世界人口数据分析与探索
文章目录
- 世界人口数据集介绍
-
- 数据集 1:世界国家统计数据:
- 数据集 2:世界人口详细信息(2023 年):
- 数据集 3:按年份划分的世界人口(1950-2023):
- 数据分析
-
- 导入必要的库
- 导入准备分析的文件
-
- 获取基本信息
- 数据可视化
-
- 土地面积分析
- 人口分析
- 生育率分析
- 中位年龄分析
- 结论
世界人口数据集介绍
探索全面的数据集,提供对全球人口统计和特定国家特征的深刻见解。这些数据集来源于worldometers.info和维基百科等知名平台,涵盖了广泛的关键指标,为深入分析和探索提供了丰富的资源。
数据集 1:世界国家统计数据:
深入研究世界各国的详细统计数据,包括地区、土地面积、生育率和中位年龄等基本因素。该数据集提供了人口和地理属性的整体视图。
数据集 2:世界人口详细信息(2023 年):
深入了解 2023 年各国的人口格局。该数据集涵盖了大量与人口相关的详细信息,包括年度变化、密度、净移民、城市人口等。
数据集 3:按年份划分的世界人口(1950-2023):
揭示 1950 年至 2023 年世界人口的演变(每个国家的年度粒度)。该数据集可让您分析和了解七十年来的人口趋势。
这些数据集共同为寻求探索和了解全球人口和特定国家特征的复杂动态的研究人员、分析师和爱好者奠定了坚实的基础。无论是研究历史趋势还是关注最新的人口统计资料,这些数据集都为不同的分析视角提供了丰富的信息。
注意
此数据集是从worldometers和wikipedia.org创建的。如果您想了解更多信息,可以访问网站。
数据分析
导入必要的库
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
导入准备分析的文件
countries_df=pd.read_csv('/input/world-population-dataset/world_country_stats.csv')
population_df=pd.read_csv('/input/world-population-dataset/world_population_by_country_2023.csv')
population_by_year=pd.read_csv('/input/world-population-dataset/world_population_by_year_1950_2023.csv')
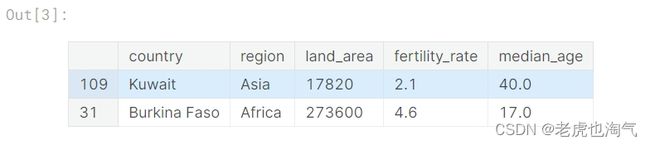
从名为"countries_df"中随机抽取2行数据进行随机抽样,以便更好地了解数据的特征和分布。
countries_df.sample(2)
获取基本信息
countries_df.info()
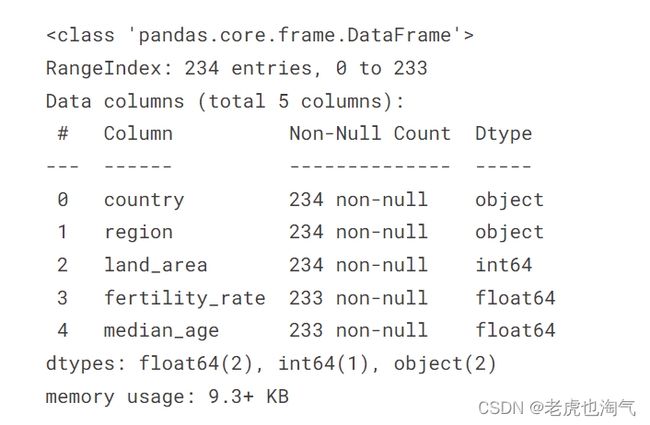
通过info()可以看出
从输出结果来看,数据框包含五列:
- country: 字符串类型,包含 234 个非空值。
- region: 字符串类型,包含 234 个非空值。
- land_area: 整数类型,包含 234 个非空值。
- fertility_rate: 浮点数类型,包含 233 个非空值。
- median_age:浮点数类型,包含 233 个非空值。
其中, fertility_rate,median_age各有一个缺失值。
countries_df.describe()
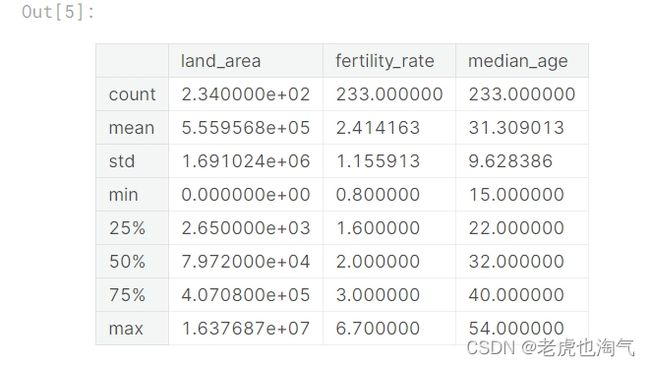
分析结果可知:
land_area:
平均面积约为 555,956.8 平方单位
标准差为 1,691,024,表示面积的变化范围较大
最小面积为 0,最大面积为 16,376,870
fertility_rate:
平均生育率为 2.41
标准差为 1.16,表示生育率的相对变异性
最低生育率为 0.8,最高生育率为 6.7
median_age:
平均年龄为 31.31
标准差为 9.63,表示年龄的相对变异性
最小年龄为 15,最大年龄为 54
计算每列中的缺失值数量
countries_df.isnull().sum()
获得每列中缺失值的总数。

查看完整的 countries_df 数据
countries_df
数据可视化
我将使用plotly来绘制大部分图。 Plotly 是一个数据可视化库,允许用户使用 Python、R 和 Julia 创建交互式动态图表。 它提供了一个高级界面,用于创建各种图表和图形,包括折线图、条形图、散点图、热图等。 您可以使用每个图右上角显示的工具与图进行交互
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
土地面积分析
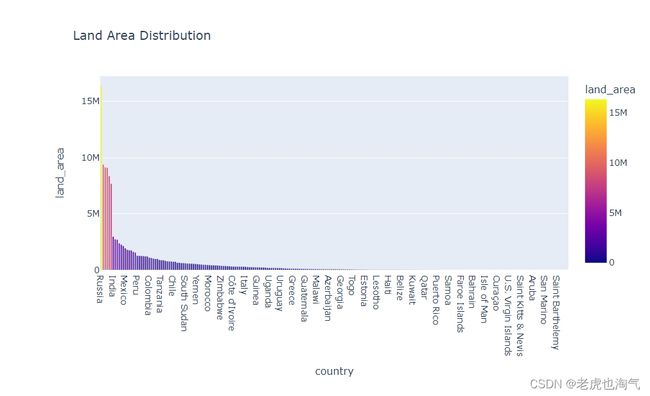
创建了一个条形图,该图显示了国家的土地面积分布
fig=px.bar(countries_df.sort_values(by='land_area',ascending=False),y='land_area',x='country',color='land_area',title='Land Area Distribution')
fig.show()
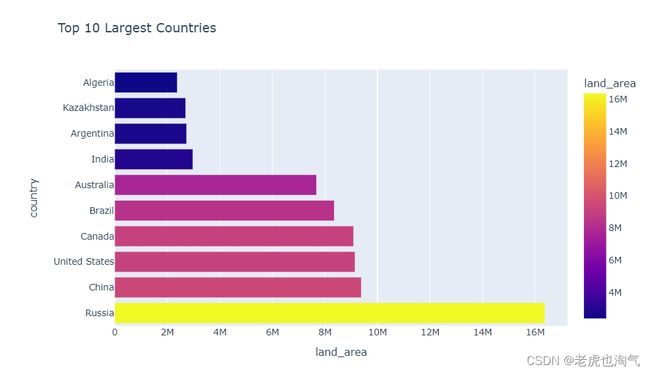
创建了一个条形图,显示了土地面积最大的前十个国家。通过使用 head(10) 来仅选择前十个最大的国家,并调整了x轴和y轴。
fig=px.bar(countries_df.sort_values(by='land_area',ascending=False).head(10),x='land_area',y='country',color='land_area',title='Top 10 Largest Countries')
fig.show()
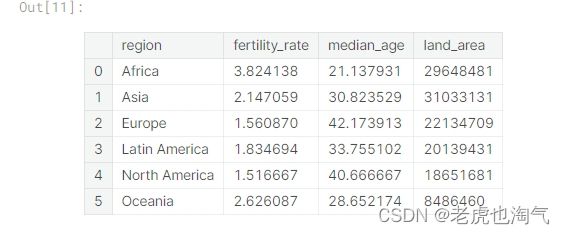
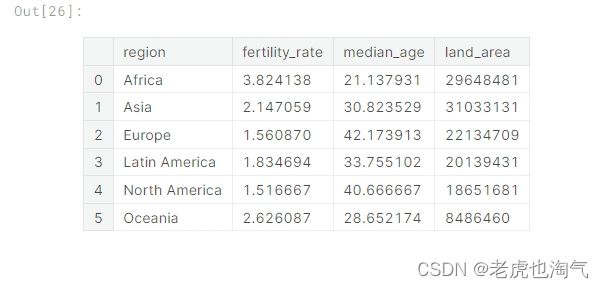
创建了一个名为 Region_df 的新数据框,通过使用 groupby 按照地区进行分组,并使用 agg 计算了每个地区的平均生育率、平均年龄和总土地面积。reset_index() 用于将地区作为列重新设置为索引。
Region_df=countries_df.groupby(by='region').agg({'fertility_rate':'mean','median_age':'mean','land_area':'sum'}).reset_index()
Region_df
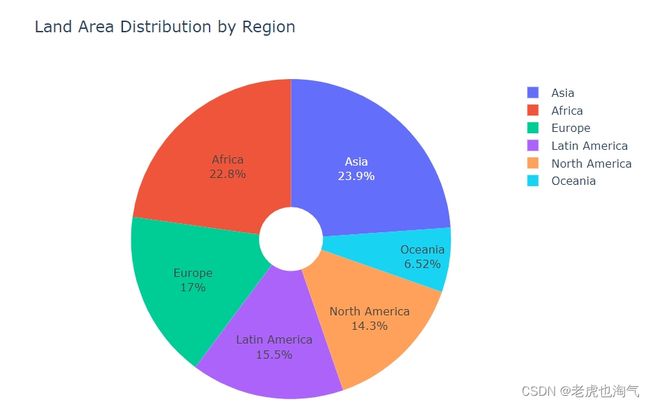
创建了一个饼图,展示了各个地区的土地面积分布。通过设置 names 参数为 ‘region’,values 参数为 ‘land_area’,并添加 hole 参数以创建一个带有中空部分的饼图。
fig=px.pie(Region_df,names='region',values='land_area',hole=0.2,title='Land Area Distribution by Region')
fig.update_traces(textinfo='label+percent')
fig.show()
使用 countries_df[‘region’].unique() 获取了数据框中 ‘region’ 列的唯一值,并将其转换为列表。这样可以得到包含所有地区名称的列表。
region=list(countries_df['region'].unique())
region

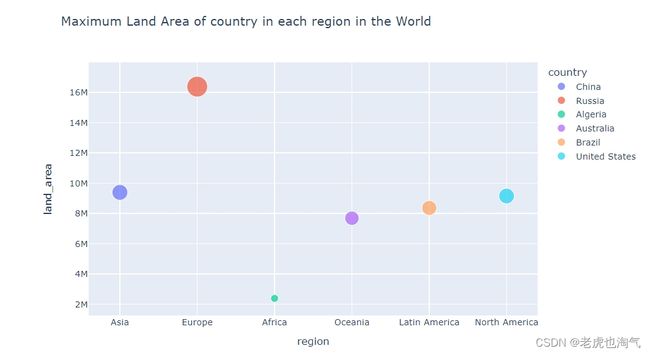
创建了一个新的数据框 x,通过迭代每个地区,选择每个地区土地面积最大的国家,并将这些信息存储在 x 中。您使用了 concat 函数将每个地区的数据框连接在一起,并通过 ignore_index=True 重新设置索引。
x=pd.DataFrame()
for reg in region:
temp_df=countries_df[countries_df['region']==reg].sort_values(by='land_area',ascending=False).head(1)[['region','country','land_area']]
x=pd.concat([x,temp_df],ignore_index=True)
x
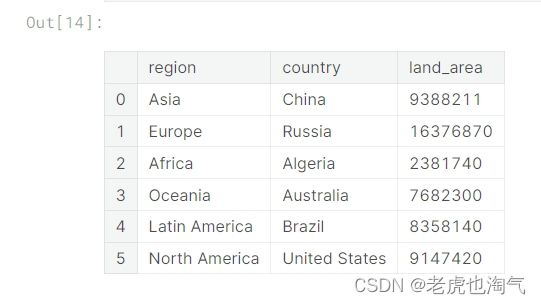
创建了一个散点图,显示了每个地区土地面积最大的国家。使用 px.scatter 函数,设置 x 轴为 ‘region’,y 轴为 ‘land_area’,颜色按照 ‘country’ 区分,而大小则由 ‘land_area’ 决定。
fig = px.scatter(x,x='region',y='land_area', color="country",size='land_area',title='Maximum Land Area of country in each region in the World')
fig.show()
人口分析
查看数据集中的三行样本数据
population_df.sample(3)

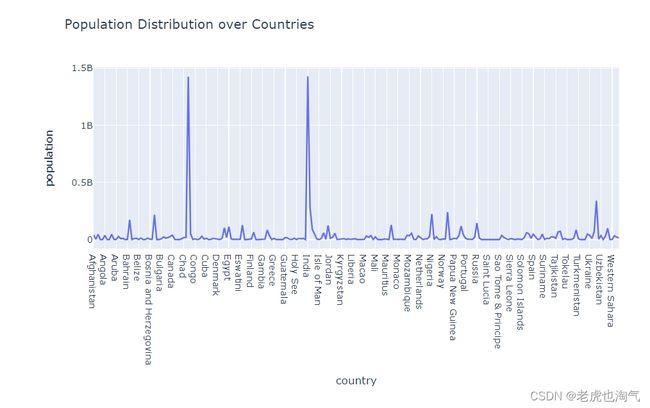
创建了一个折线图,展示了各个国家的人口分布。通过设置 x 轴为 ‘country’,y 轴为 ‘population’,可以很容易地观察到不同国家的人口变化趋势。
fig=px.line(population_df,x='country',y='population',title='Population Distribution over Countries')
fig.show()
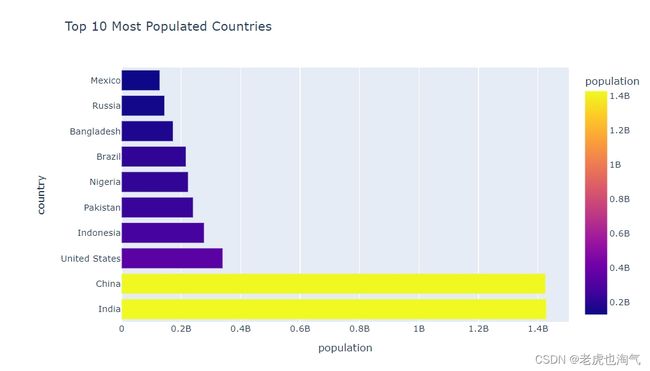
创建了一个条形图,显示了人口最多的前十个国家。通过使用 head(10) 来选择人口最多的前十个国家,并设置 x 轴为 ‘population’,y 轴为 ‘country’,颜色由 ‘population’ 决定。
fig=px.bar(population_df.sort_values(by='population',ascending=False).head(10),x='population',y='country',color='population',title='Top 10 Most Populated Countries')
fig.show()
查看 population_df 数据框中的两行样本数据
population_df.sample(2)

创建了两个条形图,分别显示了最城市化的前15个国家和最不城市化的前15个国家的城市人口分布。通过使用 sort_values 和 head(15) 来选择相应的国家,并设置 x 轴为 ‘population_urban’,y 轴为 ‘country’,颜色由 ‘population_urban’ 决定
fig=px.bar(population_df.sort_values(by='population_urban',ascending=False).head(15),x='population_urban',y='country',color='population_urban',title='Top 15 Most Urbanized Countries: Urban Population Distribution')
fig.show()
fig=px.bar(population_df.sort_values(by='population_urban',ascending=True).head(15),x='population_urban',y='country',color='population_urban',title='Least Urbanized Countries: Urban Population Distribution (Top 15)')
fig.show()
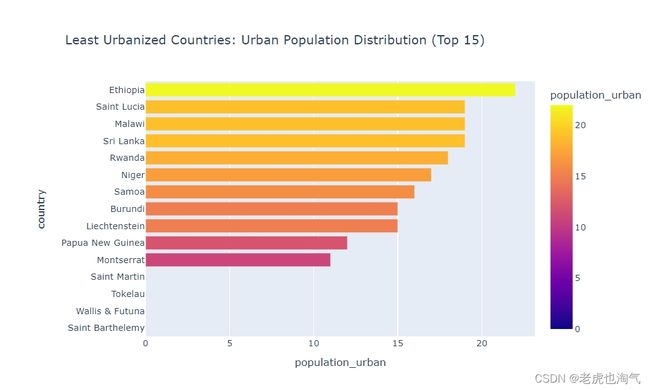
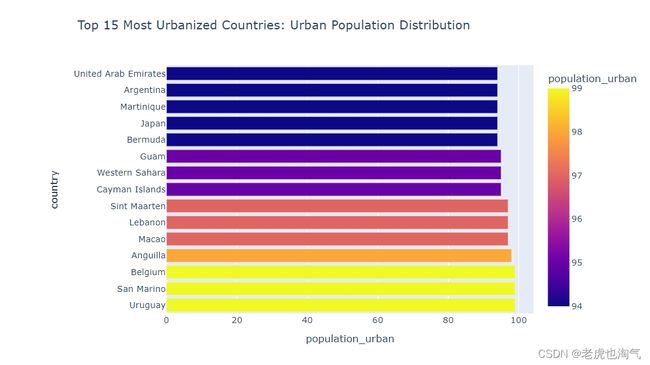
查看 population_by_year 数据框中的两行样本数据
population_by_year.sample(2)

创建了两个条形图,分别显示了1950年和2023年人口最多的前15个国家。通过使用 sort_values 和 head(15) 来选择相应的国家,并设置 x 轴为 ‘country’,y 轴为 ‘1950’ 或 ‘2023’。
fig , axes= plt.subplots(nrows=1,ncols=2 ,figsize=(25,10))
sns.barplot(population_by_year.sort_values(by='1950',ascending=False).head(15),x='country',y='1950',ax=axes[0])
axes[0].set_title('Most Populated countries in 1950')
axes[0].set_xticklabels(axes[0].get_xticklabels(),rotation=90)
sns.barplot(population_by_year.sort_values(by='2023',ascending=False).head(15),x='country',y='2023',ax=axes[1])
axes[1].set_title('Most Populated countries in 2023')
axes[1].set_xticklabels(axes[1].get_xticklabels(),rotation=90)
plt.show()
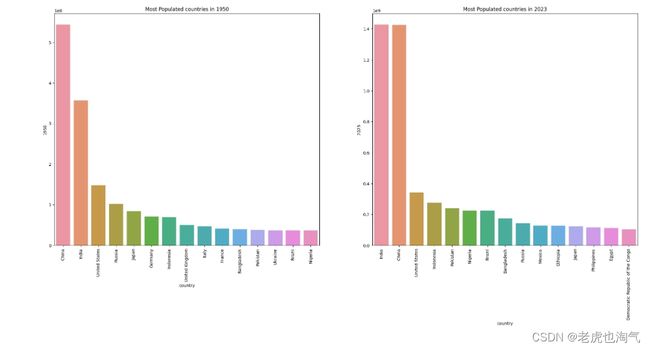
上面两张图是1950年和2023年的人口比较,我们可以看到中国和印度是1950年以来人口最多的国家
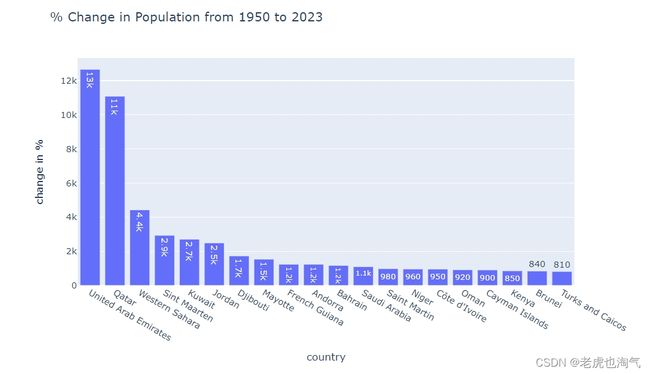
计算从1950年到2023年人口变化的百分比,并创建了一个显示前20个国家变化百分比的条形图。使用 px.bar 函数,设置 x 轴为 ‘country’,y 轴为 ‘change in %’,并设置标题为 ‘% Change in Population from 1950 to 2023’。
population_by_year['change in % ']=((population_by_year['2023']-population_by_year['1950'])/population_by_year['1950'])*100
z=population_by_year.sort_values(by='change in % ',ascending=False).head(20)
px.bar(z,x='country',y='change in % ',text_auto='0.2s',title='% Change in Population from 1950 to 2023 ')
生育率分析
countries_df.sample(2)
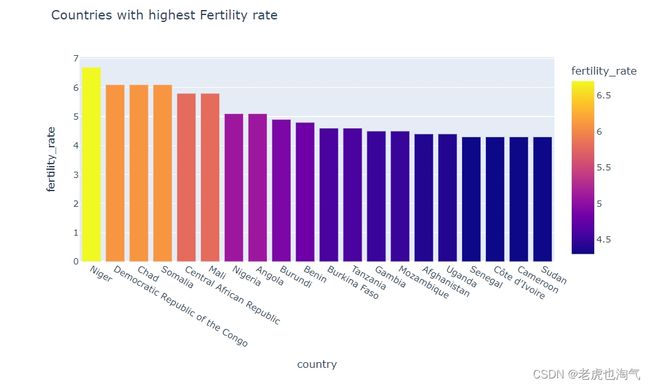
创建了一个条形图,显示了生育率最高的前20个国家。通过使用 sort_values 和 head(20) 来选择生育率最高的国家,并设置 x 轴为 ‘country’,y 轴为 ‘fertility_rate’,颜色由 ‘fertility_rate’ 决定。
fig=px.bar(countries_df.sort_values(by='fertility_rate',ascending=False).head(20),x='country',y='fertility_rate',color='fertility_rate',title='Countries with highest Fertility rate')
fig.show()
Region_df
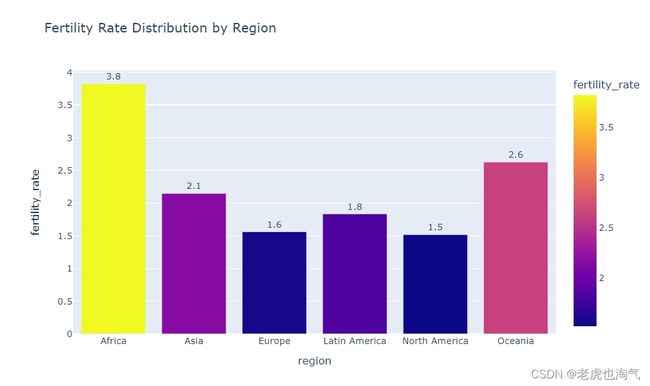
创建了一个条形图,显示了各个地区的生育率分布。通过设置 y 轴为 ‘fertility_rate’,x 轴为 ‘region’,颜色由 ‘fertility_rate’ 决定,并更新了一些文本显示的样式。
fig=px.bar(Region_df,y='fertility_rate',x='region',color='fertility_rate',text_auto='0.2s',title='Fertility Rate Distribution by Region')
fig.update_traces(textfont_size=12, textangle=0, textposition="outside", cliponaxis=False)
fig.show()
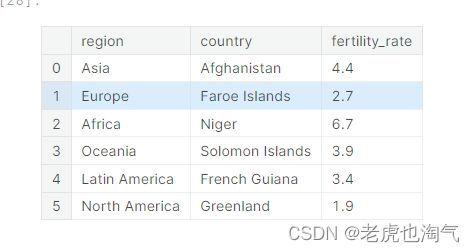
创建了一个名为 y 的新数据框,通过迭代每个地区,选择每个地区生育率最高的国家,并将这些信息存储在 y 中。使用了 concat 函数将每个地区的数据框连接在一起,并通过 ignore_index=True 重新设置索引。
y=pd.DataFrame()
for reg in region:
temp_df=countries_df[countries_df['region']==reg].sort_values(by='fertility_rate',ascending=False).head(1)[['region','country','fertility_rate']]
y=pd.concat([y,temp_df],ignore_index=True)
y
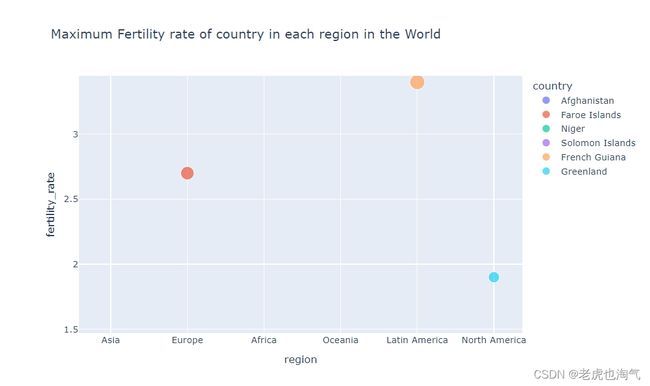
创建了一个散点图,显示了每个地区生育率最高的国家。使用 px.scatter 函数,设置 x 轴为 ‘region’,y 轴为 ‘fertility_rate’,颜色按照 ‘country’ 区分,而大小则由 ‘fertility_rate’ 决定
fig = px.scatter(y,x='region',y='fertility_rate', color="country",size='fertility_rate',title='Maximum Fertility rate of country in each region in the World')
fig.show()
中位年龄分析
countries_df.sample(2)
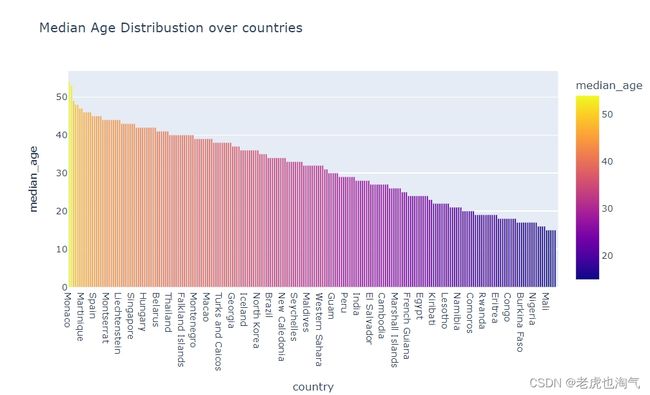
创建一个条形图,显示了各个国家的中位年龄分布。通过使用 sort_values 函数来按中位年龄排序,并设置 x 轴为 ‘country’,y 轴为 ‘median_age’,颜色由 ‘median_age’ 决定。
fig=px.bar(countries_df.sort_values(by='median_age',ascending=False),x='country',y='median_age',color='median_age',title='Median Age Distribustion over countries')
fig.show()
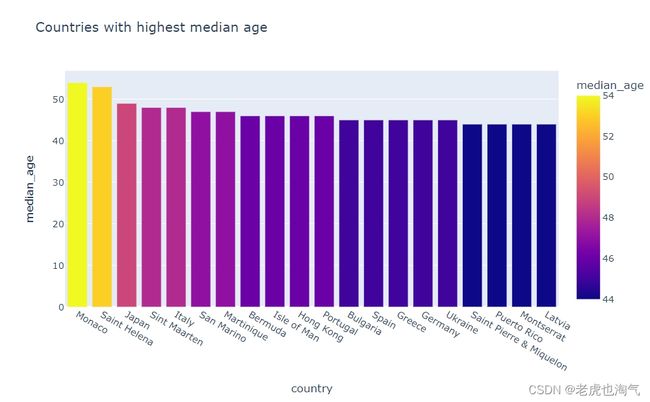
创建一个条形图,显示了中位年龄最高的前20个国家。通过使用 head(20) 来选择中位年龄最高的国家,并设置 x 轴为 ‘country’,y 轴为 ‘median_age’,颜色由 ‘median_age’ 决定。
fig=px.bar(countries_df.sort_values(by='median_age',ascending=False).head(20),x='country',y='median_age',color='median_age',title='Countries with highest median age')
fig.show()
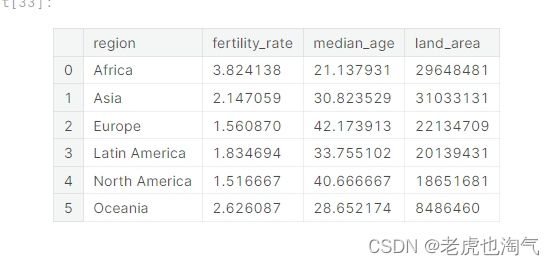
Region_df
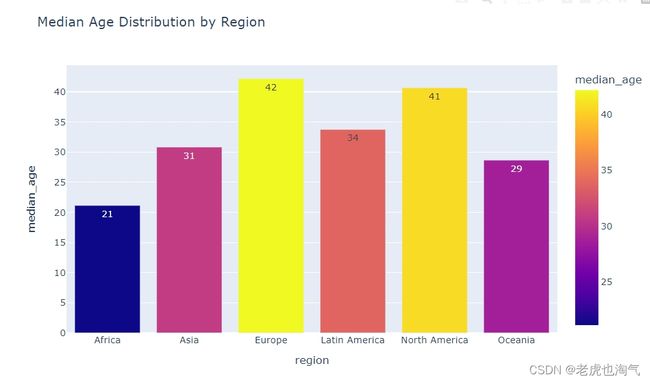
创建一个条形图,显示了各个地区的中位年龄分布。通过设置 y 轴为 ‘median_age’,x 轴为 ‘region’,颜色由 ‘median_age’ 决定,并更新了一些文本显示的样式。
fig=px.bar(Region_df,y='median_age',x='region',color='median_age',text_auto='0.2s',title=' Median Age Distribution by Region ')
fig.show()
结论
- 土地面积:
世界各国土地面积差异很大,Rssia拥有巨大的土地面积,接下来是China和US,而其他国家相对较小。
- 人口:
人口分布差异明显,印度,中国,美国拥有大量人口,而其他国家人口较少。
1950年和2023年的人口最多的国家也有所变化,反映了人口分布的演变。
- 城市化:
一些国家在城市化方面表现出色,其城市人口较多,

而其他国家则相对较少。
- 生育率:
生育率在不同国家和地区之间存在差异,一些国家生育率较高,而其他国家则较低。
- 中位年龄:
中位年龄在不同国家和地区之间存在差异,一些国家中位年龄较高,而其他国家则较低。
- 地区差异:
同一地区内的国家在人口、城市化、生育率和中位年龄等方面可能存在差异。
这里只提供一些简单的分析和思路,具体的分析还需要大家多角度深入的展开研究。