机器学习入门:预测房价
import hashlib
import os
import tarfile
import zipfile
import requests-
hashlib:这个库提供了多种加密算法,例如MD5、SHA1等算法,用于对数据进行加密、摘要或哈希计算。
-
requests:这个库是一个强大而简洁的HTTP库,用于发送HTTP请求和处理响应。它提供了简单易用的接口,使得与Web服务进行通信变得方便。可以使用requests库发送HTTP请求并获取响应,检查状态码、处理响应数据等。
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('..', 'data')): #@save
"""下载一个DATA_HUB中的文件,返回本地文件名"""
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # 命中缓存
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fnamedownload(name, cache_dir=os.path.join('..', 'data'))
download函数,参数为name和 缓存目录
DATA_HUB字典中获取文件名对应的URL和SHA1哈希值。
url.split('/')[-1]:这个表达式表示获取分割后列表的最后一个元素,即url中的文件名部分。例如,如果url是'http://example.com/files/file.txt',那么url.split('/')[-1]将返回'file.txt'。
如果这个缓存文件存在,创建一个SHA-1哈希对象,打开本地缓存文件(fname),以二进制模式('rb')读取文件内容。
文件对象(f)中读取1048576字节(1MB)的数据,并将数据赋值给变量data。读取的数据会作为二进制字符串进行处理。
如果已经读取完文件中的所有数据,则跳出循环(break),意味着文件的哈希值计算完成。
sha1.update(data) 将数据连续地添加到哈希对象的计算中。
如果这个缓存文件存在,且哈希值也一样,则返回fname
否则从url网址上下载,写入fname中,最后返回fname
stream流的方式获取响应是指通过网络请求获取到的响应数据并不一次性地返回,而是以数据流的形式逐步传输。
verify=True 是一种参数配置,通常用于进行网络请求时进行SSL证书验证。当该参数设置为True时,它会启用SSL证书验证机制,确保请求的目标服务器具有有效且受信任的SSL证书。
def download_extract(name, folder=None): #@save
"""下载并解压zip/tar文件"""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): #@save
"""下载DATA_HUB中的所有文件"""
for name in DATA_HUB:
download(name)base_dir 返回文件所在目录的路径
os.path.splitext(fname)用于将给定的文件路径 fname 分割成文件名和扩展名两部分。它返回一个包含文件名和扩展名的元组,其中一部分是文件路径 fname 去掉扩展名的部分,另一部分是扩展名(包括点)。
得到data_dir 和.ext(扩展名)
fp是得到的压缩文件,提取并放入 base_dir 中,即和压缩文件在同一个目录中
folder应该是一个后缀路径,来打开某个特定文件夹的(大概吧),否则就返回解压缩后的那个根文件夹
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
正在从http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv下载../data/kaggle_house_pred_train.csv...
正在从http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv下载../data/kaggle_house_pred_test.csv...
url, sha1_hash = DATA_HUB[name],也反应在上面
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))把所有的id删掉,和结果无关
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
all_features = pd.get_dummies(all_features, dummy_na=True)
由不止一种数据类型组成,而Python中一切皆对象,因此都处理为最宽泛的"对象"也就是object了
取出所有列索引,对所有数据每一列分别进行标准化,把缺失值NAN填补上0。然后用one-hot来处理其他的object特征。
n_train = train_data.shape[0]
train_features = torch.tensor(
all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(
all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()得到有多少训练数据,对这些训练特征和测试特征转化为tensor进行数学处理
clamp把net得到的预测值限制为必须大于一,根据预测值和标签值计算rmse,最后返回

把绝对误差表示为相对误差。
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls定义优化器,然后根据优化器开始迭代,计算mse并保存在列表中
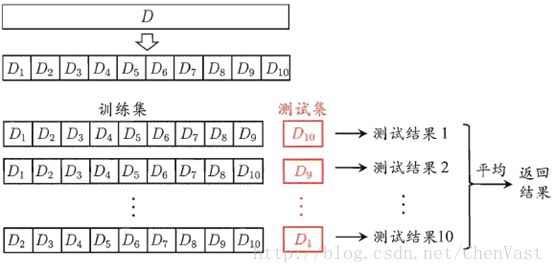
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / kX_part, y_part,得到某一折的数据和标签,j=i,那么就是验证折,否则为测试折,多个测试折拼接在一起,形成测试集。
然后k折交叉验证,最后if i等于0(D1作为验证折),画一个根据epoch变化的loss图。
但最后返回平均结果。
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')带入参数运行,得到训练模型
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)得到训练的loss,忽略test的loss。,然后画出图像
预测需要detach,不积累梯度,最后转化为numpy
preds.reshape(1, -1)[0]得到一个1行多列的一维数组。
在列轴进行拼接id 和 saleprice 得到一个两行,很多列的一个结果
转化为csv文件上传。不加索引。
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
带入参数数据得到结果