该如何选择ClickHouse的表引擎
本文将介绍ClickHouse中一个非常重要的概念—表引擎(table engine)。如果对MySQL熟悉的话,或许你应该听说过InnoDB和MyISAM存储引擎。不同的存储引擎提供不同的存储机制、索引方式、锁定水平等功能,也可以称之为表类型。ClickHouse提供了丰富的表引擎,这些不同的表引擎也代表着不同的表类型。比如数据表拥有何种特性、数据以何种形式被存储以及如何被加载。本文会对ClickHouse中常见的表引擎进行介绍,主要包括以下内容:
-
表引擎的作用是什么
-
MergeTree系列引擎
-
Log家族系列引擎
-
外部集成表引擎
-
其他特殊的表引擎
温馨提示:本文内容较长,建议收藏
表引擎的作用是什么
-
决定表存储在哪里以及以何种方式存储
-
支持哪些查询以及如何支持
-
并发数据访问
-
索引的使用
-
是否可以执行多线程请求
-
数据复制参数
表引擎分类
| 引擎分类 | 引擎名称 |
|---|---|
| MergeTree系列 | MergeTree 、ReplacingMergeTree 、SummingMergeTree 、 AggregatingMergeTree CollapsingMergeTree 、 VersionedCollapsingMergeTree 、GraphiteMergeTree |
| Log系列 | TinyLog 、StripeLog 、Log |
| Integration Engines | Kafka 、MySQL、ODBC 、JDBC、HDFS |
| Special Engines | Distributed 、MaterializedView、 Dictionary 、Merge 、File、Null 、Set 、Join 、 URL View、Memory 、 Buffer |
Log系列表引擎
应用场景
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。即一次写入多次查询。
Log系列表引擎的特点
共性特点
-
数据存储在磁盘上
-
当写数据时,将数据追加到文件的末尾
-
不支持并发读写,当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束
-
不支持索引
-
不支持原子写:如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表
-
不支持ALTER操作(这些操作会修改表设置或数据,比如delete、update等等)
区别
-
TinyLog
TinyLog是Log系列引擎中功能简单、性能较低的引擎。它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件。除此之外,TinyLog不支持并发数据读取。
-
StripLog支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。另外,StripLog将所有列数据存储在同一个文件中,减少了文件的使用数量。
-
Log支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。Log引擎会将每个列数据单独存储在一个独立文件中。
TinyLog表引擎使用
该引擎适用于一次写入,多次读取的场景。对于处理小批数据的中间表可以使用该引擎。值得注意的是,使用大量的小表存储数据,性能会很低。
CREATE TABLE emp_tinylog (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=TinyLog();
INSERT INTO emp_tinylog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_tinylog
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
进入默认数据存储目录,查看底层数据存储形式,可以看出:TinyLog引擎表每一列都对应的文件
[root@cdh04 emp_tinylog]# pwd
/var/lib/clickhouse/data/default/emp_tinylog
[root@cdh04 emp_tinylog]# ll
总用量 28
-rw-r----- 1 clickhouse clickhouse 56 9月 17 14:33 age.bin
-rw-r----- 1 clickhouse clickhouse 97 9月 17 14:33 depart.bin
-rw-r----- 1 clickhouse clickhouse 60 9月 17 14:33 emp_id.bin
-rw-r----- 1 clickhouse clickhouse 70 9月 17 14:33 name.bin
-rw-r----- 1 clickhouse clickhouse 68 9月 17 14:33 salary.bin
-rw-r----- 1 clickhouse clickhouse 185 9月 17 14:33 sizes.json
-rw-r----- 1 clickhouse clickhouse 80 9月 17 14:33 work_place.bin
## 查看sizes.json数据
## 在sizes.json文件内使用JSON格式记录了每个.bin文件内对应的数据大小的信息
{
"yandex":{
"age%2Ebin":{
"size":"56"
},
"depart%2Ebin":{
"size":"97"
},
"emp_id%2Ebin":{
"size":"60"
},
"name%2Ebin":{
"size":"70"
},
"salary%2Ebin":{
"size":"68"
},
"work_place%2Ebin":{
"size":"80"
}
}
}
当我们执行ALTER操作时会报错,说明该表引擎不支持ALTER操作
-- 以下操作会报错:
-- DB::Exception: Mutations are not supported by storage TinyLog.
ALTER TABLE emp_tinylog DELETE WHERE emp_id = 5;
ALTER TABLE emp_tinylog UPDATE age = 30 WHERE emp_id = 4;
StripLog表引擎使用
相比TinyLog而言,StripeLog拥有更高的查询性能(拥有.mrk标记文件,支持并行查询),同时其使用了更少的文件描述符(所有数据使用同一个文件保存)。
CREATE TABLE emp_stripelog (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=StripeLog;
-- 插入数据
INSERT INTO emp_stripelog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_stripelog
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据
-- 由于是分两次插入数据,所以查询时会有两个数据块
cdh04 :) select * from emp_stripelog;
SELECT *
FROM emp_stripelog
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
进入默认数据存储目录,查看底层数据存储形式
[root@cdh04 emp_stripelog]# pwd
/var/lib/clickhouse/data/default/emp_stripelog
[root@cdh04 emp_stripelog]# ll
总用量 12
-rw-r----- 1 clickhouse clickhouse 673 9月 17 15:11 data.bin
-rw-r----- 1 clickhouse clickhouse 281 9月 17 15:11 index.mrk
-rw-r----- 1 clickhouse clickhouse 69 9月 17 15:11 sizes.json
可以看出StripeLog表引擎对应的存储结构包括三个文件:
-
data.bin:数据文件,所有的列字段使用同一个文件保存,它们的数据都会被写入data.bin。
-
index.mrk:数据标记,保存了数据在data.bin文件中的位置信息(每个插入数据块对应列的offset),利用数据标记能够使用多个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
-
sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息
提示:
StripeLog引擎将所有数据都存储在了一个文件中,对于每次的INSERT操作,ClickHouse会将数据块追加到表文件的末尾StripeLog引擎同样不支持
ALTER UPDATE和ALTER DELETE操作
Log表引擎使用
Log引擎表适用于临时数据,一次性写入、测试场景。Log引擎结合了TinyLog表引擎和StripeLog表引擎的长处,是Log系列引擎中性能最高的表引擎。
CREATE TABLE emp_log (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=Log;
INSERT INTO emp_log VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_log VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据,
-- 由于是分两次插入数据,所以查询时会有两个数据块
cdh04 :) select * from emp_log;
SELECT *
FROM emp_log
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
进入默认数据存储目录,查看底层数据存储形式
[root@cdh04 emp_log]# pwd
/var/lib/clickhouse/data/default/emp_log
[root@cdh04 emp_log]# ll
总用量 32
-rw-r----- 1 clickhouse clickhouse 56 9月 17 15:55 age.bin
-rw-r----- 1 clickhouse clickhouse 97 9月 17 15:55 depart.bin
-rw-r----- 1 clickhouse clickhouse 60 9月 17 15:55 emp_id.bin
-rw-r----- 1 clickhouse clickhouse 192 9月 17 15:55 __marks.mrk
-rw-r----- 1 clickhouse clickhouse 70 9月 17 15:55 name.bin
-rw-r----- 1 clickhouse clickhouse 68 9月 17 15:55 salary.bin
-rw-r----- 1 clickhouse clickhouse 216 9月 17 15:55 sizes.json
-rw-r----- 1 clickhouse clickhouse 80 9月 17 15:55 work_place.bin
Log引擎的存储结构包含三部分:
-
列.bin:数据文件,数据文件按列单独存储
-
__marks.mrk:数据标记,统一保存了数据在各个.bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取。.bin内的压缩数据块,从而提升数据查询的性能。
-
sizes.json:记录了.bin和__marks.mrk大小的信息
提示:
Log表引擎会将每一列都存在一个文件中,对于每一次的INSERT操作,都会对应一个数据块
MergeTree系列引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
MergeTree表引擎
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
-
存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度
-
支持分区,可以通过PRIMARY KEY语句指定分区字段。
-
支持数据副本
-
支持数据采样
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
-
ENGINE:ENGINE = MergeTree(),MergeTree引擎没有参数
-
ORDER BY:排序字段。比如ORDER BY (Col1, Col2),值得注意的是,如果没有指定主键,默认情况下 sorting key(排序字段)即为主键。如果不需要排序,则可以使用**ORDER BY tuple()**语法,这样的话,创建的表也就不包含主键。这种情况下,ClickHouse会按照插入的顺序存储数据。必选。
-
PARTITION BY:分区字段,可选。
-
PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。可选。
-
SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如
SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可选。 -
TTL:数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。可选。
-
SETTINGS:额外的参数配置。可选。
建表示例
CREATE TABLE emp_mergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=MergeTree()
ORDER BY emp_id
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_mergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_mergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据
-- 按work_place进行分区
cdh04 :) select * from emp_mergetree;
SELECT *
FROM emp_mergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
查看一下数据存储格式,可以看出,存在三个分区文件夹,每一个分区文件夹内存储了对应分区的数据。
[root@cdh04 emp_mergetree]# pwd
/var/lib/clickhouse/data/default/emp_mergetree
[root@cdh04 emp_mergetree]# ll
总用量 16
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:44 40d45822dbd7fa81583d715338929da9_1_1_0
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 a6155dcc1997eda1a348cd98b17a93e9_2_2_0
drwxr-x--- 2 clickhouse clickhouse 6 9月 17 17:43 detached
-rw-r----- 1 clickhouse clickhouse 1 9月 17 17:43 format_version.txt
进入一个分区目录查看
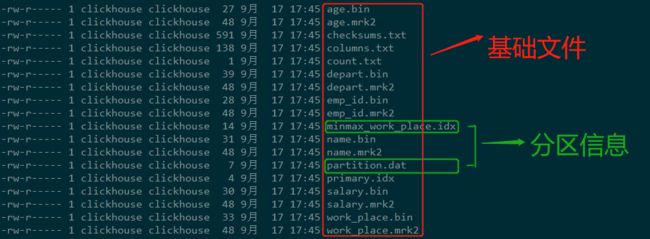
-
checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
-
columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息,例如
[root@cdh04 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0]# cat columns.txt columns format version: 1 6 columns: `emp_id` UInt16 `name` String `work_place` String `age` UInt8 `depart` String `salary` Decimal(9, 2) -
count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数
-
primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引,即通过ORDER BY或者PRIMARY KEY指定字段。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
-
列.bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的
.bin数据文件,并以列字段名称命名。 -
列.mrk2:列字段标记文件,使用二进制格式存储。标记文件中保存了
.bin文件中数据的偏移量信息 -
partition.dat与minmax_[Column].idx:如果指定了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值,即分区字段值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。比如当使用EventTime字段对应的原始数据为2020-09-17、2020-09-30,分区表达式为PARTITION BY toYYYYMM(EventTime),即按月分区。partition.dat中保存的值将会是2019-09,而minmax索引中保存的值将会是2020-09-17 2020-09-30。
注意点
-
多次插入数据,会生成多个分区文件
-- 新插入两条数据
cdh04 :) INSERT INTO emp_mergetree
VALUES (5,'robin','北京',35,'财务部',50000),(6,'lilei','北京',38,'销售事部',50000);
-- 查询结果
cdh04 :) select * from emp_mergetree;
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │
│ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │
└────────┴───────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
可以看出,新插入的数据新生成了一个数据块,并没有与原来的分区数据在一起,我们可以执行optimize命令,执行合并操作
-- 执行合并操作
cdh04 :) OPTIMIZE TABLE emp_mergetree PARTITION '北京';
-- 再次执行查询
cdh04 :) select * from emp_mergetree;
SELECT *
FROM emp_mergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │
│ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │
└────────┴───────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
执行上面的合并操作之后,会新生成一个该分区的文件夹,原理的分区文件夹不变。
-
在MergeTree中主键并不用于去重,而是用于索引,加快查询速度
-- 插入一条相同主键的数据
INSERT INTO emp_mergetree
VALUES (1,'sam','杭州',35,'财务部',50000);
-- 会发现该条数据可以插入,由此可知,并不会对主键进行去重
ReplacingMergeTree表引擎
上文提到MergeTree表引擎无法对相同主键的数据进行去重,ClickHouse提供了ReplacingMergeTree引擎,可以针对相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,ReplacingMergeTree只是在一定程度上解决了数据重复问题,但是并不能完全保障数据不重复。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
-
[ver]:可选参数,列的版本,可以是UInt、Date或者DateTime类型的字段作为版本号。该参数决定了数据去重的方式。
-
当没有指定[ver]参数时,保留最新的数据;如果指定了具体的值,保留最大的版本数据。
建表示例
CREATE TABLE emp_replacingmergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=ReplacingMergeTree()
ORDER BY emp_id
PRIMARY KEY emp_id
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_replacingmergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_replacingmergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
注意点
当我们再次向该表插入具有相同主键的数据时,观察查询数据的变化
INSERT INTO emp_replacingmergetree
VALUES (1,'tom','上海',25,'技术部',50000);
-- 查询数据,由于没有进行合并,所以存在主键重复的数据
cdh04 :) select * from emp_replacingmergetree;
SELECT *
FROM emp_replacingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
-- 执行合并操作
optimize table emp_replacingmergetree final;
-- 再次查询,相同主键的数据,保留最近插入的数据,旧的数据被清除
cdh04 :) select * from emp_replacingmergetree;
SELECT *
FROM emp_replacingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
从上面的示例中可以看出,ReplacingMergeTree是支持对数据去重的,那么是根据什么进行去重呢?答案是:ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。我们在看一个示例:
CREATE TABLE emp_replacingmergetree1 (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=ReplacingMergeTree()
ORDER BY (emp_id,name) -- 注意排序key是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_replacingmergetree1
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
再次向该表中插入相同emp_id和name的数据,并执行合并操作,再观察数据
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','上海',25,'技术部',50000),(1,'sam','上海',25,'技术部',20000);
-- 执行合并操作
optimize table emp_replacingmergetree1 final;
-- 再次查询,可见相同的emp_id和name数据被去重,而形同的主键emp_id不会去重
-- ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY
cdh04 :) select * from emp_replacingmergetree1;
SELECT *
FROM emp_replacingmergetree1
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
至此,我们知道了ReplacingMergeTree是支持去重的,并且是按照ORDERBY排序键为基准进行去重的。细心的你会发现,上面的重复数据是在一个分区内的,那么如果重复的数据不在一个分区内,会发生什么现象呢?我们再次向上面的emp_replacingmergetree1表插入不同分区的重复数据
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','北京',26,'技术部',10000);
-- 执行合并操作
optimize table emp_replacingmergetree1 final;
-- 再次查询
-- 发现 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00
-- 与 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00
-- 数据重复,因为这两行数据不在同一个分区内
-- 这是因为ReplacingMergeTree是以分区为单位删除重复数据的。
-- 只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除
cdh04 :) select * from emp_replacingmergetree1;
SELECT *
FROM emp_replacingmergetree1
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00 │
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
总结
-
如何判断数据重复
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。
-
何时删除重复数据
在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。
-
不同分区的重复数据不会被去重
ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
-
数据去重的策略是什么
如果没有设置**[ver]版本号**,则保留同一组重复数据中的最新插入的数据;如果设置了**[ver]版本号**,则保留同一组重复数据中ver字段取值最大的那一行。
-
optimize命令使用
一般在数据量比较大的情况,尽量不要使用该命令。因为在海量数据场景下,执行optimize要消耗大量时间
SummingMergeTree表引擎
该引擎继承了MergeTree引擎,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值,即如果存在重复的数据,会对对这些重复的数据进行合并成一条数据,类似于group by的效果。
推荐将该引擎和 MergeTree 一起使用。例如,将完整的数据存储在 MergeTree 表中,并且使用 SummingMergeTree 来存储聚合数据。这种方法可以避免因为使用不正确的主键组合方式而丢失数据。
如果用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的,即GROUP BY的分组字段是确定的,可以使用该表引擎。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns]) -- 指定合并汇总字段
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
建表示例
CREATE TABLE emp_summingmergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=SummingMergeTree(salary)
ORDER BY (emp_id,name) -- 注意排序key是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_summingmergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_summingmergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
当我们再次插入具有相同emp_id,name的数据时,观察结果
INSERT INTO emp_summingmergetree
VALUES (1,'tom','上海',25,'信息部',10000),(1,'tom','北京',26,'人事部',10000);
cdh04 :) select * from emp_summingmergetree;
-- 查询
SELECT *
FROM emp_summingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
-- 执行合并操作
optimize table emp_summingmergetree final;
cdh04 :) select * from emp_summingmergetree;
-- 再次查询,新插入的数据 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00
-- 原来的数据 : 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00
-- 这两行数据合并成: 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00
SELECT *
FROM emp_summingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
注意点
要保证PRIMARY KEY expr指定的主键是ORDER BY expr 指定字段的前缀,比如
-- 允许
ORDER BY (A,B,C)
PRIMARY KEY A
-- 会报错
-- DB::Exception: Primary key must be a prefix of the sorting key
ORDER BY (A,B,C)
PRIMARY KEY B
这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。
总结
-
SummingMergeTree是根据什么对两条数据进行合并的
用ORBER BY排序键作为聚合数据的条件Key。即如果排序key是相同的,则会合并成一条数据,并对指定的合并字段进行聚合。
-
仅对分区内的相同排序key的数据行进行合并
以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
-
如果没有指定聚合字段,会怎么聚合
如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合
-
对于非汇总字段的数据,该保留哪一条
如果两行数据除了排序字段相同,其他的非聚合字段不相同,那么在聚合发生时,会保留最初的那条数据,新插入的数据对应的那个字段值会被舍弃
-- 新插入的数据: 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00
-- 最初的数据 : 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00
-- 聚合合并的结果: 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00
Aggregatingmergetree表引擎
该表引擎继承自MergeTree,可以使用 AggregatingMergeTree 表来做增量数据统计聚合。如果要按一组规则来合并减少行数,则使用 AggregatingMergeTree 是合适的。AggregatingMergeTree是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。
与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
建表示例
CREATE TABLE emp_aggregatingmergeTree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary AggregateFunction(sum,Decimal32(2)) COMMENT '工资'
)ENGINE=AggregatingMergeTree()
ORDER BY (emp_id,name) -- 注意排序key是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
PARTITION BY work_place
;
对于AggregateFunction类型的列字段,在进行数据的写入和查询时与其他的表引擎有很大区别,在写入数据时,需要调用**-State函数;而在查询数据时,则需要调用相应的-Merge函数。对于上面的建表语句而言,需要使用sumState**函数进行数据插入
-- 插入数据,
-- 注意:需要使用INSERT…SELECT语句进行数据插入
INSERT INTO TABLE emp_aggregatingmergeTree
SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(10000,2));
INSERT INTO TABLE emp_aggregatingmergeTree
SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(20000,2));
-- 查询数据
SELECT
emp_id,
name ,
sumMerge(salary)
FROM emp_aggregatingmergeTree
GROUP BY emp_id,name;
-- 结果输出
┌─emp_id─┬─name─┬─sumMerge(salary)─┐
│ 1 │ tom │ 30000.00 │
└────────┴──────┴──────────────────┘
上面演示的用法非常的麻烦,其实更多的情况下,我们可以结合物化视图一起使用,将它作为物化视图的表引擎。而这里的物化视图是作为其他数据表上层的一种查询视图。
AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用。
-- 创建一个MereTree引擎的明细表
-- 用于存储全量的明细数据
-- 对外提供实时查询
CREATE TABLE emp_mergetree_base (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=MergeTree()
ORDER BY (emp_id,name)
PARTITION BY work_place
;
-- 创建一张物化视图
-- 使用AggregatingMergeTree表引擎
CREATE MATERIALIZED VIEW view_emp_agg
ENGINE = AggregatingMergeTree()
PARTITION BY emp_id
ORDER BY (emp_id,name)
AS SELECT
emp_id,
name,
sumState(salary) AS salary
FROM emp_mergetree_base
GROUP BY emp_id,name;
-- 向基础明细表emp_mergetree_base插入数据
INSERT INTO emp_mergetree_base
VALUES (1,'tom','上海',25,'技术部',20000),
(1,'tom','上海',26,'人事部',10000);
-- 查询物化视图
SELECT
emp_id,
name ,
sumMerge(salary)
FROM view_emp_agg
GROUP BY emp_id,name;
-- 结果
┌─emp_id─┬─name─┬─sumMerge(salary)─┐
│ 1 │ tom │ 30000.00 │
└────────┴──────┴──────────────────┘
CollapsingMergeTree表引擎
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
每次需要新增数据时,写入一行sign标记为1的数据;需要删除数据时,则写入一行sign标记为-1的数据。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
建表示例
上面的建表语句使用CollapsingMergeTree(sign),其中字段sign是一个Int8类型的字段
CREATE TABLE emp_collapsingmergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资',
sign Int8
)ENGINE=CollapsingMergeTree(sign)
ORDER BY (emp_id,name)
PARTITION BY work_place
;
使用方式
CollapsingMergeTree同样是以ORDER BY排序键作为判断数据唯一性的依据。
-- 插入新增数据,sign=1表示正常数据
INSERT INTO emp_collapsingmergetree
VALUES (1,'tom','上海',25,'技术部',20000,1);
-- 更新上述的数据
-- 首先插入一条与原来相同的数据(ORDER BY字段一致),并将sign置为-1
INSERT INTO emp_collapsingmergetree
VALUES (1,'tom','上海',25,'技术部',20000,-1);
-- 再插入更新之后的数据
INSERT INTO emp_collapsingmergetree
VALUES (1,'tom','上海',25,'技术部',30000,1);
-- 查看一下结果
cdh04 :) select * from emp_collapsingmergetree ;
SELECT *
FROM emp_collapsingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
-- 执行分区合并操作
optimize table emp_collapsingmergetree;
-- 再次查询,sign=1与sign=-1的数据相互抵消了,即被删除
cdh04 :) select * from emp_collapsingmergetree ;
SELECT *
FROM emp_collapsingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
注意点
-
分区合并
分数数据折叠不是实时的,需要后台进行Compaction操作,用户也可以使用手动合并命令,但是效率会很低,一般不推荐在生产环境中使用。
当进行汇总数据操作时,可以通过改变查询方式,来过滤掉被删除的数据
SELECT
emp_id,
name,
sum(salary * sign)
FROM emp_collapsingmergetree
GROUP BY
emp_id,
name
HAVING sum(sign) > 0
只有相同分区内的数据才有可能被折叠。其实,当我们修改或删除数据时,这些被修改的数据通常是在一个分区内的,所以不会产生影响。
-
数据写入顺序
值得注意的是:CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。
-- 建表
CREATE TABLE emp_collapsingmergetree_order (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资',
sign Int8
)ENGINE=CollapsingMergeTree(sign)
ORDER BY (emp_id,name)
PARTITION BY work_place
;
-- 先插入需要被删除的数据,即sign=-1的数据
INSERT INTO emp_collapsingmergetree_order
VALUES (1,'tom','上海',25,'技术部',20000,-1);
-- 再插入sign=1的数据
INSERT INTO emp_collapsingmergetree_order
VALUES (1,'tom','上海',25,'技术部',20000,1);
-- 查询表
SELECT *
FROM emp_collapsingmergetree_order
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
-- 执行合并操作
optimize table emp_collapsingmergetree_order;
-- 再次查询表
-- 旧数据依然存在
SELECT *
FROM emp_collapsingmergetree_order;
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree的工作机制就会出现问题。但是可以通过VersionedCollapsingMergeTree的表引擎得到解决。
VersionedCollapsingMergeTree表引擎
上面提到CollapsingMergeTree表引擎对于数据写入乱序的情况下,不能够实现数据折叠的效果。VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
VersionedCollapsingMergeTree使用version列来实现乱序情况下的数据折叠。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = VersionedCollapsingMergeTree(sign, version)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
可以看出:该引擎除了需要指定一个sign标识之外,还需要指定一个UInt8类型的version版本号。
建表示例
CREATE TABLE emp_versioned (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资',
sign Int8,
version Int8
)ENGINE=VersionedCollapsingMergeTree(sign, version)
ORDER BY (emp_id,name)
PARTITION BY work_place
;
-- 先插入需要被删除的数据,即sign=-1的数据
INSERT INTO emp_versioned
VALUES (1,'tom','上海',25,'技术部',20000,-1,1);
-- 再插入sign=1的数据
INSERT INTO emp_versioned
VALUES (1,'tom','上海',25,'技术部',20000,1,1);
-- 在插入一个新版本数据
INSERT INTO emp_versioned
VALUES (1,'tom','上海',25,'技术部',30000,1,2);
-- 先不执行合并,查看表数据
cdh04 :) select * from emp_versioned;
SELECT *
FROM emp_versioned
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ 2 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │ 1 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘
-- 获取正确查询结果
SELECT
emp_id,
name,
sum(salary * sign)
FROM emp_versioned
GROUP BY
emp_id,
name
HAVING sum(sign) > 0;
-- 手动合并
optimize table emp_versioned;
-- 再次查询
cdh04 :) select * from emp_versioned;
SELECT *
FROM emp_versioned
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ 2 │
└────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘
可见上面虽然在插入数据乱序的情况下,依然能够实现折叠的效果。之所以能够达到这种效果,是因为在定义version字段之后,VersionedCollapsingMergeTree会自动将version作为排序条件并增加到ORDER BY的末端,就上述的例子而言,最终的排序字段为ORDER BY emp_id,name,version desc。
GraphiteMergeTree表引擎
该引擎用来对 Graphite数据进行'瘦身'及汇总。对于想使用CH来存储Graphite数据的开发者来说可能有用。
如果不需要对Graphite数据做汇总,那么可以使用任意的CH表引擎;但若需要,那就采用 GraphiteMergeTree 引擎。它能减少存储空间,同时能提高Graphite数据的查询效率。
外部集成表引擎
ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
例如直接读取HDFS的文件或者MySQL数据库的表。这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。目前ClickHouse提供了下面的外部集成表引擎:
-
ODBC:通过指定odbc连接读取数据源
-
JDBC:通过指定jdbc连接读取数据源;
-
MySQL:将MySQL作为数据存储,直接查询其数据
-
HDFS:直接读取HDFS上的特定格式的数据文件;
-
Kafka:将Kafka数据导入ClickHouse
-
RabbitMQ:与Kafka类似
HDFS
使用方式
ENGINE = HDFS(URI, format)
-
URI:HDFS文件路径
-
format:文件格式,比如CSV、JSON、TSV等
使用示例
-- 建表
CREATE TABLE hdfs_engine_table(
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
) ENGINE=HDFS('hdfs://cdh03:8020/user/hive/hdfs_engine_table', 'CSV');
-- 写入数据
INSERT INTO hdfs_engine_table
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
-- 查询数据
cdh04 :) select * from hdfs_engine_table;
SELECT *
FROM hdfs_engine_table
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
--再在HDFS上其对应的文件,添加几条数据,再次查看
cdh04 :) select * from hdfs_engine_table;
SELECT *
FROM hdfs_engine_table
┌─emp_id─┬─name───┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
│ 3 │ lili │ 北京 │ 28 │ 技术部 │ 20000.00 │
│ 4 │ jasper │ 杭州 │ 27 │ 人事部 │ 8000.00 │
└────────┴────────┴────────────┴─────┴────────┴──────────┘
可以看出,这种方式与使用Hive类似,我们直接可以将HDFS对应的文件映射成ClickHouse中的一张表,这样就可以使用SQL操作HDFS上的文件了。
值得注意的是:ClickHouse并不能够删除HDFS上的数据,当我们在ClickHouse客户端中删除了对应的表,只是删除了表结构,HDFS上的文件并没有被删除,这一点跟Hive的外部表十分相似。
MySQL
在上一篇文章[篇一|ClickHouse快速入门]中介绍了MySQL数据库引擎,即ClickHouse可以创建一个MySQL数据引擎,这样就可以在ClickHouse中操作其对应的数据库中的数据。其实,ClickHouse同样支持MySQL表引擎,即映射一张MySQL中的表到ClickHouse中。
使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
使用示例
-- 连接MySQL中clickhouse数据库的test表
CREATE TABLE mysql_engine_table(
id Int32,
name String
) ENGINE = MySQL(
'192.168.200.241:3306',
'clickhouse',
'test',
'root',
'123qwe');
-- 查询数据
cdh04 :) SELECT * FROM mysql_engine_table;
SELECT *
FROM mysql_engine_table
┌─id─┬─name──┐
│ 1 │ tom │
│ 2 │ jack │
│ 3 │ lihua │
└────┴───────┘
-- 插入数据,会将数据插入MySQL对应的表中
-- 所以当查询MySQL数据时,会发现新增了一条数据
INSERT INTO mysql_engine_table VALUES(4,'robin');
-- 再次查询
cdh04 :) select * from mysql_engine_table;
SELECT *
FROM mysql_engine_table
┌─id─┬─name──┐
│ 1 │ tom │
│ 2 │ jack │
│ 3 │ lihua │
│ 4 │ robin │
└────┴───────┘
注意:对于MySQL表引擎,不支持UPDATE和DELETE操作,比如执行下面命令时,会报错:
-- 执行更新
ALTER TABLE mysql_engine_table UPDATE name = 'hanmeimei' WHERE id = 1;
-- 执行删除
ALTER TABLE mysql_engine_table DELETE WHERE id = 1;
-- 报错
DB::Exception: Mutations are not supported by storage MySQL.
JDBC
使用方式
JDBC表引擎不仅可以对接MySQL数据库,还能够与PostgreSQL等数据库。为了实现JDBC连接,ClickHouse使用了clickhouse-jdbc-bridge的查询代理服务。
首先我们需要下载clickhouse-jdbc-bridge,然后按照ClickHouse的github中的步骤进行编译,编译完成之后会有一个clickhouse-jdbc-bridge-1.0.jar的jar文件,除了需要该文件之外,还需要JDBC的驱动文件,本文使用的是MySQL,所以还需要下载MySQL驱动包。将MySQL的驱动包和clickhouse-jdbc-bridge-1.0.jar文件放在了/opt/softwares路径下,执行如下命令:
[root@cdh04 softwares]# java -jar clickhouse-jdbc-bridge-1.0.jar --driver-path . --listen-host cdh04
其中--driver-path是MySQL驱动的jar所在的路径,listen-host是代理服务绑定的主机。默认情况下,绑定的端口是:9019。上述jar包的下载:
链接:https://pan.baidu.com/s/1ZcvF22GvnvAQpVTleNry7Q 提取码:la9n
然后我们再配置/etc/clickhouse-server/config.xml,在文件中添加如下配置,然后重启服务。
cdh04
9019
使用示例
-
直接查询MySQL中对应的表
SELECT *
FROM
jdbc(
'jdbc:mysql://192.168.200.241:3306/?user=root&password=123qwe',
'clickhouse',
'test');
-
创建一张映射表
-- 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name
(
columns list...
)
ENGINE = JDBC(dbms_uri, external_database, external_table)
-- MySQL建表
CREATE TABLE jdbc_table_mysql (
order_id INT NOT NULL AUTO_INCREMENT,
amount FLOAT NOT NULL,
PRIMARY KEY (order_id));
INSERT INTO jdbc_table_mysql VALUES (1,200);
-- 在ClickHouse中建表
CREATE TABLE jdbc_table
(
order_id Int32,
amount Float32
)
ENGINE JDBC(
'jdbc:mysql://192.168.200.241:3306/?user=root&password=123qwe',
'clickhouse',
'jdbc_table_mysql');
-- 查询数据
cdh04 :) select * from jdbc_table;
SELECT *
FROM jdbc_table
┌─order_id─┬─amount─┐
│ 1 │ 200 │
└──────────┴────────┘
Kafka
使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol',]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_max_block_size = 0,]
[kafka_skip_broken_messages = N,]
[kafka_commit_every_batch = 0,]
[kafka_thread_per_consumer = 0]
-
kafka_broker_list:逗号分隔的brokers地址 (localhost:9092). -
kafka_topic_list:Kafka 主题列表,多个主题用逗号分隔. -
kafka_group_name:消费者组. -
kafka_format– Message format. 比如JSONEachRow、JSON、CSV等等
使用示例
在kafka中创建ck_topic主题,并向该主题写入数据
CREATE TABLE kafka_table (
id UInt64,
name String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'cdh04:9092',
kafka_topic_list = 'ck_topic',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow'
;
-- 查询
cdh04 :) select * from kafka_table ;
SELECT *
FROM kafka_table
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
注意点
当我们一旦查询完毕之后,ClickHouse会删除表内的数据,其实Kafka表引擎只是一个数据管道,我们可以通过物化视图的方式访问Kafka中的数据。
-
首先创建一张Kafka表引擎的表,用于从Kafka中读取数据
-
然后再创建一张普通表引擎的表,比如MergeTree,面向终端用户使用
-
最后创建物化视图,用于将Kafka引擎表实时同步到终端用户所使用的表中
-- 创建Kafka引擎表
CREATE TABLE kafka_table_consumer (
id UInt64,
name String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'cdh04:9092',
kafka_topic_list = 'ck_topic',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow'
;
-- 创建一张终端用户使用的表
CREATE TABLE kafka_table_mergetree (
id UInt64 ,
name String
)ENGINE=MergeTree()
ORDER BY id
;
-- 创建物化视图,同步数据
CREATE MATERIALIZED VIEW consumer TO kafka_table_mergetree
AS SELECT id,name FROM kafka_table_consumer ;
-- 查询,多次查询,已经被查询的数据依然会被输出
cdh04 :) select * from kafka_table_mergetree;
SELECT *
FROM kafka_table_mergetree
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
其他特殊的表引擎
Memory表引擎
Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换。当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。一般在测试时使用。
CREATE TABLE table_memory (
id UInt64,
name String
) ENGINE = Memory();
Distributed表引擎
使用方式
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,数据都分散存储在某一个分片上,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
所以,一张分布式表底层会对应多个本地分片数据表,由具体的分片表存储数据,分布式表与分片表是一对多的关系
Distributed表引擎的定义形式如下所示
Distributed(cluster_name, database_name, table_name[, sharding_key])
各个参数的含义分别如下:
-
cluster_name:集群名称,与集群配置中的自定义名称相对应。
-
database_name:数据库名称
-
table_name:表名称
-
sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。
尖叫提示:
创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
同样值得注意的是,在上面的语句中使用了ON CLUSTER分布式DDL,这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一端发起对所有分片的读、写请求。
使用示例
-- 创建一张分布式表
CREATE TABLE IF NOT EXISTS user_cluster ON CLUSTER cluster_3shards_1replicas
(
id Int32,
name String
)ENGINE = Distributed(cluster_3shards_1replicas, default, user_local,id);
创建完成上面的分布式表时,在每台机器上查看表,发现每台机器上都存在一张刚刚创建好的表。
接下来就需要创建本地表了,在每台机器上分别创建一张本地表:
CREATE TABLE IF NOT EXISTS user_local
(
id Int32,
name String
)ENGINE = MergeTree()
ORDER BY id
PARTITION BY id
PRIMARY KEY id;
我们先在一台机器上,对user_local表进行插入数据,然后再查询user_cluster表
-- 插入数据
cdh04 :) INSERT INTO user_local VALUES(1,'tom'),(2,'jack');
-- 查询user_cluster表,可见通过user_cluster表可以操作所有的user_local表
cdh04 :) select * from user_cluster;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
接下来,我们再向user_cluster中插入一些数据,观察user_local表数据变化,可以发现数据被分散存储到了其他节点上了。
-- 向user_cluster插入数据
cdh04 :) INSERT INTO user_cluster VALUES(3,'lilei'),(4,'lihua');
-- 查看user_cluster数据
cdh04 :) select * from user_cluster;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name──┐
│ 3 │ lilei │
└────┴───────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
┌─id─┬─name──┐
│ 4 │ lihua │
└────┴───────┘
-- 在cdh04上查看user_local
cdh04 :) select * from user_local;
┌─id─┬─name─┐
│ 2 │ jack │
└────┴──────┘
┌─id─┬─name──┐
│ 3 │ lilei │
└────┴───────┘
┌─id─┬─name─┐
│ 1 │ tom │
└────┴──────┘
-- 在cdh05上查看user_local
cdh05 :) select * from user_local;
┌─id─┬─name──┐
│ 4 │ lihua │
└────┴───────┘
总结
ClickHouse提供了非常多的表引擎,每一种表引擎都有各自的适用场景。通过特定的表引擎支撑特定的场景,十分灵活。本文主要分享了ClickHouse提供的常见表引擎,并对每种表引擎给出了适用场景和使用示例,希望对你有所帮助。