11*11,5*5和3*3的卷积层,输出通道数量与AlexNet中的相同.每个NiN块
#后有一个最大汇聚层,汇聚窗口形状为3*3,步幅为2。NiN和AlexNet之间的一个显著区别是NiN完全
#取消了全连接层。 相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平
#均汇聚层(global average pooling layer),生成一个对数几率 (logits)。NiN设计的一个
#优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
net=nn.Sequential(
nin_block(1,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(3,stride=2),
nin_block(96,256,keinel_size=5,strides=1,padding=2),
MaxPool2d(3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384,10,kernel_size=3,strides=1,padding=1),
nn.AdaptiveAvgPool2d(1,1))
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten()
#创建一个数据样本来查看每个块的输出形状。
X=torch.randn(size=(1,1,224,242))
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape\t',X.shape)
"""结果输出:
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
"""
"""训练模型"""
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
"""结果输出:
loss 0.563, train acc 0.786, test acc 0.790
3087.6 examples/sec on cuda:0"""
