VIT transformer详解
VIT transformer详解
- 一、前言
- 二、总体结构
- 三、VIT输入部分
- 四、VIT Encoder部分
- 五、CLS多分类输出
- 六、归纳偏置
- 七、参考
一、前言
论文:https://arxiv.org/abs/2010.11929
原文开源代码:GitHub - google-research/vision_transformer
Pytorch版本代码:https://github.com/lucidrains/vit-pytorch
虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNN的依赖是不必要的,直接应用于图像块序列 (sequences of image patches) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFAR-100、VTAB 等),与 SOTA 的 CNN 相比,Vision Transformer (ViT) 可获得更优异的结果,同时仅需更少的训练资源。
二、总体结构
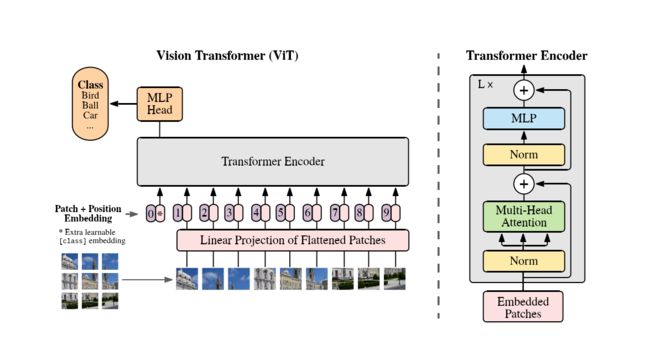
如图为整个ViT的架构,分为5个部分:
- 将图片切分为一个个的Token
- 将Token转化为Token Embedding
- 将Token Embedding 和 Position Embedding对应位置相加
- 输入到Transformer Encoder中
- Cls输出做多分类任务
三、VIT输入部分
-
图片切分为Token
比如一张224x224x3的图片,切分为16x16个token,每个token是14x14大小,得到16x16x3=768个token。 -
Token转换为Token Embedding
将一个16x16x3=768个Token拉直,拉到一个1维,长度为768的向量
接一个Linear层,把768映射到Transormer Encode规定的Embedding Size(1024)的长度 -
Token Embedding和Position Embedding对应位置相加
生成一个Cls对应的Token Embedding(对应图中的*部分)
生成所有序列的位置编码(包括Cls符号和和所有Token Embeding的位置编码 对应图中的0-9)
将Token Embedding和Position Embedding对应位置相加
notice:
问题1:为什么要加一个Cls的符号呢?
Cls是在Bert中的用到的一个符号,NLP任务中的Cls可以在一定程度上让bert的两个任务保持一定的独立性,而在ViT中只有一个多分类任务,所以Cls符号并不是必须的;而论文作者也做了实验证明了这点,在ViT的任务中,加Cls和不加Cls训练效果是差不多的.
在论文中,作者想要跟原始的Transformer尽可能地保持一致,所以也使用了class token,因为class token在NLP的分类任务中也有用到(也是当作一个全局的对句子的理解的特征),本文中的class token是将它当作一个图像的整体特征,拿到这个token的输出以后,就在后面接一个MLP(MLP中是用tanh当作非线性的激活函数来做分类的预测)
这个class token的设计是完全从NLP借鉴过来的,之前在视觉领域不是这么做的,比如说有一个残差网络Res50,在最后一个stage出来的是一个14×14的feature map,然后在这个feature map之上其实是做了一个叫做gap(global average pooling,全局平均池化)的操作,池化以后的特征其实就已经拉直了,就是一个向量了,这个时候就可以把这个向量理解成一个全局的图片特征,然后再拿这个特征去做分类。
对于Transformer来说,如果有一个Transformer模型,进去有n个元素,出来也有n个元素,为什么不能直接在n个输出上做全局平均池化得到一个最后的特征,而非要在前面加上一个class token,最后用class token的输出做分类?
通过实验,作者最后的结论是:这两种方式都可以,就是说可以通过全局平均池化得到一个全局特征然后去做分类,也可以用一个class token去做。本文所有的实验都是用class token去做的,主要的目的是跟原始的Transformer尽可能地保持一致(stay as close as possible),作者不想人觉得某些效果好可能是因为某些trick或者某些针对cv的改动而带来的,作者就是想证明,一个标准的Transformer照样可以做视觉。

问题2:为什么需要位置编码?
RNN在计算的时候是一个个的运算,具有一种天然时序关系,可以告诉模型哪些单词在前面,哪些单词在后面;但是在Transformer中它的单词是一起输入进去的,然后经过Attention层,那么如果没用位置编码,模型并不知道哪些单词在前面哪些单词在后面。所以,我们需要给模型一个位置信息,告诉模型,哪些词/哪个token在前面,哪些词/token在后面。
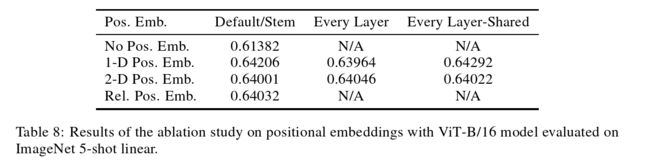
作者也做了很多的消融实验,主要是三种:
- 1d:就是NLP中常用的位置编码,也就是论文从头到尾都在使用的位置编码
- 2d:比如1d中是把一个图片打成九宫格,用的是1到9的数来表示图像块,2d就是使用11、12、13、21等来表示图像块,这样就跟视觉问题更加贴近,因为它有了整体的结构信息。具体的做法就是,原有的1d的位置编码的维度是d,现在因为横坐标、纵坐标都需要去表示,横坐标有D/2的维度,纵坐标也有D/2的维度,就是说分别有一个D/2的向量去表述横坐标和纵坐标,最后将这两个D/2的向量拼接到一起就又得到了一个长度为D的向量,把这个向量叫做2d的位置编码
- relative positional embedding(相对位置编码):在1d的位置编码中,两个patch之间的距离既可以用绝对的距离来表示,又可以用它们之间的相对距离来表示(文中所提到的offset),这样也可以认为是一种表示图像块之间位置信息的方式
但是这个消融实验最后的结果也是:三种表示方法的效果差不多,如下图所示:
四、VIT Encoder部分

Transformer和ViT中的Encoder部分的区别:
- 把Norm层提前了;
- 没用Pad符号;
五、CLS多分类输出
最终得到每一个token都会得到一个1024的输出,再把第一个(cls)1024的向量拿出来,接一个全连接层进行多分类。
六、归纳偏置
vision transformer相比于CNN而言要少很多图像特有的归纳偏置,比如在CNN中,locality(局部性)和translate equivariance(平移等变性)是在模型的每一层中都有体现的,这个先验知识相当于贯穿整个模型的始终
但是对于ViT来说,只有MLP layer是局部而且平移等变性的,但是自注意力层是全局的,这种图片的2d信息ViT基本上没怎么使用(就只有刚开始将图片切成patch的时候和加位置编码的时候用到了,除此之外,就再也没有用任何针对视觉问题的归纳偏置了)
而且位置编码其实也是刚开始随机初始化的,并没有携带任何2d的信息,所有关于图像块之间的距离信息、场景信息等,都需要从头开始学习
这里也是对后面的结果做了一个铺垫:vision transformer没有用太多的归纳偏置,所以说在中小数据集上做预训练的时候效果不如卷积神经网络是可以理解的
七、参考
https://blog.csdn.net/qq_38253797/article/details/126085344
https://blog.csdn.net/SeptemberH/article/details/123730336