哈希表_day5
哈希表
1.链表和数组比较
数组:寻址容易,插入和删除元素困难
链表:寻址困难,插入和删除元素容易
2.哈希表的基础知识
哈希表(Hash Table):也叫做散列表。是根据关键码值(Key Value)直接进行访问的数据结构。
哈希表不再使用索引,而是使用键值对的方式进行访问。数组里面的索引是整数,可以通过这个整数找到内存地址,哈希表的键可以是整数或者字符串,不会对应相应的内存地址。这个键可以通过运算后找到内存地址,运算方式为哈希函数这个内存地址。

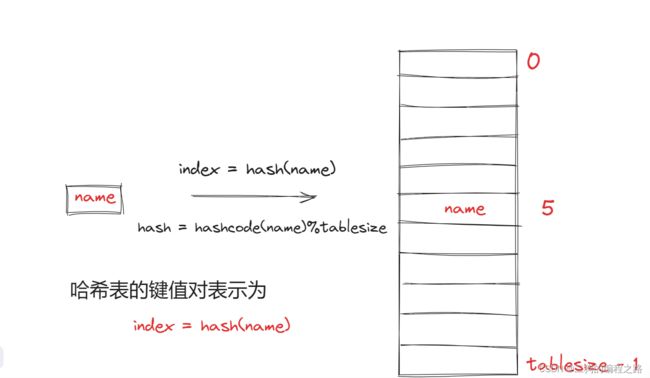
哈希函数的冲突是必然存在的,当出现狼多肉少的情况,无法避免,解决哈希冲突有两种方法。
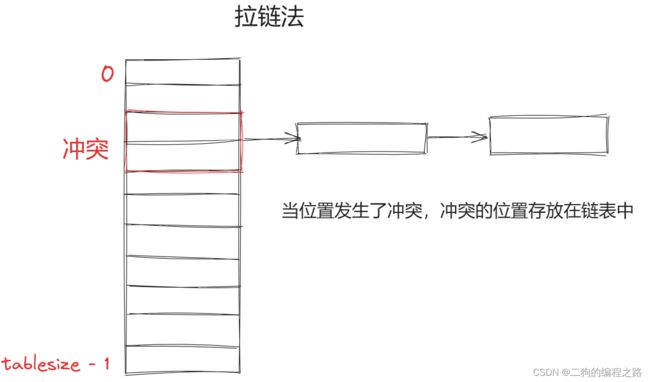
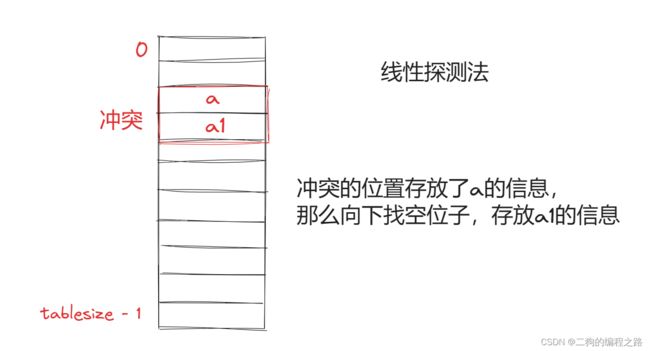
哈希表的关键思想是使用哈希函数,将键 key 映射到对应表的某个区块中。我们可以将算法思想分为两个部分:
- 向哈希表中插入一个关键码值:哈希函数决定该关键字的对应值应该存放到表中的哪个区块,并将对应值存放到该区块中。
- 在哈希表中搜索一个关键码值:使用相同的哈希函数从哈希表中查找对应的区块,并在特定的区块搜索该关键字对应的值。
3.常见的哈希表的区别:数组 、set (集合)、map(映射)
哈希表、数组、Set和Map是常见的数据结构,它们之间的区别主要体现在存储方式、是否保证元素唯一性、是否有序等方面。
首先,哈希表是一种根据键值直接进行访问的数据结构,可以实现O(1)的时间复杂度进行查找。其底层实现可以使用数组或红黑树。而数组是一种线性表数据结构,它通过下标来访问元素,时间复杂度为O(n)。
其次,Set和Map都继承自哈希表,但有一些区别。Set不能存放重复元素,无序的,只允许一个null;而Map则保存键值对映射。具体到Java,Set的底层实现有基于哈希存储和红黑树两种方式,而Map的HashMap版本底层也是哈希表,线程不安全的,效率高。
最后,如果需要集合有序就是用set,要求不仅有序还要数据可重复就是用multiset。map是键值对的存储方式,其中key是按照红黑树的方式进行存储。总的来说,选择哪种数据结构取决于具体的需求和应用场景。
4.set的详细介绍
Java中的Set是一种不允许重复元素的集合。有三种常用的Set类型:HashSet、TreeSet和LinkedHashSet,他们在使用和性能上各有不同。
- HashSet: 它是基于哈希表实现的,所以它的添加、删除和查找操作的时间复杂度都是O(1)。这意味着HashSet能提供快速的访问。当您需要一个能快速访问的Set时,可以选择HashSet。
- TreeSet: TreeSet是基于红黑树实现的,它能保持元素有序。因此,如果您需要一个有序的Set,那么TreeSet是一个好的选择。需要注意的是,由于TreeSet需要维持元素的顺序,因此插入和删除的操作时间复杂度为O(log n)。
- LinkedHashSet: LinkedHashSet也是基于哈希表实现的,但它内部使用双向链表来维护元素的插入顺序。因此,如果您需要记录插入元素的顺序,那么可以选择LinkedHashSet。
hashset简单实现代码
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
// 创建一个HashSet对象
HashSet<String> set = new HashSet<>();
// 向HashSet中添加元素
set.add("apple");
set.add("banana");
set.add("orange");
// 输出HashSet中的元素
System.out.println("HashSet: " + set);
// 检查HashSet中是否包含某个元素
boolean containsApple = set.contains("apple");
System.out.println("Contains 'apple': " + containsApple);
// 从HashSet中删除某个元素
set.remove("banana");
System.out.println("After removing 'banana': " + set);
// 获取HashSet的大小
int size = set.size();
System.out.println("Size of HashSet: " + size);
// 清空HashSet
set.clear();
System.out.println("After clearing: " + set);
}
}
5.力扣242
给定两个字符串 *s* 和 *t* ,编写一个函数来判断 *t* 是否是 *s* 的字母异位词。
**注意:**若 *s* 和 *t* 中每个字符出现的次数都相同,则称 *s* 和 *t* 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
示例 2:
输入: s = "rat", t = "car"
输出: false
提示:
1 <= s.length, t.length <= 5 * 104s和t仅包含小写字母
进阶: 如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
**思路解析:**判断是否是字母异位词,首先判断字符串的长度是否相同,然后进行比较,这里我直接创建了一个足够大的数组,借助哈希表实现。分别进行遍历,第一次遍历加1,第二次遍历减1。如果之前的数组为空,那么为字母异位词,反之则不然
import java.util.Arrays;
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] hash = new int[65536];
int len = s.length();
for(int i = 0 ; i <len ;i++){
char ch = s.charAt(i);
int temp = (int)ch ;
++hash[temp];
}
for(int i = 0 ; i < len ;i++){
char ch = t.charAt(i);
int temp = (int)ch ;
--hash[temp];
}
for (int i: hash) {
if (i!= 0) {
return false;
}
}
return true;
}
}
6.力扣349
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
**思路解析:**思路和上面几乎一样。
List 表示创建了一个名为resList的整数类型列表(List)。
List:这是Java中的一个接口,用于表示一个有序的元素集合。它继承自Collection接口,并提供了添加、删除、获取元素等基本操作。ArrayList:这是Java中的一个类,实现了List接口。它是一个动态数组,可以根据需要自动调整大小。当列表中的元素数量增加或减少时,它会自动分配更多的内存空间来存储这些元素。new ArrayList<>();:这是创建一个空的ArrayList实例的语法。括号内的部分表示我们希望这个列表中的元素类型是整数(Integer)。如果不指定泛型参数,那么默认情况下,列表中的元素类型将是Object。
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
int[] hash1 = new int[1002];
int[] hash2 = new int[1002];
for(int i : nums1)
hash1[i]++;
for(int i : nums2)
hash2[i]++;
List<Integer> resList = new ArrayList<>();
for(int i = 0; i < 1002; i++)
if(hash1[i] > 0 && hash2[i] > 0)
resList.add(i);
int index = 0;
int res[] = new int[resList.size()];
for(int i : resList)
res[index++] = i;
return res;
}
}