YOLOv5改进系列(26)——添加RFAConv注意力卷积(感受野注意力卷积运算)


 【YOLOv5改进系列】前期回顾:
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
YOLOv5改进系列(2)——添加CBAM注意力机制
YOLOv5改进系列(3)——添加CA注意力机制
YOLOv5改进系列(4)——添加ECA注意力机制
YOLOv5改进系列(5)——替换主干网络之 MobileNetV3
YOLOv5改进系列(6)——替换主干网络之 ShuffleNetV2
YOLOv5改进系列(7)——添加SimAM注意力机制
YOLOv5改进系列(8)——添加SOCA注意力机制
YOLOv5改进系列(9)——替换主干网络之EfficientNetv2
YOLOv5改进系列(10)——替换主干网络之GhostNet
YOLOv5改进系列(11)——添加损失函数之EIoU、AlphaIoU、SIoU、WIoU
YOLOv5改进系列(12)——更换Neck之BiFPN
YOLOv5改进系列(13)——更换激活函数之SiLU,ReLU,ELU,Hardswish,Mish,Softplus,AconC系列等
YOLOv5改进系列(14)——更换NMS(非极大抑制)之 DIoU-NMS、CIoU-NMS、EIoU-NMS、GIoU-NMS 、SIoU-NMS、Soft-NMS
YOLOv5改进系列(15)——增加小目标检测层
YOLOv5改进系列(16)——添加EMA注意力机制(ICASSP2023|实测涨点)
YOLOv5改进系列(17)——更换IoU之MPDIoU(ELSEVIER 2023|超越WIoU、EIoU等|实测涨点)
YOLOv5改进系列(18)——更换Neck之AFPN(全新渐进特征金字塔|超越PAFPN|实测涨点)
YOLOv5改进系列(19)——替换主干网络之Swin TransformerV1(参数量更小的ViT模型)
YOLOv5改进系列(20)——添加BiFormer注意力机制(CVPR2023|小目标涨点神器)
YOLOv5改进系列(21)——替换主干网络之RepViT(清华 ICCV 2023|最新开源移动端ViT)
YOLOv5改进系列(22)——替换主干网络之MobileViTv1(一种轻量级的、通用的移动设备 ViT)
YOLOv5改进系列(23)——替换主干网络之MobileViTv2(移动视觉 Transformer 的高效可分离自注意力机制)
YOLOv5改进系列(24)——替换主干网络之MobileViTv3(移动端轻量化网络的进一步升级)
YOLOv5改进系列(25)——添加LSKNet注意力机制(大选择性卷积核的领域首次探索)

目录
一、RFAConv介绍
1.1 RFAConv简介
1.2 RFAConv网络结构
(1)RFAConv
(2)RFCAConv
(3)RFCBAMConv
二、RFAConv核心代码讲解
① class Bottleneck1
② class RFAConv
③ Bottleneck_RFAConv
三、具体添加方法
3.1 添加顺序
3.2 具体添加步骤
第①步:在common.py中添加RFAConv模块
第②步:在yolo.py文件里的parse_model函数加入类名
第③步:创建自定义的yaml文件
第④步:验证是否加入成功
本人YOLOv5系列导航

一、RFAConv介绍
- 论文题目:《RFAConv: Innovating Spatial Attention and Standard Convolutional Operation》
- 论文地址:https://arxiv.org/pdf/2304.03198.pdf
- 代码实现:GitHub - Liuchen1997/RFAConv: RAFConv: Innovating Spatital Attention and Standard Convolutional Operation
1.1 RFAConv简介
空间注意力机制的局限性
空间注意力机制就是寻找网络中最重要的部位进行处理。旨在提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。
空间注意力机制从本质上解决了卷积核参数共享问题。然而,空间注意力生成的注意图所包含的信息对于大尺寸卷积核是不够的。
RFAConv的贡献
针对以上不足,作者提出了一种新的注意机制——感受野注意力(Receptive-Field Attention, RFA)。现有的空间注意力,如卷积块注意力模块(CBAM)和协调注意力(CA),都存在着只关注空间特征,并没有完全解决卷积核参数共享的问题。
相反,RFA不仅关注感受野空间特征,而且为大尺寸卷积核提供了有效的注意力权重。
由RFA开发的感受野注意卷积运算(RFAConv)代表了一种取代标准卷积运算的新方法。它可以显著提高网络性能,但是几乎可以忽略不计的计算成本和参数增量。RFAConv的核心思想是将空间注意力机制与卷积操作相结合,与感受野特征信息交互以学习注意力图,从而提高卷积神经网络(CNN)的性能。
1.2 RFAConv网络结构
(1)RFAConv
具有3×3大小卷积核的RFAConv的总体结构如下图所示:
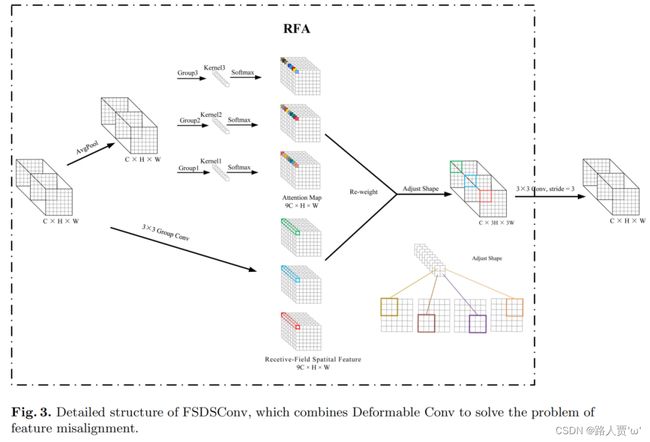
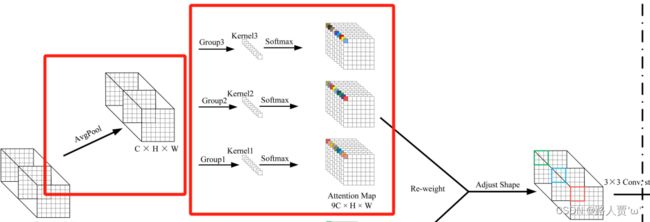
我们先看上半部分:
- 首先,通过使用AvgPool池化每个感受野特征的全局信息。
- 然后,通过1×1的组卷积运算与信息交互。
- 最后,softmax用于强调感受野特征中每个特征的重要性。
目的:为了减少额外的的计算开销和参数数量。
计算公式:

g表示分组卷积,k表示卷积核的大小,Norm代表规范化,X表示输入特征图,F是通过将注意力图![]() 与变换的感受野空间特征
与变换的感受野空间特征![]() 相乘而获得的。
相乘而获得的。
下半部分:
通过快速分组卷积提取感受野特征,替换了原来比较慢的提取感受野特征的方法。
(2)RFCAConv
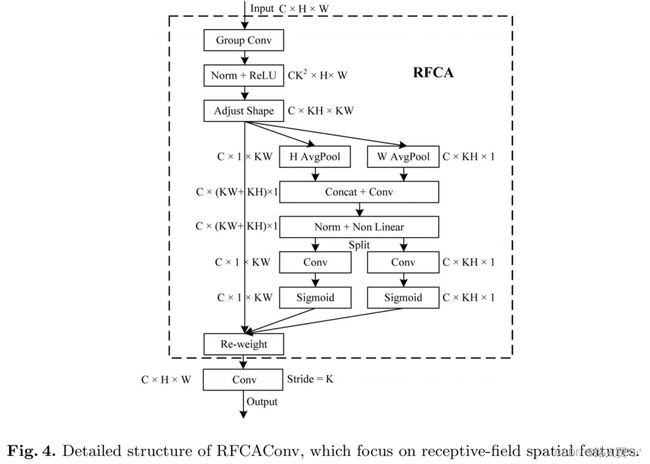
与RFA类似,使用stride为k的k×k的最终卷积运算来提取特征信息。
(3)RFCBAMConv

为了比原始的CBAM减少计算开销,可以使用SE注意力来代替RFCBAM中的CAM。
二、RFAConv核心代码讲解
源码太长读不下去,找了核心代码读一读吧~
from einops import rearrange
class Bottleneck1(nn.Module):
"""Standard bottleneck."""
# __init__ 方法:初始化函数
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
# 计算隐藏通道数
c_ = int(c2 * e) # hidden channels
# 两个卷积层,分别是输入通道数到隐藏通道数和隐藏通道数到输出通道数的卷积。
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
# 判断是否使用快捷连接,条件是启用快捷连接并且输入通道数等于输出通道数。
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class RFAConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride=1):
super().__init__()
# 存储卷积核的尺寸
self.kernel_size = kernel_size
# 生成权重
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1,
groups=in_channel, bias=False))
# 生成特征
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2,
stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
self.conv = Conv(in_channel, out_channel, k=kernel_size, s=kernel_size, p=0)
def forward(self, x):
b, c = x.shape[0:2]
weight = self.get_weight(x)
h, w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h,
w) # b c*kernel**2,h,w -> b c k**2 h w
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
# b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)
# Bottleneck1的子类
class Bottleneck_RFAConv(Bottleneck1):
"""Standard bottleneck with RFAConv."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFAConv(c_, c2, k[1])
# C3的子类
class C3_RFAConv(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_RFAConv(c_, c_, shortcut, g, k=(1, 3), e=1.0) for _ in range(n)))① class Bottleneck1
这是一个标准的残差块,在以前代码讲解中我们讲过很多次。
首先,通过__init__ 方法初始化函数,然后计算隐藏通道数 c_,即第一个卷积层的输出通道数。
再定义两个卷积层 cv1 和 cv2,分别将输入通道数映射到隐藏通道数,接着从隐藏通道数映射到输出通道数。
最后通过self.add判断是否使用shortcut。
② class RFAConv
这个类就是实现了具有区域注意力机制的卷积操作,通过生成权重并将其应用到输入特征上,以获得加权的特征表示。最终,通过卷积操作将这些加权的特征映射到输出通道数。
其中,self.get_weight包含两个子模块的顺序模块,用于生成权重。
- 第一个子模块是一个平均池化层,用于降低空间分辨率。
- 第二个子模块是一个 1x1 的卷积层,用于生成权重,并通过设置
groups=in_channel实现通道间的独立
③ Bottleneck_RFAConv
这个类是①的子类,参数也和①一样,就不细讲了~
目的是在残差块结构中引入区域注意力机制,从而提高模型对输入数据的关注度。
④class C3_RFAConv
它是 C3 类的子类,通过引入 Bottleneck_RFAConv 模块实现了区域注意力机制。
目的是在 C3 模块结构中引入区域注意力机制,通过使用 Bottleneck_RFAConv 模块替代标准的瓶颈模块。这样可以在模块内引入区域注意力,从而在整个 C3 模块内提高模型对输入数据的关注度。
三、具体添加方法
3.1 添加顺序
(1)models/common.py --> 加入新增的网络结构
(2) models/yolo.py --> 设定网络结构的传参细节,将RFAConv系列类名加入其中。(当新的自定义模块中存在输入输出维度时,要使用qw调整输出维度)
(3) models/yolov5*.yaml --> 新建一个文件夹,如yolov5s_RFAConv.yaml,修改现有模型结构配置文件。(当引入新的层时,要修改后续的结构中的from参数)
(4) train.py --> 修改‘--cfg’默认参数,训练时指定模型结构配置文件
3.2 具体添加步骤
第①步:在common.py中添加RFAConv模块
将下面的RFAConv代码复制粘贴到common.py文件的末尾
from einops import rearrange
class Bottleneck1(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class RFAConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride=1):
super().__init__()
self.kernel_size = kernel_size
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1,
groups=in_channel, bias=False))
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2,
stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
self.conv = Conv(in_channel, out_channel, k=kernel_size, s=kernel_size, p=0)
def forward(self, x):
b, c = x.shape[0:2]
weight = self.get_weight(x)
h, w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h,
w) # b c*kernel**2,h,w -> b c k**2 h w
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
# b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)
class Bottleneck_RFAConv(Bottleneck1):
"""Standard bottleneck with RFAConv."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFAConv(c_, c2, k[1])
class C3_RFAConv(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_RFAConv(c_, c_, shortcut, g, k=(1, 3), e=1.0) for _ in range(n)))第②步:在yolo.py文件里的parse_model函数加入类名
首先找到yolo.py里面parse_model函数的这一行
 加入 RFAConv、C3_RFAConv 这两个模块
加入 RFAConv、C3_RFAConv 这两个模块

第③步:创建自定义的yaml文件
第1种,更改Conv模块
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, RFAConv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, RFAConv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, RFAConv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, RFAConv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, RFAConv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, RFAConv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第2种,更改C3模块
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_RFAConv, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_RFAConv, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_RFAConv, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_RFAConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_RFAConv, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_RFAConv, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_RFAConv, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_RFAConv, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第④步:验证是否加入成功
运行yolo.py
第1种
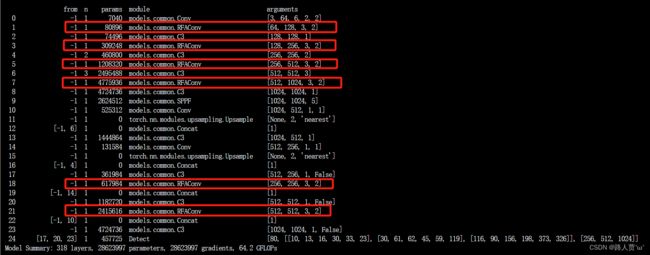
第2种
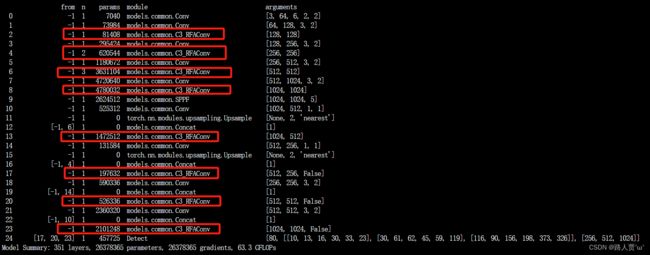
这样就OK啦!
代码参考:
优化改进YOLOv5算法之感受野注意力卷积运算(RFAConv),效果秒杀CBAM和CA等-CSDN博客
本人YOLOv5系列导航
YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
YOLOv5入门实践系列:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)
