爬虫 requests——获取网络请求(九)
目录
一、requests安装
二、response的属性及类型
三、requests的get请求
四、requests的post请求——百度翻译
五、代理
七、打码平台
参考
一、requests安装
pip install requests
二、response的属性及类型
response的一个类型和六个属性
类型:models.Response
r.text:获取网站源码
r.encoding:访问或定制编码方式r.url:获取请求的url
r.content:响应的字节类型
r.status code:响应的状态码
r.headers:响应的头信息
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# 一个类型和六个属性
print(type(response)) #
# 设置相应的编码格式
response.encoding = 'utf-8'
# 以字符串的形式返回网页的源码
print(response.text)
# 返回url地址
print(response.url)
# 返回的是二进制的数据
print(response.content)
# 返回响应的状态码
print(response.status_code)
# 返回响应头
print(response.headers) 三、requests的get请求
import requests
url = 'https://ww.baidu.com/s?'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
data = {
'wd':'北京'
}
# url:请求资源路径
# params:参数
# kwargs:字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
# 总结
# 1.参数使用params传递
# 2.参数不需要urlencode编码
# 3.不需要请求对象的定制
# 4.请求资源中的 '?' 可以加,也可以不加四、requests的post请求——百度翻译
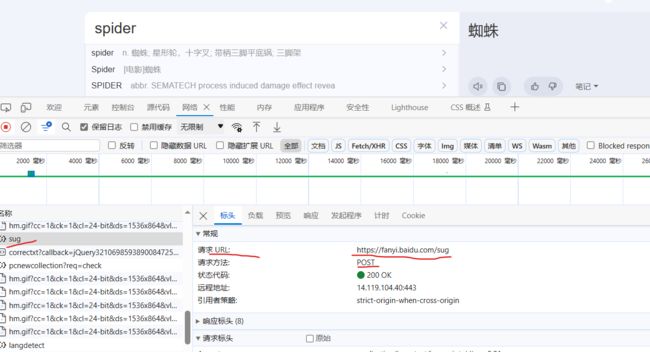
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
data = {
'kw':'spider'
}
# url:请求地址
# data:请求参数
# kwargs:字典
response = requests.post(url, data, headers)
content = response.text
# print(content)
import json
obj = json.loads(content,encoding='utf-8')
print(obj)
# 总结
# 1.post请求不要编解码
# 2.post请求的参数是data
# 3.不需要请求对象的定制五、代理
import requests
url = 'http://www.baidu.com/s?'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
data = {
'wd':'ip'
}
proxy = {
'http':'183.236.123.242:8060'
}
response = requests.get(url=url, params=data, headers=headers, proxies=proxy)
content = response.text
with open('peoxy.html', 'w', encoding='utf-8') as file:
file.write(content)六、cookie登录——古诗文网
# 总结
# 难点
# 1. 隐藏域问题
# 2. 验证码
抓登录界面的接口:登录界面,输入错的信息点击登录。找到以“login”开头的名称,可以看到登录界面的参数。
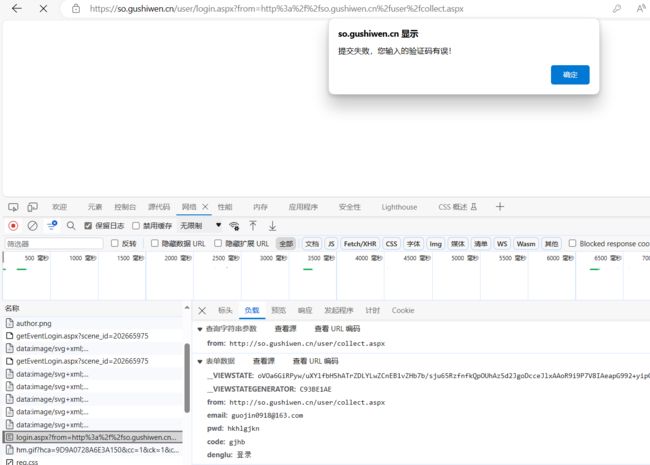
data_post={
'__VIEWSTATE': __viewstate,
'__VIEWSTATEGENERATOR': __viewsategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'your_emile',
'pwd': 'your_pwd',
'code': code_name,
'denglu': '登录'
}
在源代码中找到这两个变量,这两个变量被称为隐藏域
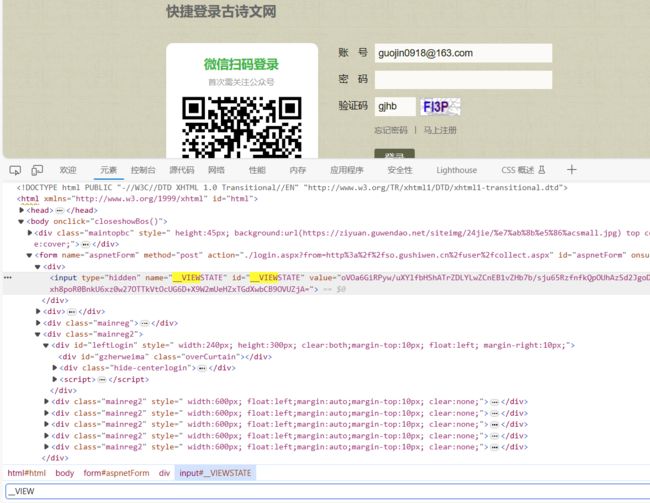
import requests
# 登录页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 获取网页源码
response = requests.get(url=url, headers=headers)
content = response.text
# 解析源码,获取值
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
__viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
__viewsategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# print(__viewstate)
# print(__viewsategenerator)抓取登录接口的,发送post请求
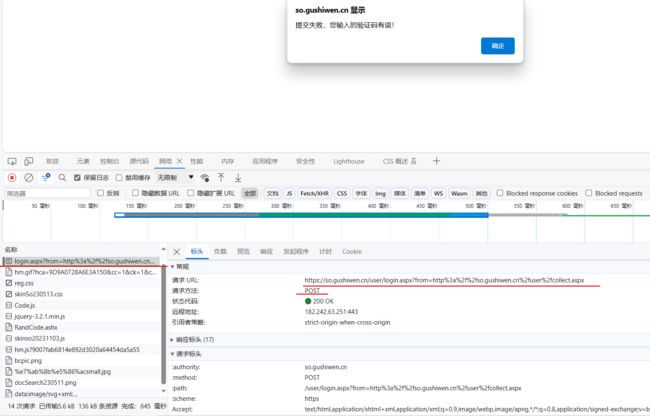
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post={
'__VIEWSTATE': __viewstate,
'__VIEWSTATEGENERATOR': __viewsategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'your_emile',
'pwd': 'your_pwd',
'code': code_name,
'denglu': '登录'
}
# response_post = requests.post(url=url, data=data_post, headers=headers)
# 使用session获取请求,就不能使用requests了
response_post = session.post(url=url, data=data_post, headers=headers)
content_post = response_post.text
with open('_088_gushi.html', 'w', encoding='utf-8') as file:
file.write(content_post)
完整代码:
import requests
# 通过登录进入到主页面
# 通过登录接口我们发现,登录的时候需要的参数很多
# __VIEWSTATE: oVOa6GiRPyw/uXYlfbHShATrZDLYLwZCnEB1vZHb7b/sju65RzfnfkQpOUhAzSd2JgoDcceJlxAAoR9i9P7V8IAeapG992+yipGxh8poR0BnkU6xz0w27OTTkVtOcUG6D+X9W2mUeHZxTGdXwbCB9OVUZjA=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: your_emile
# pwd: hkhlgjkn
# code: gchb
# denglu: 登录
# 我们观察到 __VIEWSTATE , __VIEWSTATEGENERATOR , code 是一个变化的量
# 难点:(1) __VIEWSTATE , __VIEWSTATEGENERATOR # 一般情况下,看不见的数据都是在页面的源码中
# 我们观察到这两个数据在页面的源码中,所以我们需要获取页面的源码,然后进行解析、赋值就可以了
# (2) 验证码
import requests
# 登录页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 获取网页源码
response = requests.get(url=url, headers=headers)
content = response.text
# 解析源码,获取值
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
__viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
__viewsategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# print(__viewstate)
# print(__viewsategenerator)
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# print(code_url)
# urlretrieve 下载图片有坑 这里下载了图片,下次post请求验证码被刷新
import urllib.request
# urllib.request.urlretrieve(url=code_url, filename='_088_code.jpg')
# requests有个方法 session(),通过session的返回值,就能使请求变成一个对象
session = requests.session()
# 验证码url的内容
response_code = session.get(code_url)
# 注意,此时要使用二进制数据,因为我们要使用的是图片的下载
content_code = response_code.content
# 写二进制数据
with open('_088_code.png', 'wb') as file:
file.write(content_code)
# 获取了验证码的图片之后,下载到本地,然后观察验证码,并将这个值赋给 ’code‘
code_name = input('input code')
# 点击登录
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post={
'__VIEWSTATE': __viewstate,
'__VIEWSTATEGENERATOR': __viewsategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'your_emile',
'pwd': 'your_pwd',
'code': code_name,
'denglu': '登录'
}
# response_post = requests.post(url=url, data=data_post, headers=headers)
# 使用session获取请求,就不能使用requests了
response_post = session.post(url=url, data=data_post, headers=headers)
content_post = response_post.text
with open('_088_gushi.html', 'w', encoding='utf-8') as file:
file.write(content_post)
# 总结
# 难点
# 1. 隐藏域问题
# 2. 验证码
七、打码平台
打码平台可以自动识别验证码,如:超级鹰打码平台
参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)