账单姓名身份证自然年去重(十亿数据中实时去重)
1、需求背景
产品提了个需求,合作方希望对之后的每笔交易账单进行姓名和身份证的自然年除重,即新来一笔交易,如果一年中这个姓名身份证已经发生过交易,则这笔交易的账单不出。乍一听起来很简单,可账单文件是五分钟出一次,相当于准实时。而且我们每年自然年除重后的交易量都在十亿以上,全中国的人几乎每年都会在我们这交易一次。这么大的数据量,数据库里根本保存不下,只保存最近十天的。而且每笔交易都去十几亿数据里查一下有没有重复,效率也是个大问题。
基于以上场景,这个需求可以归纳一下几个难点:
2、需求难点
(1)数据量大。全年十几亿数据,数据库中都不会保存这么多数据。除重也相当于十几亿数据的除重,查一条数据的姓名身份证在没在十几亿数据中。
(2)实时性要求高。五分钟出一次账单,等于每笔交易来最快要在近乎实时完成全年十几亿数据的去重,然后决定是否输出到账单文件
3、预研方案
(1)数据库sql里直接查询,存在则重复,不出账单。首先SQL里没有存一年的几十亿数据。另外,每笔交易都在数据库几十亿数据里查一下有没有,显然效率会成大问题,场景不合理,可能会出现慢查询或者影响日常数据库使用的问题。
(2)从大数据BDP进行除重后出账单。其实最初准备采用的就是这个方案,BDP里本身就存了几年的数据,又是HIVE存的,查一年的数据效率也很高。而且起初跟合作方谈的推账单方案是改为推日终账单,不再五分钟推一次账单。这样的话就可以凌晨过后,通过BDP跑批任务去处理当日所有交易的全年去重。可是就在这方案送上去,将要业务老大拍板落地的时候,合作方那边又反悔了,还是要五分钟推一次账单。那BDP批处理的方案又不适用了,因为BDP的HIVE里没有实时数据,只有前一天的数据,只有过了凌晨之后才有跑批任务跑当天的数据同步到BDP里。
(3)Redis去重。最开始业务提到要实时去重,很自然的就想到通过Redis来做,速度快效率高。但同样也有一些明显的问题,比如一个自然年十几亿的数据丢到Redis里,起码几十个G,Redis容量是个大问题。如果这样做肯定要扩容,成本激增,业务是否可以接受?另外Redis虽然是内存操作,速度很快,但面对几十亿的数据,是否也会又性能问题?
4、实际方案
通过和DBA的多次讨论和预研,最终定下的使用Redis去重的方案。为了提升查询效率和节约容量空间,在Redis的使用上,又提出了两种方案:
(1)布隆过滤器
本来想用Redis里的布隆过滤器除重。之前看过非常省空间,其他组做黑名单时刚好也有应用过,就去询问了下。说布隆过滤器虽然省空间,可以快速的查某个元素在不在里面,但有两个缺陷:
一是不能通过布隆过滤器恢复出存入的元素,只能看在不在里面,不能反推出key-value。
二是有误差存在,如果通过布隆过滤器查元素在不在,如果查的不在的话就一定不在,但如果在的话也有可能不在,是误判。
也就是说:有,不一定有,无,就一定无。
误判的原因主要是hash冲突。
容量和误差的关系:

听到这个第二点缺陷,这个方式我们场景肯定不能用了。
因为我们是生成账单,去重就是查元素在不在,如果重复了有可能是不重复,造成误判,那么就会使账单量不对,合作方发现的话肯定不愿意。
同事也说这种多用在黑名单,大部分元素都不在过滤器里,只有小部分元素在里面的场景,判断不在里面了就直接放过,在里面在进一步进入判断逻辑,可以节约一大部分判断逻辑的开销。
(2)Redis Set
查元素在不在集合里,很自然想到了存到set里,Redis也有set的数据结构,也是能快速查询元素在不在集合里。看了下Redis的文档,set查询元素在不在集合里的方法sismember(),时间复杂度O(1),也就是说查询不受集合里元素数量的影响,都能够直接查询。这样的速度特性刚好契合我们的场景。
用Redis的话还有个担心的问题,存一年几十亿数据的话,容量是个大问题。
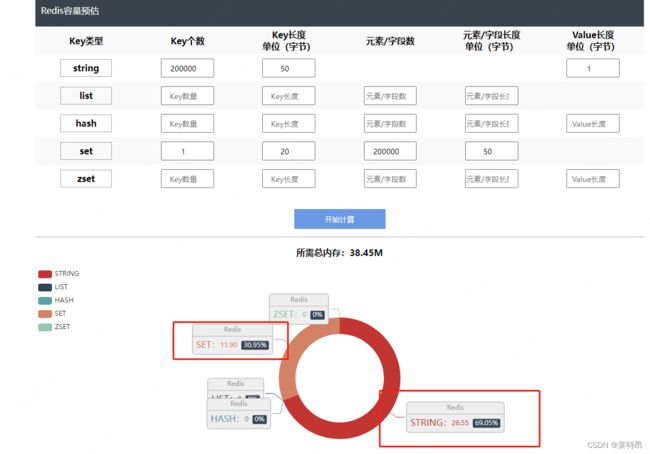
我们粗略的估算了一下这些数据的内存占用量,按字节长度估算大概需要几十个G。如果使用KV的方式存,起码上百G,带来的成本提高太大了,业务有点接受不了。
测试了下通过Redis Set的方式确实相对KV的方式能节省不少容量,Redis有对Set的压缩机制。
通过Redis容量测算工具测算的容量:
和DBA在测试环境中造数据的容量(1个Set 20W元素):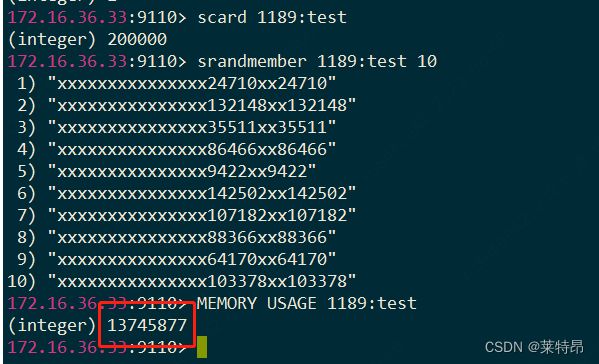
1个set插入20万这种类似姓名身份证的数据 占用内存大小13M左右 1000个set两亿的话大概13G 估算约是KV形式的一半
咨询了DBA,单Set过大的话,虽然不太会影响查询速度,但会有别的问题。比如扩容和迁移困难,可能导致扩容和迁移过程中,Redis不可用的时间加长,影响正常的Redis使用。
导师提了一种方案,可以先把数据Hash分桶,存在1000个Set,每个Set里大概几十万的数据,还可以接受。尽可能减少了大Key问题,和扩容迁移的影响。
实际也采用了这种基于Redis Set的除重方案。
5、具体实现细节
定下了通过Redis Set除重的大方案后,还有几个关键问题点:
(1)如何将十亿数据从HIVE中导出,写入到Redis集群中?
(2)Hash分桶分布是否会均匀?
(3)Redis容量以及去重效率是否满足要求?
(1)十亿数据从HIVE中导出,写入到Redis集群
首先咨询了运维,之前有操作过从生产BDP的HIVE系统中导出生产数据文件,通过文件传递到云生产上。操作起来不难,就是审批流程比较长,而且生成账单的姓名身份证又是特级敏感数据。
HIVE导出文件的关键代码语句示例:
set hive.exec.compress.output=false;
INSERT OVERWRITE LOCAL DIRECTORY '/data/bdp/bdp_etl_deploy/hduser01/rpd08/idap/export_data'
ROW format delimited fields terminated BY '|'
SELECT
name
,id_no
FROM
(
SELECT
name
,id_no
,row_number() over(partition by id_no,name order by ds asc) rn
,ds
,appid
FROM
rpd_aiot_ods_safe.idap_idasc_check_face_record_kycods
where ds>= '20230101' and ds < '20230906'
and appid in ('XXXXX','XXXX')
) t
where t.rn=1
其中用到了row_number()这种方式进行除重,通过网上查询,了解到这种除重方式相对于传统的distinct之类的效率更高,所以采用了。原理就是按row_number()函数后面语句的逻辑分组排序,取分组后的第一个rn=1,即为最早一次出现的记录。
由于Hive导出文件后自动拆分为许多小文件(最多1000个),顺便写了个Linux下合并文件的脚本:
vi merge.sh
#!/bin/bash
start=$1
end=$2
output_file="$3"
echo "文件开始序号$start"
# 遍历文件名称范围,根据自己的需求修改起始和结束值
for ((i=$start; i<=$end; i++))
do
file_name=$(printf "%06d_0" "$i") # 格式化文件名,保证文件名具有相同长度(比如从1变为0001)
cat "${file_name}" >> "${output_file}"
done
echo "文件结束序号 $file_name"
echo "文件合并完成!"
而且同组的同事之前也写过一个读取文件,导入sql数据的脚本(Java程序)。可以参考写一个读取文件,写入到Redis的脚本。
这个脚本对外暴露个接口,只需要把要写入Redis的文件路径,会按指定格式读取该文件的每行,写入到Redis。当然这就要求导出文件的时候也按照预设的格式保存每行。
读取文件的关键代码:
File hdFile = new File(filePath);
if(!hdFile.exists()) {
LOGGER.error("hdFile is not exist, filePath:{}", filePath);
}
//2. 读取文件
FileInputStream hdFileSm = null;
InputStreamReader hdReader = null;
BufferedReader hdBufReader = null;
try{
hdFileSm = new FileInputStream(filePath);
hdReader = new InputStreamReader(hdFileSm, StandardCharsets.UTF_8);
hdBufReader = new BufferedReader(hdReader);
String line = null;
List<List<String>> saveRedisMembers = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
testDeviation.add((double) 0); //初始化
}
long testSum = 0;
String folderPath = hdFile.getCanonicalFile().getParent();//获取文件夹地址
//开启循环
while ((line = hdBufReader.readLine()) != null) {
try {
//2. 解析line中的fileId和fileHash
String[] infos = line.split("\\|");
String encryptIdNo = infos[1];
String encryptName = infos[0];
//文件操作
} catch (Exception e) {
LOGGER.error("get file error,file current line:{} ,e:{}", line,e);
}
}
另外还要有一套写Redis失败的重写机制,预防Redis抖动写失败的情况。一方面是打印失败日志方便监控,另一方面会把失败的语句重新写到一个文件中,每行格式和HIVE导出的每行数据格式保持一致。这样就可以复用读取文件的接口,把失败重写的文件路径传入原读取文件接口,再跑一遍写Redis的流程。
写Redis及失败后写文件的关键代码:
/**
* 写redis失败 写入本地文件
* 已拼接过的姓名身份证
*/
private void writeFailFile(String billFilePath, String setNum, String encryptNameIdNo){
String txtFilePath = billFilePath + "\\failFile.txt";
String lineContentSeparator = "\\|";
String lineSeparator = System.lineSeparator();
BufferedWriter bw = null;
try {
FileWriter fw = new FileWriter(txtFilePath, true);
bw = new BufferedWriter(fw);
StringBuffer sb = new StringBuffer();
sb.append(encryptNameIdNo).append(lineContentSeparator);
sb.append(setNum);
sb.append(lineSeparator);
bw.write(sb.toString());
} catch (IOException e) {
LOGGER.error("writeFile failed ! fileName ={} ,encryptNameIdNo ={} , exception:{}"
,txtFilePath, encryptNameIdNo, e);
}finally {
try{
if (null != bw){
bw.close();
}
}catch (Exception e){
}
}
return;
}
对20W数据进行简单的数据导入测试。发现HIVE导出数据很快,20G数据半小时。但脚本插入Redis,每条需要大概20ms,那20W数据就需要1个多小时,1000个桶的20W数据则要1000多个小时,相当于起码40天时间,才能把HIVE里的数据初始化到Redis中。 这是业务接受不了的。
所以开始着手,脚本写入速度的优化。咨询了DBA,Redis Set支持批量写入,且批量写入的速度和单一写入的速度几乎差不多,也是20ms左右,主要耗时就在链接Redis,而不是写入。
**于是考虑在Hash分桶后,将数据缓存到本地,等到攒够同一个Set桶攒够一定数量的数据后,再批量写入Redis。**攒够多少数量写一次呢?也要试着来,在不内存溢出的前提下攒尽可能多,则能够提供更快的速度,也是空间换时间。
优化的关键代码如下:
List<List<String>> saveRedisMembers = new ArrayList<>();
//3.hash分桶
Long hash = (long) MurMurHashUtils.hashUnsigned(encryptIdNo);
Long hashIndex = hash % 1000;
//存入ArrayList 缓存分桶结果
int index = hashIndex.intValue();
while (index >= saveRedisMembers.size()) {
saveRedisMembers.add(new ArrayList<>());
}
saveRedisMembers.get(index).add(encryptName+encryptIdNo);
//单个List存够1000 批量写redis
if (saveRedisMembers.get(index).size() == 1000){
List<String> membersList = saveRedisMembers.get(index);
try {
redisDAO.sadd(getTianyuRedisKey(index) , membersList.toArray(new String[membersList.size()]));
LOGGER.debug("redis sadd 1000 index:{}",index);
}catch (Exception e) {
LOGGER.error("write redis error,e:", e);
//reids写失败 记录fail文件
for (String member : membersList) {
writeFailFile(folderPath,String.valueOf(index) , member);
}
}
//清除当前桶List缓存
saveRedisMembers.get(index).clear();
}
//结束前把所有桶剩余元素写redis
for (int index = 0; index < saveRedisMembers.size(); index++){
List<String> membersList = saveRedisMembers.get(index);
if (membersList.size() != 0) {
try {
redisDAO.sadd(getTianyuRedisKey(index) , membersList.toArray(new String[membersList.size()]));
LOGGER.debug("redis sadd remain index:{}",index);
}catch (Exception e) {
LOGGER.error("write redis error,e:", e);
//reids写失败 记录fail文件
for (String member : membersList) {
writeFailFile(folderPath,String.valueOf(index) , member);
}
}
}
saveRedisMembers.get(index).clear();
}
其中,saveRedisMembers是一个List,对应1000个桶,每个桶要缓存的姓名身份证。每个缓存数量到1000个后,就进行批量写入Redis的操作一次,同时清空对应桶的缓存。
(2)Hash分桶分布效果测试
hash算法用了MurmurHash:
MurmurHash算法:高运算性能,低碰撞率,由Austin
Appleby创建于2008年,现已应用到Hadoop、libstdc++、nginx、libmemcached等开源系统。2011年Appleby被Google雇佣,随后Google推出其变种的CityHash算法。官方只提供了C语言的实现版本。
MurmurHash是一种非加密型哈希函数,适用于一般的哈希检索操作。与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。
特点:
1.快。
MurMurHash3 比 MD5 快,差不多是MD5性能的10倍。
2.低碰撞。
MurMurHash3 128 位版本哈希值是 128 位的,跟 MD5 一样。128 位的哈希值,在数据量只有千万级别的情况下,基本不用担心碰撞。
3.高混淆。
散列值比较“均匀”,如果用于哈希表,布隆过滤器等, 元素就会均匀分布。
MurMurHash 算法家族的最新一员为MurMurHash3,支持32位和128位,推荐使用128位的MurMurHash3。是原作者被Google挖去之后基于Murmur2的缺陷做了改进。
本文项目就用了MurMurHash3,这个在谷歌包里有现成的。
可以直接通过这样使用:
import com.google.common.hash.HashFunction;
import com.google.common.hash.Hashing;
/**
* MurMurHash算法, 性能高, 碰撞率低
* @param str String
* @return Long
*/
public static Long hash(String str) {
HashFunction hashFunction = Hashing.murmur3_128();
return hashFunction.hashString(str, StandardCharsets.UTF_8).asLong();
}
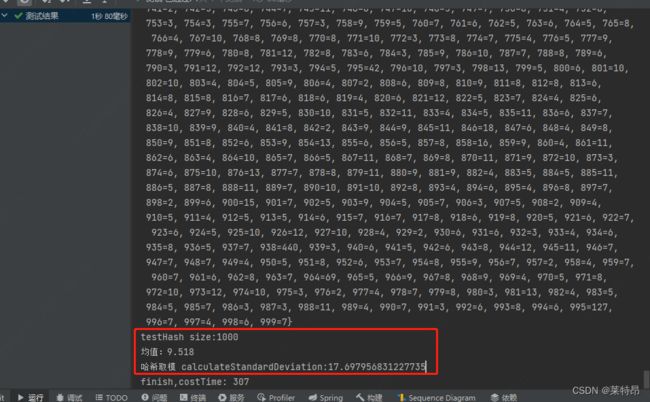
造了8500条类似姓名身份证的数据测试分布效果,hash分到1000个桶,分别用MurMurHash3哈希值对1000取模和一致性哈希两种方法。
哈希取模:
一致性哈希:
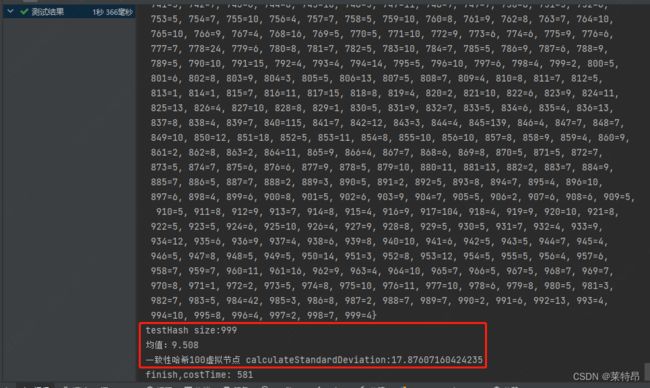
分别计算了均值和标准差,从结果上看直接对哈希值取模的分桶方式,效果更好点。
而一致性哈希主要是对频繁扩缩容的情况更好的适配,比如开始分1000个桶,过段时间需要分2000个桶了,采用一致性哈希依然能保持不错的分布均匀性。
参考网上也有类似的结论:
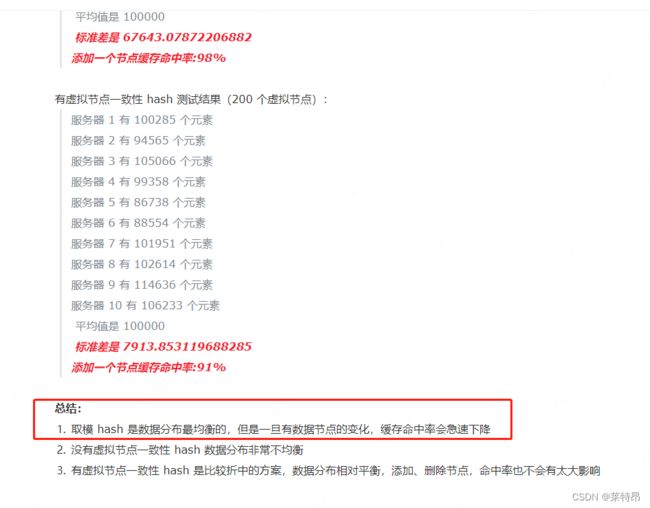

(3)Redis容量以及去重效率测试
我们造了20W条形如这种的AES加密后的姓名身份证,可以看到每条长度56字节。用Set的方式存入Redis后容量为20865877(差不多20M)

那两亿数据就是20G的内存容量占用,当前系统在使用的Redis集群最大内存54G,目前使用了10.2G,使用率19%。 也就是说存了已有数据Redis集群的占用率起码去到50%以上,而且后面会不断递增,最大可能去到40G,那么已有Redis集群的容量就不够使用了。
跟业务反馈后,同意扩容,且采用独立Redis集群的方式。与DBA评估后,新集群配置:3台8C16G +9台8C32G+硬盘200G,每月费用10000左右(proxy,observer 和cluster,主备96G容量,50G情况下资源占用62%)
(4)Redis抖动的兜底机制
需要考虑Redis抖动情况时的兜底机制。与业务沟通后,可以接受Redis抖动造成的少量账单未除重,毕竟也是多收钱,但希望能把抖动期间的数据恢复到Redis中,下次除重能除掉。不然抖动一笔,造成了下次来的相同数据都没除重,等于影响两笔。
采用的方案就是通过DB兜底,Redis抖动时,catch异常,把数据写到一个fail表。管理台子系统那边加入个定时任务,每隔一个小时就把表里的数据写到Redis里,且在每条记录上打上已恢复的标志。
Redis抖动的兜底关键代码:
//hash分桶
Long hash = (long) MurMurHashUtils.hashUnsigned(checkFaceUpdate.getIdNo());
Long hashIndex = hash % 1000;
//redis判断重复
String redisKey = getTianyuRedisKey(hashIndex);
String redisSetMember = checkFaceUpdate.getName() + checkFaceUpdate.getIdNo();
LOGGER.info("bizNo:{} , tianyu redisKey : {} , redisSetMember:{}", checkFaceUpdate.getBizSeqNo() , redisKey , redisSetMember);
try {
boolean repeat = tianyuRedisDAO.sismember(redisKey, redisSetMember);
if (repeat) {
//存在重复 打标origin
checkFaceUpdate.setOrigin(BillOriginType.HUIYAN_TIANYU_NOCHARGE.getOriginId());
LOGGER.info("bizNo:{} , tianyu redis repeat", checkFaceUpdate.getBizSeqNo());
} else {
//不重复写入redis
try {
tianyuRedisDAO.sadd(redisKey, redisSetMember);
LOGGER.info("bizNo:{} , tianyu redis sadd", checkFaceUpdate.getBizSeqNo());
} catch (Exception e) {
//写入tianyu redis异常 记录fail表 code=2
LOGGER.warn("bizNo:{} , tianyu redis write warning,e:{}", checkFaceUpdate.getBizSeqNo(),e);
TianyuRedisFailDTO tianyuRedisFailDTO = creatTianyuRedisFailDTO(checkFaceUpdate);
tianyuRedisFailDTO.setRedisSet(String.valueOf(hashIndex));//记录分桶结果
tianyuRedisFailDTO.setCode(RedisFailResultEnum.REDIS_WRITE_ERROR.getCode());
tianyuRedisFailDTO.setMsg(RedisFailResultEnum.REDIS_WRITE_ERROR.getMessage());
tianyuRedisFailDAO.insertTianyuRedisFailRecord(tianyuRedisFailDTO);
}
}
}catch (Exception e){
//读tianyu redis异常 记录fail表 code=1
LOGGER.warn("bizNo:{} , tianyu redis read warning,e:{}", checkFaceUpdate.getBizSeqNo(),e);
TianyuRedisFailDTO tianyuRedisFailDTO = creatTianyuRedisFailDTO(checkFaceUpdate);
tianyuRedisFailDTO.setRedisSet(String.valueOf(hashIndex));//记录分桶结果
tianyuRedisFailDTO.setCode(RedisFailResultEnum.REDIS_READ_ERROR.getCode());
tianyuRedisFailDTO.setMsg(RedisFailResultEnum.REDIS_READ_ERROR.getMessage());
try {
tianyuRedisFailDAO.insertTianyuRedisFailRecord(tianyuRedisFailDTO);
}catch (Exception failException) {
//写入fail表异常
LOGGER.error("bizNo:{} , orderNo:{} ,tianyu fail record write error,e:{}",checkFaceUpdate.getBizSeqNo(), checkFaceUpdate.getOrderNo() ,e);
}
}
定时任务恢复Redis数据:
@Scheduled(cron = "0 3 * * * ?")
public void recoverTianyuFailRecordScheduler() {
if (recoverTianyuFailFlag) {
tianyuTaskService.tianyuHourTask();
}
}
/**
* 每小时定时任务 同步fail表到redis
*/
@Override
public void tianyuHourTask() {
Date date = new Date();
String currentDate = DateFormatUtils.format(date, DATE_FORMAT_STR);
//抢锁 多实例只一个运行
String lockKey = "tianyuHourTask_" + currentDate;
boolean lockSuccess = redisService.tryLock(lockKey, 360);
if (!lockSuccess) {
LOG.info("tianyuHourTask:not me");
return ;
}
LOG.info("tianyuHourTask begin");
List<TianyuRedisFailDTO> tianyuRedisFailDTOList;
//查询fail表
try {
tianyuRedisFailDTOList = tianyuRedisFailDAO.queryTianyuRedisFailRecord();
} catch (Throwable th) {
LOG.warn("queryTianyuRedisFailRecord fail",th);
return;
}
//LOG.info("tianyuHourTask tianyuRedisFailDTOList size ={}",tianyuRedisFailDTOList.size());
//插入redis
for (TianyuRedisFailDTO tianyuRedisFailDTO : tianyuRedisFailDTOList){
if ("Y".equals(tianyuRedisFailDTO.getRedisSync()))continue;//已更新过的不再更新
String member = tianyuRedisFailDTO.getName() + tianyuRedisFailDTO.getIdNo();
try {
idascRedisDAO.sadd(getTianyuRedisKey(tianyuRedisFailDTO.getRedisSet()), member);
//更新fail表 标记已同步redis
tianyuRedisFailDTO.setRedisSync("Y");
tianyuRedisFailDAO.updateTianyuRedisFailRecord(tianyuRedisFailDTO);
LOG.info("tianyuHourTask update, redis key:{} member:{}",getTianyuRedisKey(tianyuRedisFailDTO.getRedisSet()),member);
} catch (Throwable th) {
LOG.warn("tianyuRedisFailDTO write redis fail",th);
}
}
LOG.info("tianyuHourTask finish");
}
(5)写账单文件
解决了前置这些问题,就剩下出账单文件的改造了。方案是在联机交易阶段,去Redis查询全年除重,如果存在重复,则写流水表记录的时候,把origin字段置为5。而出账单的子系统查询流水表出账单时,origin=5则不写账单文件。
代码可参考上面写Redis及失败后写文件的代码。
(6)上线同步历史数据的灰度策略
由于系统上线是灰度过程,会有一部分机器走新的除重逻辑,将自然年没出现的姓名身份证信息存入Redis,但走到非灰度机器的流量,则不会写Redis。所以系统全量后要把这部分遗漏的数据再重跑一遍写入Redis,由此把初始化Redis集群数据的工作划分为两个部分:1.初始化当年1月1日到发布前一星期的历史数据,顺便能够验证初始化数据脚本的可行性,即使有问题也能够有充分时间修复。2.全量后的第二天,再次初始化发版前一星期到全量当天的历史数据,保证了数据的完整性。
全量后的验证手段,DB里写表标记为除重的订单数,对比BDP全年除重后的订单数,相等则证明除重准确。
6、总结
这个需求是今年做的最大的需求了。涉及了大数据BDP HIVE,十亿级的数据迁移;Redis新集群,容量优化;迁移脚本写入Redis速度的优化;Redis抖动的兜底和恢复机制。
有一些感觉上还比较巧妙的方法,起到了四两拨千斤的效果。比如使用当前年份作为Redis Set中key的一部分,能够有效避免跨年的问题,并且不设置有效期,通过年定时任务来进行去年key的清理,也避免了年中上线有效期计算的问题。方法简洁且有效的解决了需求问题。另外就是与业务的沟通,可以接受一定的误差,不然Redis抖动的恢复机制又是一大麻烦点。判断重复后直接达标的方法,也避免修改了原先出账单文件的系统,可以说是完美的复用。同时还提高了对Redis集群的各种认知,包括容量评估,合适的数据结构选择,部署方式等等。以及加强了BDP HIVE大数据组件的使用,跑通了十亿级数据的迁移,高效且准确。
最后非常顺利的实现了账单模式的改变,稳定没有导致任何问题,交易几乎无感,业务很满意,自己也感觉提高很多。