python基础学习
缩⼩图像(或称为下采样(subsampled)或降采样(downsampled))的主要⽬的有两个:1、使得图像符合显⽰区域的⼤⼩;2、⽣成对应图像的缩略图。
放⼤图像(或称为上采样(upsampling)或图像插值(interpolating))的主要⽬的是放⼤原图像,从⽽可以显⽰在更⾼分辨率的显⽰设备上。
下采样原理:对于⼀副图像I尺⼨为M N,对起进⾏s倍下采样,即得到(M/s)(N/s)尺⼨的分辨率图像,当然,s应该是M和N的公约数才可以,如果考虑是矩阵形式的图像,就是把原始图像s*s窗⼝内的图像编程⼀个像素,这个像素点的值就是窗⼝内所有像素的均值。
Pk = Σ Ii / s2
上采样原理:图像放⼤⼏乎都是采⽤内插值⽅法,即在原有图像像素的基础上在像素点之间采⽤合适的插值算法插⼊新的元素。
插值算法还包括了传统插值,基于边缘图像的插值,还有基于区域的图像插值。
目标检测:1.给每个像素生成若干锚框
2.通过计算IOU来给锚框分类
3.通过预测偏差和锚框来对预测边界框。
nms有两种:1)把所有的类放在一起,选最大的iou去掉。
2)每一类分开进行nms
提升精读思路:根据数据挑选增强、使用新模型、新优化算法、多个模型融合,测试时使用增强。
SVM:支持向量机,通过一个超平面把数据分类,是一种监督学习,但是往往在实际过程中,数据是不好直接被平面分类的,所以就在应用SVM之前对数据进行非线性变换。在不改变SVM内部工作原理的情况下获得非线性决策边界。
python
最重要的是缩进
变量,字符串,原始字符串,长字符串
- (如无必要,勿增实体)
- 里面变量不能以数字开头
- 单引号、双引号、三引号
- 转义字符都是以反斜杠开头

-
\路径里面的双斜杠,就是用反斜杠来转义反斜杠!
-
在字符串前面加一个原始字符r,表示字符串后的反斜杠都是字符,而不是转义字符
-
字符串最后是反斜杠,说明表示未完待续,程序不会执行,可以继续写
-
字符串也可以作乘法输出

条件分支、while循环
- int()
- if 条件:
- else:记住后面都有冒号哦!
-

- is 、is not 判断两个对象的id是否相等的
- Python3 中,一行可以书写多个语句=》;
- 也可以多行写一个语句,用反斜杠就可以 \
- while_条件:
- 语句
python逻辑运算符
- and 从左到右计算表达式,若所有的都为真,则返回最后一个值,若存在假,返回第一个假值.同时也是与的逻辑作用 遇假出假
- or 从左到右计算表达式,只要遇到真值就返回那个真是,如果表达式结束依旧没有遇到真值,就返回最后一个假值.同时也是或的逻辑作用 遇真出真
- 以上也叫做短路逻辑(short-circuit logic)
- not 取反,非逻辑作用
- (10 < cost) and (cost < 50)等价于 10 < cost < 50
- random.getstate() random.setstate
数字类型
int
python里整除了,最后结果还是以浮点数形式存在

foalt
-
python中小数是以浮点数形式存放的
-

-
精确计算浮点数
-
decimal.Decimal()实例对象
-
比较的时候还是要用同一对象进行比较,不能用0.3直接和decimal对象比较,那是不同对象的,会报错。
-

-
python科学计数法,e表示10的幂次方
-
将数字转换为科学计数法
num = 123456789
print(“{:.2e}”.format(num)) # 输出为1.23e+08

那个{:.xe}x是表示小数点后几位数字
复数

- python是向下取整,int(5.5)=5
- 取变量类型用instance()、type()
数值运算

- //地板除
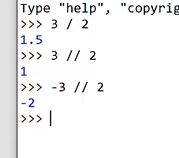
 - [ ] 用int转换小数字符串的时候,会截断
- [ ] 用int转换小数字符串的时候,会截断

- pow (x,y,z) y可以为负数,就做log函数,还有z是求余的运算。

布尔类型
- 值为false

- 可以这样理解,bool类型是特殊的整数类型
- python所有对象都能进行真值测试
运算优先级

- 当学生只能硬记,由上至下,优先级越高!
流程图

思维导图
分支和循环
- 条件表达式

- 用一个小括号来把代码封起来,等价于\实现多行代码连续输入。
分支结构嵌套
-

-
while break 跳出循环体
-
continue 跳出本次循环,回到循环体
-
while else 语句:当循环完整结束后会执行 else

-
break和continue都是作用于最小循环
for
- for in中的可迭代对象
- range
是生成一个数字序列,其参数必须是整型。

列表
- 注意最后的,还可以倒序输出。
- 增 :append()、 extend()

- 也可以使用切片的方法去做

和extend的原理一样 - insert( x,y) x插入的位置,y是插入的元素
-

- 删除: remove()但是有多个匹配的元素,只会删除第一个,如果没有匹配到,就会报错。
- pop() 删除 某个位置的元素
- clear()清空
-

- 列表元素的替换:

- 列表排序:sort()从小到大排序

或者在sort(reverse=True)直接在sort里翻转 - 列表反转:reverse()
- index() 索引 index(a,b,c) a是元素内容、bc分别表示起始位置
 - [ ] 可以通过该方法替换未知索引的内容
- [ ] 可以通过该方法替换未知索引的内容

- count() 计算列表里有多少该元素
- copy()浅拷贝
-
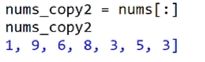
- 负数索引表示从数组的末尾开始往前数的元素


- 列表 加法 乘法

- 嵌套列表
- 嵌套列表输出

- 只给一个下标索引,给出的是以行为单位的整个列表
- 初始化列表

- is判断两个变量是不是指向的同一对象。
- 若字符串是相同,则两个对象是指向的同一对象;而列表不是。
-

为什么不能用B=[ [ 0 ] * 3 ] *3来初始化列表
如下图:

- 在python中,变量不是盒子,是引用
- 我们要真正获得两个独立的列表,就需要用到copy()或者切片

在C++中类似,不能对数组进行直接复制,拷贝,只能通过for循环,对数组中每一个元素逐个进行复制。
浅拷贝和深拷贝
-
在面对多维列表的时候,在使用copy就不行了,因为浅拷贝只是对外围数据进行拷贝,对内层数据还是以引用形式存在的。
-

-
copy模块 import copy
-
copy.deepcopy()深拷贝
-
copy.copy()浅拷贝
python虚拟机 pvm
列表推导式(用的c语言进行的)
- 结果是一个列表

- 其执行顺序为 先执行for 的迭代 ,然后再执行,for后判断语句。

- 嵌套的列表推到式

- 可以用嵌套的列表推导式来表示笛卡尔乘积,每个for后面都可以加一个if来进行条件筛选
-

KISS原则
要保证代码简洁好看,不介意多行列表嵌套式,容易看不懂
元组tuple
不可逆的、圆括号、也可以不带括号、也支持切片操作
-
count、index()
-
支持拷贝

-
支持嵌套


生成一个元素的元组:x = <520,> -
打包和解包:一堆数据生成一个元组称为元组的打包,用一个元组对几个变量进行赋值,称为解包。打包和解包用于所有序列。注意解包的时候,需要左右两边的变量数量要一致。
-
除非用以下这个方式:
-

_:表示匿名变量
python中多重赋值就是这样的来的。

元组中的元素是不可变的,但是元组中的元素如果指向的是可变的元素,那就可以改变。如下:

字符串
- 用切片来实现回文数的查找
-

字符串里的方法:

capitalize()将字符串首字母大写
title()各单词首字母大写
swapcase()将原字符串大小写翻转
upper()将所有字母都大写
lower()将所有字母都小写
casefold()小写,并且可以处理其他语言

center(w)w>字符串长度则,将其居中。小于则直接输出。
ljust左对齐
rjust右对齐
zfill()字符串前面补0,不是单纯的补,如果字符串前面有符号,在前面也会有符号站位

count(a,b,c)bc分别是指定的查找位置参数
find()rfind()从左往右、从右往左找
index()找不到就抛出异常

- 使用空格来替换制表符,返回一个新的字符串
- replace(old,new,count==-1)指定新字符串替换旧字符串,count默认为-1,即为替换全部

配合str.maketrans()使用,相当于是在里面生成了一个转换规则。
依照这个转化规则执行:

还可以再加一个参数,将指定的字符串忽略掉
方法 含义
capitalize() 把字符串的第一个字符改为大写
casefold() 把整个字符串的所有字符改为小写
center(width) 将字符串居中,并使用空格填充至长度width的新字符串
count(sub[,start[,end]]) 返回sub在字符串里边出现的次数,start和end参数表示范围,可选
encode(encoding=‘utf-8’, errors=‘strict’) 以encoding指定的编码格式对字符串进行编码
endswith(sub[,start[,end]]) 检查字符串是否以sub子字符串结束,如果是返回True,否则返回False。start和end参数表示范围,可选
expandtabs([tabsize=8]) 把字符串中的tab符号(\t)转换为空格,如不指定参数,默认的空格数是tabsize=8
find(sub[,start[,end]]) 检测sub是否包含在字符串中,如果有则返回索引值,否则返回-1,start和end参数表示范围,可选
index(sub[,start[,end]]) 跟find方法一样,不过如果sub不在string中会产生一个异常
isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False
isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回True,否则返回False
isdecimal() 如果字符串只包含十进制数字则返回True,否则返回False
isdigit() 如果字符串只包含数字则返回True,否则返回False
islower() 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回True,否则返回False
isnumeric() 如果字符串中只包含数字字符,则返回True,否则返回False
isspace() 如果字符串中只包含空格,则返回True,否则返回False
istitle() 如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回True,否则返回False
isupper() 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回True,否则返回False
join(sub) 以字符串作为分隔符,插入到sub中所有的字符之间。>>> str5 = ‘Fishc’ >>> str5.join(‘12345’) ‘1Fishc2Fishc3Fishc4Fishc5’
ljust(width) 返回一个左对齐的字符串,并使用空格填充至长度为width的新字符串
lower() 转换字符串中所有大写字符为小写
lstrip() 去掉字符串左边的所有空格
partition(sub) 找到子字符串sub,把字符串分成一个3元组(pre_sub,sub,fol_sub),如果字符串中不包含sub则返回(‘原字符串’, ’’, ’’)
replace(old,new[,count]) 把字符串中的old子字符串替换成new子字符串,如果count指定,则替换不超过count次。>>> str7 = ‘i love fishdm and seven’ >>> str7.replace(‘e’,‘E’,2) 输出’i lovE fishdm and sEven’
rfind(sub[,start[,end]]) 类似于find()方法,不过是从右边开始查找
rindex(sub[,start[,end]]) 类似于index()方法,不过是从右边开始
rjust(width) 返回一个右对齐的字符串,并使用空格填充至长度为width的新字符串
rpartition(sub) 类似于partition()方法,不过是从右边开始查找
rstrip() 删除字符串末尾的空格
split(sep=None, maxsplit=-1) 不带参数默认是以空格为分隔符切片字符串,如果maxsplit参数有设置,则仅分隔maxsplit个子字符串,返回切片后的子字符串拼接的列表。>>> str7.split () [‘i’, ‘love’, ‘fishdm’, ‘and’, ‘seven’]
splitlines(([keepends])) 按照‘\n’分隔,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepends行
startswith(prefix[,start[,end]]) 检查字符串是否以prefix开头,是则返回True,否则返回False。start和end参数可以指定范围检查,可选
strip([chars]) 删除字符串前边和后边所有的空格,chars参数可以定制删除的字符,可选
swapcase() 翻转字符串中的大小写
title() 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串
translate(table) 根据table的规则(可以由str.maketrans(‘a’,‘b’)定制)转换字符串中的字符。>>> str8 = ‘aaasss sssaaa’ >>> str8.translate(str.maketrans(‘s’,‘b’)) ‘aaabbb bbbaaa’
upper() 转换字符串中的所有小写字符为大写
zfill(width) 返回长度为width的字符串,原字符串右对齐,前边用0填充