瑞_Java开发手册_(五)MySQL数据库
文章目录
-
- (一) 建表规约
- (二) 索引规约
- (三) SQL 语句
- (四) ORM 映射
- 附:雪花算法(Java)
前言:本文章为瑞_系列专栏之《Java开发手册》的MySQL数据库篇,主要介绍建表规约、索引规约、SQL语句、ORM映射。由于博主是从阿里的《Java开发手册》学习到Java的编程规约,所以本系列专栏主要以这本书进行讲解和拓展,有需要的小伙伴可以点击链接下载。本文仅供大家交流、学习及研究使用,禁止用于商业用途,违者必究!
本系列第一篇链接:(一)编程规约
本系列第二篇链接:(二)异常日志
本系列第三篇链接:(三)单元测试
本系列第四篇链接:(四)安全规约
本系列第五篇链接:(五)MySQL数据库
本系列第六篇链接:(六)工程结构
本系列第七篇链接:(七)设计规约

(一) 建表规约
- 【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是,0 表示否)。
说明:任何字段如果为非负数,必须是 unsigned。
注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在设置从 is_xxx 到Xxx 的映射关系。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的命名方式是为了明确其取值含义与取值范围。
正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
瑞:关于本条,需要结合本系列第一篇【编程规约】中的(一)命名风格的第8条:【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。
注意区分:本条中的正例是MySQL的数据表中的逻辑删除字段的命名规约,而【编程规约】中的(一)命名风格指的是Java后端实体类与数据表字段对应的属性的命名风格,同时遵循这两条并不冲突
- 【强制】表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
说明:MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、表名、字段名,都不允许出现任何大写字母,避免节外生枝。
正例:aliyun_admin,rdc_config,level3_name
反例:AliyunAdmin,rdcConfig,level_3_name
瑞:表名、字段名请使用小写❗️ 使用小写❗️ 使用小写❗️并且每个完整含义的单词之间使用下划线
_分割
- 【强制】表名不使用复数名词。
说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数形式,符合表达习惯。
瑞:可以参考本系列第一篇【编程规约】中的(一)命名风格的第9条:【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
- 【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
瑞:可以使用
SELECT * FROM information_schema.keywords查看MySQL保留字,示例如以下代码所示
-- 查询全部
SELECT * FROM information_schema.keywords
-- SELECT * FROM information_schema.keywords WHERE keyword_name IN ('保留字1', '保留字2', '保留字3', ...);
SELECT * FROM information_schema.keywords WHERE word IN ('INSERT');
- 【强制】主键索引名为 pk_字段名;唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。
说明:pk_ 即 primary key;uk_ 即 unique key;idx_ 即 index 的简称。
瑞:示例:主键索引名为 pk_user_id;唯一索引名为 uk_email;普通索引名则为 idx_username。
- 【强制】小数类型为 decimal,禁止使用 float 和 double。
说明:在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
瑞:推荐阅读《瑞_Java中浮点数精度误差产生原因_浮点数底层存储结构(详细附代码)》详细说明了存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。验证了
0.1f + 0.2f == 0.3f为true,而0.3f + 0.6f == 0.9f为false的原因
- 【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
瑞:如电话号码(长度不超过20个字符)等存储的字符串长度几乎相等,就不要使用varchar
- 【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
瑞:类似于存储博客内容这种存储字段,无法预判用户的存储长度,并且大多数情况下都特别大,就要遵守本条
- 【强制】表必备三字段:id, gmt_create, gmt_modified。
说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。gmt_create, gmt_modified的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
瑞:关于本条中的说明,博主认为还是跟着业务的需求进行设置,不一定死板的在建表的时候就把主键设置为单表步长为1的自增主键,也可以自己后端Java使用
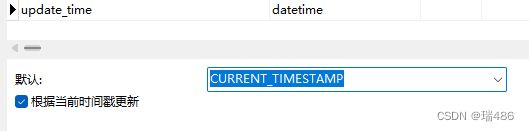
雪花算法(附在文末)生成的主键之类的方式(减少对MySQL的依赖),当然步长为1的自增ID主键在MySQL中的效率是最高的,此处涉及MySQL的底层,后续博主会专门出一篇博客介绍。使用Navicat设置MySQL数据库的默认时间可以使用CURRENT_TIMESTAMP,如下图所示:
-
【推荐】表的命名最好是遵循“业务名称_表的作用”。
正例:alipay_task / force_project / trade_config -
【推荐】库名与应用名称尽量一致。
-
【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
瑞:博主认为本条应该是【强制】,因为无论什么时候,更新了代码含义就必须同步更新注释,不然就是典型的前人挖坑,后人踩坑,一踩一个准
- 【推荐】字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循:
1) 不是频繁修改的字段。
2) 不是唯一索引的字段。
3) 不是 varchar 超长字段,更不能是 text 字段。
正例:各业务线经常冗余存储商品名称,避免查询时需要调用 IC 服务获取。
瑞:虽然本条违反了数据库三大范式中的第一范式即字段的原子性,但是可以提高性能。比如常见的日志表,日志表通常包含大量的数据记录,并且经常需要进行快速查询,为了提高查询性能,设计者可能会选择在日志表中冗余某些信息,以避免频繁的表连接操作。但无特殊情况和业务下,不能滥用本条规约,应优先遵循三大范式,消除数据冗余和更新异常
-
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。 -
【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。
正例:无符号值可以避免误存负数,且扩大了表示范围。
| 对象 | 年龄区间 | 类型 | 字节 | 表示范围 |
|---|---|---|---|---|
| 人 | 150 岁之内 | tinyint unsigned | 1 | 无符号值:0 到 255 |
| 龟 | 数百岁 | smallint unsigned | 2 | 无符号值:0 到 65535 |
| 恐龙化石 | 数千万年 | int unsigned | 4 | 无符号值:0 到约 43 亿 |
| 太阳 | 约 50 亿年 | bigint unsigned | 8 | 无符号值:0 到约 10 的 19 次方 |
瑞:本条规约的遵守对开发者的要求较高,但确实是很好的参考
(二) 索引规约
- 【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
瑞:墨菲定律:如果事情有变坏的可能,不管这种可能性有多小,它总会发生。而且数据库主要是增删改查中的查,往往需要SQL优化的地方都是查询优化
- 【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
瑞:试想一下,一个查询SQL中join十几张表是何等壮观,数据量不大的时候还感觉不到什么,等到运行一段时间,数据量才上千的时候就能感受到明显的延迟了
- 【强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
瑞:当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。比如前缀索引,如邮箱(但是只是举例,实际上建立前缀索引是很长的情况,比如文章的标题,但是文章内容非常多),后面都是不关心的,此时为了缩小索引体积,就可以使用前缀索引
前缀索引语法:create index idx_xxxx on table_name(column(n)) ;
示例: 为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5));
可以根据索引的选择性来决定,选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的
– 选择性计算公式
select count(distinct email) / count(*) from tb_user ;
– 慢慢尝试,直到截取的数值越小,但是选择性越接近1的值
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
- 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
瑞:最左前缀法则:如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)所以创建联合索引的顺序也很重要,如果排序顺序和联合索引顺序不一致,也会导致失效。
注意 : 最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关
- 【推荐】如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
正例:where a=? and b=? order by c; 索引:a_b_c
反例:索引如果存在范围查询,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b; 索引 a_b 无法排序。
瑞:多字段排序时,也遵循最左前缀法则
- 【推荐】利用覆盖索引来进行查询操作,避免回表。
说明:如果一本书需要知道第 11 章是什么标题,会翻开第 11 章对应的那一页吗?目录浏览一下就好,这个目录就是起到覆盖索引的作用。
正例:能够建立索引的种类分为主键索引、唯一索引、普通索引三种,而覆盖索引只是一种查询的一种效果,用 explain 的结果,extra 列会出现:using index。
瑞:回表查询: 先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
-
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL改写。
正例:先快速定位需要获取的 id 段,然后再关联: SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id -
【推荐】SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts最好。
说明:
1) consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2) ref 指的是使用普通的索引(normal index)。
3) range 对索引进行范围检索。
反例:explain 表的结果,type=index,索引物理文件全扫描,速度非常慢,这个 index 级别比较 range还低,与全表扫描是小巫见大巫。 -
【推荐】建组合索引的时候,区分度最高的在最左边。
正例:如果 where a=? and b=?,a 列的几乎接近于唯一值,那么只需要单建 idx_a 索引即可。
说明:存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置。如:where c>? and d=?
那么即使 c 的区分度更高,也必须把 d 放在索引的最前列,即建立组合索引 idx_d_c。 -
【推荐】防止因字段类型不同造成的隐式转换,导致索引失效。
-
【参考】创建索引时避免有如下极端误解:
1) 索引宁滥勿缺。认为一个查询就需要建一个索引。
2) 吝啬索引的创建。认为索引会消耗空间、严重拖慢记录的更新以及行的新增速度。
3) 抵制惟一索引。认为惟一索引一律需要在应用层通过“先查后插”方式解决。
(三) SQL 语句
- 【强制】不要使用 count(列名)或 count(常量)来替代 count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
瑞:查询效率从低到高
count(字段) < count(主键 id) < count(1) ≈ count(*)所以使用 count(*)
-
【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
-
【强制】当某一列的值全是 NULL 时,count(col)的返回结果为 0,但 sum(col)的返回结果为NULL,因此使用 sum()时需注意 NPE 问题。
正例:可以使用如下方式来避免 sum 的 NPE 问题:SELECT IFNULL(SUM(column), 0) FROM table;
瑞:NPE(java.lang.NullPointerException): 空指针异常。
-
【强制】使用 ISNULL()来判断是否为 NULL 值。
说明:NULL 与任何值的直接比较都为 NULL。
1) NULL<>NULL 的返回结果是 NULL,而不是 false。
2) NULL=NULL 的返回结果是 NULL,而不是 true。
3) NULL<>1 的返回结果是 NULL,而不是 true。
反例:在 SQL 语句中,如果在 null 前换行,影响可读性。select * from table where column1 is null and column3 is not null; 而`ISNULL(column)`是一个整体,简洁易懂。从性能数据上分析,`ISNULL(column)`执行效率更快一些。 -
【强制】代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
-
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
瑞:其实外键概念就是业务逻辑的一部分,理应通过Java后端程序进行处理。博主认为把数据库当成数据持久化的工具即可,不要过多依赖其中的功能。否则一旦要换数据库,比如MySQL换Oracle或者说你的公司使用OceanBase之类的国产数据库,原功能在新数据库有平替的还好,只是要增加一些学习成本,但如果原功能在新的数据库没有平替功能或者较难移植的情况下,阁下该如何应对?但是换个角度思考,如果只是把数据库当成数据存放的中间件,只依赖于增删改查的接口,试问无论是关系型还是非关系型数据库,哪个没有这四个接口?而且,凡是数据库能用SQL实现的功能,Java不都可以吗,无非就是效率的问题,命运还是要捏在自己手里。
- 【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
瑞:同上,博主认为把数据库当成数据持久化的工具即可,不要过多依赖其中的功能。否则一旦要换数据库,比如MySQL换Oracle或者说你的公司使用OceanBase之类的国产数据库,原功能在新数据库有平替的还好,只是要增加一些学习成本,但如果原功能在新的数据库没有平替功能或者较难移植的情况下,阁下该如何应对?但是换个角度思考,如果只是把数据库当成数据存放的中间件,只依赖于增删改查的接口,试问无论是关系型还是非关系型数据库,哪个没有这四个接口?而且,凡是数据库能用SQL实现的功能,Java不都可以吗,无非就是效率的问题,命运还是要捏在自己手里。
- 【强制】数据订正(特别是删除或修改记录操作)时,要先 select,避免出现误删除,确认无误才能执行更新语句。
瑞:很好的习惯,请务必牢记本条。本条写的执行更新语句,博主认为是默认删除为逻辑删除,即通过is_deleted字段为1更新语句软删除数据
- 【强制】对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。
说明:对多表进行查询记录、更新记录、删除记录时,如果对操作列没有限定表的别名(或表名),并且操作列在多个表中存在时,就会抛异常。
正例:select t1.name from table_first as t1 , table_second as t2 where t1.id=t2.id;
反例:在某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现出 1052 异常:Column ‘name’ in field list is ambiguous。
瑞:此条规定为隐藏多年才会显形的坑,虽然有经验的程序员很快就能定位原因,但还是在一开始编写SQL的时候就把别名带上最好,别名请参照下一条
- 【推荐】SQL 语句中表的别名前加 as,并且以 t1、t2、t3、…的顺序依次命名。
说明:1)别名可以是表的简称,或者是根据表出现的顺序,以 t1、t2、t3 的方式命名。2)别名前加 as 使别名更容易识别。
正例:select t1.name from table_first as t1, table_second as t2 where t1.id=t2.id;
瑞:不加as的都是小可爱,别问为什么
- 【推荐】in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个之内。
瑞:当使用IN操作符时,如果后面的值列表很长,MySQL可能无法有效地使用索引,导致查询性能下降。
-
【参考】因国际化需要,所有的字符存储与表示,均采用 utf8 字符集,那么字符计数方法需要注意。
说明:
SELECT LENGTH(“轻松工作”); 返回为 12
SELECT CHARACTER_LENGTH(“轻松工作”); 返回为 4
如果需要存储表情,那么选择 utf8mb4 来进行存储,注意它与 utf8 编码的区别。 -
【参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE无事务且不触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句。
说明:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。
(四) ORM 映射
- 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:1)增加查询分析器解析成本。2)增减字段容易与 resultMap 配置不一致。3)无用字段增加网络消耗,尤其是 text 类型的字段。
瑞:尽量使用覆盖索引,减少
select *查询字段不需要回表查询的就是覆盖索引,所以使用select * 查询很容易超出覆盖索引的范围,需要回表查询。而且使用它对某些权限不够高的开发人员很不友好,由于权限问题,不能对数据库进行直接操作,只能使用接口测试,此时的select * 对该同学就是大坑
- 【强制】POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行字段与属性之间的映射。
说明:参见定义 POJO 类以及数据库字段定义规定,在 sql.xml 增加映射,是必须的。
瑞:关于本条,需要结合本系列第一篇【编程规约】中的(一)命名风格的第8条:【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。
以及本篇章中的(一)建表规约的第1条:【强制】:表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是,0 表示否)。
- 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义
;反过来,每一个表也必然有一个 与之对应。
说明:配置映射关系,使字段与 DO 类解耦,方便维护。
瑞:DO(Data Object): 阿里巴巴专指数据库表一一对应的 POJO 类。
- 【强制】sql.xml 配置参数使用:#{},#param# 不要使用${} 此种方式容易出现 SQL 注入。
瑞:关于本条,需要结合本系列第四篇【安全规约】中的第3条:【强制】用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定,防止 SQL 注入,禁止字符串拼接 SQL 访问数据库。反例:某系统签名大量被恶意修改,即是因为对于危险字符 # --没有进行转义,导致数据库更新时,where后边的信息被注释掉,对全库进行更新。
❗️本条为神坑 ❗️ 有小可爱在使用 JDBC 编写SQL时为了方便调试❌选择用如String.format的方式拼接SQL语句❌,拼接出的SQL语句如下所示,假设现在用户使用Ray ' --(注意要空格,SQL注入)为需要修改的用户名,直接导致where语句之后的信息全部被注释,导致了全表更新❗️ ❗️ ❗️
❌UPDATE `user` SET nick_name = 'Ray '-- ’ WHERE is_deleted = 0 and id = 1❌
- 【强制】iBATIS 自带的 queryForList(String statementName,int start,int size)不推荐使用。
说明:其实现方式是在数据库取到 statementName 对应的 SQL 语句的所有记录,再通过 subList 取start,size 的子集合。
正例:
Map<String, Object> map = new HashMap<>();
map.put("start", start);
map.put("size", size);
-
【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
反例:某同学为避免写一个\ -
【强制】更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间。
瑞:如果怕忘记更新,可以但不推荐(因为博主推荐和数据库功能解耦,更新时间显然使用Java也很容易实现)在数据库设计为默认更新。使用Navicat设置MySQL数据库的默认时间可以使用
CURRENT_TIMESTAMP,如下图所示:
-
【推荐】不要写一个大而全的数据更新接口。传入为 POJO 类,不管是不是自己的目标更新字段,都进行 update table set c1=value1,c2=value2,c3=value3; 这是不对的。执行 SQL 时,不要更新无改动的字段,一是易出错;二是效率低;三是增加 binlog 存储。
-
【参考】@Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
-
【参考】
中的 compareValue 是与属性值对比的常量,一般是数字,表示相等时带上此条件; 表示不为空且不为 null 时执行; 表示不为 null 值时执行。
附:雪花算法(Java)
雪花算法(Snowflake)是一种分布式系统中生成唯一ID的方法,它可以保证在分布式环境下生成的ID是唯一的。以下是一个简单的Java实现:
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* 基于雪花算法的ID生成器 - 工具类
*
* @author LiaoYuXing-Ray
* @version 1.0
* @createDate 2023/9/7 19:48
**/
public class RayIdWorker {
/**
* 开始时间戳(2023-09-07)
*/
private final static long twepoch = 1672444800000L;
/**
* 机器id所占的位数
*/
private final static long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final static long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31(二进制:11111)
*/
private final static long maxWorkerId = ~(-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31(二进制:11111)
*/
private final static long maxDatacenterId = ~(-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final static long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final static long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final static long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095(二进制:111111111111)
*/
private final static long sequenceMask = ~(-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private final long workerId;
/**
* 数据中心ID(0~31)
*/
private final long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
public RayIdWorker() {
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* 构造方法
*
* @param workerId 工作机器ID(0~31)
* @param datacenterId 数据中心ID(0~31)
* @author LiaoYuXing-Ray 2023/9/7 20:03
**/
public RayIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return long ID
* @author LiaoYuXing-Ray 2023/9/12 20:04
**/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID便宜组合生成最终ID,并返回ID
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
}
/**
* 获取下一个ID
*
* @return long ID
* @author LiaoYuXing-Ray 2023/9/12 20:04
**/
public synchronized String nextStringId() {
return String.valueOf(this.nextId());
}
public static RayIdWorker getInstance() {
return new RayIdWorker();
}
/**
* 初始化工作机器ID(0~31)
*
* @param datacenterId 数据中心ID(0~31)
* @param maxWorkerId 支持的最大机器id,结果是31(二进制:11111)
* @return long
* @author LiaoYuXing-Ray 2024/1/14 14:33
**/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuilder mpid = new StringBuilder();
mpid.append(datacenterId);
// 获取当前Java虚拟机的名称
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
从名称中提取JVM进程ID(PID),并将其添加到mpid中
格式为:datacenterId + "@" + JVM进程ID
*/
mpid.append(name.split("@")[0]);
}
/*
Mac + PID 的 hashcode 获取16个低位 2023/9/12 20:10
计算mpid的哈希码,并取其低16位
这样可以确保结果在16个低位范围内
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* 获取数据标识id部分
*
* @param maxDatacenterId 支持的最大数据标识id,结果是31(二进制:11111)
* @return long
* @author LiaoYuXing-Ray 2023/9/12 20:11
**/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
if (mac != null && mac.length > 0) {
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
} else {
id = 1L;
}
}
} catch (Exception e) {
System.out.println("getDatacenterId:" + e.getMessage());
}
return id;
}
/**
* 生成一个大于给定时间戳的下一个时间戳
*
* @param lastTimestamp 给定时间戳
* @return long 大于给定时间戳的下一个时间戳
* @author LiaoYuXing-Ray 2024/1/14 14:28
**/
protected long tilNextMillis(long lastTimestamp) {
// 生成一个新的时间戳
long timestamp = timeGen();
// 循环检查新的时间戳是否小于等于给定的时间戳
while (timestamp <= lastTimestamp) {
// 如果小于等于,则继续生成新的时间戳
timestamp = timeGen();
}
// 返回大于给定时间戳的新的时间戳
return timestamp;
}
/**
* 生成一个新的时间戳
*
* @return long 新的时间戳
* @author LiaoYuXing-Ray 2023/9/12 20:11
**/
protected long timeGen() {
return System.currentTimeMillis();
}
// 使用示例:基于雪花算法生成10个长整型ID和10个字符串型ID
public static void main(String[] args) {
RayIdWorker idWorker = RayIdWorker.getInstance();
for (int i = 0; i < 10; i++) {
System.out.println(idWorker.nextId());
System.out.println(idWorker.nextStringId());
}
}
}
雪花算法(Snowflake)是一种分布式系统中生成唯一ID的方法,它可以保证在分布式环境下生成的ID是唯一的。效果如下图所示:
如果觉得这篇文章对您有所帮助的话,请动动小手点波关注,你的点赞收藏⭐️转发评论都是对博主最好的支持~