基于RK3399+YOLO目标检测人工智能图像系统设计
随着 5G 通信技术的大范围普及,传统的目标检测系统已经不再能满足如今步入智
能化的各行各业的需求。消费者对以往依靠机器学习的传统目标检测系统提出了更高的
要求,相关的生产企业也开始向智能化和低功耗化过渡。其中如何将图像增强技术、目
标检测技术与神经网络相结合,移植到便携的嵌入式平台已经成为了如今开发人员研究
的热点。本课题设计了一种基于异构处理器的目标检测系统,可以针对一些目标物体密
集的特定环境下可以对目标物体进行高效准确地识别。
本文首先对目标检测系统的总体进行了设计,在硬件设计方面选用多核异构的 ARM
处理器 RK3399 作为核心处理器,图像采集模块选用了 CAM1320 模组,并且搭建外围
附属电路,完成硬件设计;软件部分对卷积神经网络进行了介绍。如今主流的目标检测
算法将图像的像素矩阵通过卷积和池化处理提取出特征信息,在全连接层对图像进行类
别预测。并对其中的典型代表算法 YOLOv3 中的网络结构、边界框和损失函数进行了分
析。通过对比 YOLOv3 和其他目标检测算法的性能指标,最终选择了 YOLOv3 作为本
文算法改进的基础。
之后对系统的目标检测的软件部分整体进行了阐述。首先介绍了基于 HSI 的图像增
强算法,对图像的特征信息和色彩信息分别做多尺度 Retinex 增强和色彩拉伸处理,将
增强后的图像作为目标检测算法的输入。然后针对 YOLOv3 在检测特定环境下所表现出
的目标漏检和检测分类集中现象,对 YOLOv3 算法做出了优化,一方面引入了 SE 单元
加强特征,另一方面将原先的三个尺度输出优化为针对密集环境的四尺度输出。
最后在目标检测系统平台的交叉编译调试环境进行搭建后,将优化后的神经网络模
型移植到嵌入式平台上,对目标检测系统平台进行测试,通过对图像的各项参数和目标
检测的准确率等指标分析,并得出实验结论,证明该目标检测系统可以有效增强图像,
其识别有效率达到 92.56% ,系统满足实际场景的高准确性需求。
针对系统目标检测硬件处理的需求,本论文设计了一种基于多核异构架构 ARM 的
嵌入式目标检测系统平台。系统原理框图如下:

为便于进行系统电路设计,可以根据系统的各个功能进行分部设计,可以划分为五
部分:采集模块,算法处理模块,存储模块,通信模块和显示模块。图像采集模块负责
采集外部视频流数据,将采集到的视频流数据接收到缓存区,之后由算法处理模块对视
频流数据进行读取;算法处理模块使用 RK3399 处理器完成对摄像头视频流的接收,将
数据缓存到外部存储模块 LPDDR4,之后由处理器进行图像增强处理、运行目标检测算

法、视频流编码压缩等一系列处理工作,将图像实时传输给显示模块,同时打包视频流
转送给传输模块;显示模块使用 HDMI 接口将处理后的数据流转化为视频信号,实时显
示到显示设备上。
2.2 主控处理器
片上系统 (System On Chip , SOC) 是广泛使用预定制模块而得以快速开发的集成电
路。 SOC 包含了微处理器、存储器以及其他专用功能逻辑,可以在较短时间设计出来,
缩短产品的上市周期,同时 SOC 可以降低因信号在多个芯片之间交互带来的延迟而导
致性能不佳,在满足低功耗的前提下保证了信号传输的稳定性。
本文设计的目标检测系统的中央处理器选用瑞芯微 28 纳米制程生产的基于
big.LITTLE 多核异构的旗舰级芯片 RK3399 处理器,可以采集图像、对图像进行增强
和运行目标检测算法。
信迈RK3399开发板
在图 2-2 所示的 信迈RK3399 硬件图中, RJ45 接口在本文设计的系统中用于连接网线进行图像传输、HDMI 接口用于连接屏幕进行显示、USB 插槽用于插入 U 盘保存文件、 其他空余 IO 口可以对系统功能进行扩展、MIPI 接口用于连接图像传感器进行视频采 集,通过串口和网口对系统进行实时调试。图 2-3 为 RK3399 的硬件资源图。

上述图中对 RK3399 的软件资源进行了介绍, RK3399 处理器内部集成有双核
Cortex − A72 + 四核 Cortex − A53 处理器,主频最高可达 2.4GHz 。同时内部配有 Mal
i-T860 高端 GPU ,集成了带宽压缩技术,利用了 OpenCL 、 RGA 等硬件加速模块,以
降低 CPU 负载,可搭载 AI 专用芯片 RK1808 提升运算效率,支持 TensorFlow / TF Li
te / Caffe / ONNX / Darknet 等模型,可达 3.0TOPs 。支持 4K 10bits H265/H264 视
频解码,帧率最高可达 60fps 。
采集模块设计
图像采集部分采用 CAM1320 模组作为视频图像的采集主体。 CAM1320 模组是采用
Omni Vision 公司研发的一款高性能 1300 万像素(
4224x3136 )传感器 OV13850 ,通过
MIPI 接口与 ARM 主板连接,可以支持同类最佳的高光和微光性能和多种图像控制功能,
同时 OV13850 还包括改进的全井容量 (FWC) 和行业领先的高光和微光性能的灵敏度。与
上一代传感器相比,其功耗降低了 40% ,使 OV13850 非常适合功能丰富的移动设备。
最高支持 13.2MP , 30fps 高清流畅录像,实现零快门延迟 [21] 。此外,该图像传感器最高
支持 60 帧 / 秒的高帧率 1080p 高清视频,具有 EIS ,可采集高质量视频,可以达到设计
的目标检测系统的要求。如图 2-8 为 OV13850 传感器的功能框图。
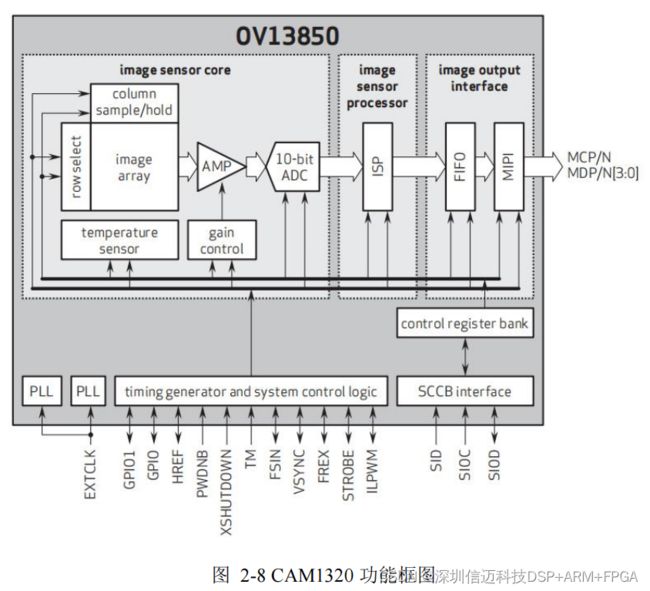
当 CPU 发出采集命。令时,图像采集模块开始采集视频图像。采集过程中,传感器
会将采集到的模拟信号经过自带的处理模块进行自动增益等处理,之后模拟信号会由


A/D 转换模块转换为数字信号,便于嵌入式平台进行处理,并由传感器自带的 FIFO 对
高速数据进行缓存,之后由处理器将 FIFO 中的数据读取到 DDR 中进行后续的图像算法
处理。
OV13850 图像传感器采用标准的 Serial Camera Control Bus (
SCCB )协议, SCCB 协 议与 I2C 协议极其相似,由时钟信号线 SIOC 和传输信号线 SIOD 组成,与 I2C 总线 不同的是 SCCB 一次传输 9 位数据,前 8 位为有用数据,第 9 位为无效位。其 OV13850 传感器的 RGB 输出时序如图 2-9 所示:
从图 2-9 中,可以看到 CAM1320 图像数据通过 D [9 : 2] 输出一个字节,前两个字节
形成 16 位 RGB565 数据。在时序图中,当 HREF 为高电平时,数据传输开始,一个 PCLK
传输一个字节,而当最后一个字节传输完成时, HREF 变为低电平。 HREF 周期由 640 tp
和 144 tp 组成。 1 个 t PCLK 发送 1 个字节。 480 个 HREF 周期组成一个帧,在 8t LINE 时
间后, VSYNC 将形成一个上升沿以表示图像传输帧的结束。
3 目标检测算法研究
本章的主要对基于卷积神经网络的典型检测算法代表 YOLOv3 进行了详细分析。与
传统目标检测算法相比,引入卷积神经网络可以使目标检测算法受环境因素的影响较
小,更适用于外界环境。同时将几种基于神经网络的目标检测算法进行性能对比,选择
最符合本课题需求的 YOLOv3 作为本课题系统改进优化的算法基础。
3.1 卷积神经网络相关知识简介
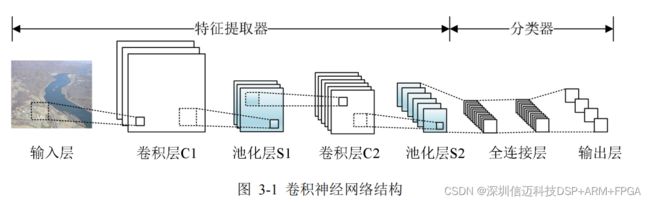
卷积神经网络( Convolutional Neural Network )在多层感知器的基础上增加了卷积
和池化对图像进行处理 [25] ,属于一种前馈神经网络。常见的卷积神经网络结构如图 3-1 ,
卷积神经网络通常包括特征提取器和分类器,其中特征提取器由三个部分组成:输入层
(即待检测图像对应像素矩阵)、卷积层和池化层;分类器包括全连接层和输出层。在
训练学习时,像素矩阵经过卷积和池化处理后提取出图像中物体的特征信息,全连接层
负责把各个物体的特征信息如颜色、轮廓等转化为一维特征向量。网络的最后一层即输
出层通过目标物体的预测值及损失函数计算出物体所属类别的概率,通过进行比较,将
概率最高的结果输出 [26] 。
3.2 YOLO 目标检测算法
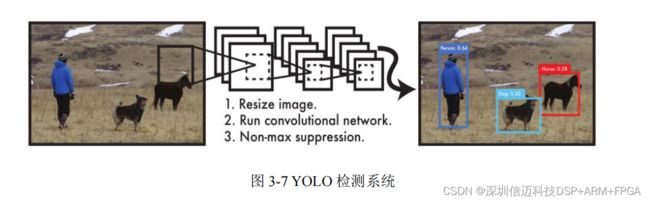
YOLO 是由 Joseph Redmon 在 Faster R-CNN 的基础上提出 [38] ,其创新点是在保持
较高检测精度的前提下实现了对整幅图片的实时检测。 YOLO 将目标检测问题转化为回
归问题 [39] ,通过使用神经网络对图像进行遍历,对图像中的目标物体进行预测并分类。
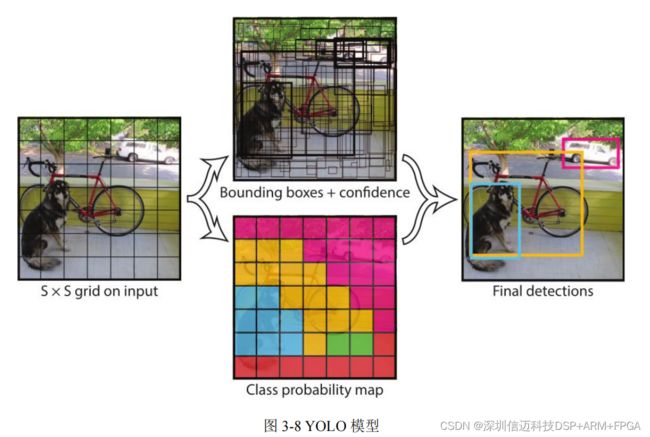
YOLO 算法首先将输入的图片重新调整为适合检测的尺寸,之后使用神经网络对图像进
行处理,将输入图片平均分为若干个网格,待识别物体的中心处于的网格负责对该物体
进行预测识别。
YOLO 为目标检测提供了一个新的解决思路,具有以下优点:
1 )速度快。将检测问题转换为回归问题,减少了计算量,检测速度可达 150FPS [42] 。
2 ) YOLO 在检测时对图片进行整体推理。与 Fast RCNN 不同, YOLO 可以在训练
和检测时提取检测图片的特征信息,包含特征信息和语义信息。 Fast RCNN 有时会把背
景误检测为目标物体 [43] 。 YOLO 的误检率比 Fast RCNN 至少低 50% 。
3 ) YOLO 识别算法拥有较强的鲁棒性。通过神经网络的不断训练学习,使算法对形
状、色彩较大差异的物体进行检测时,其准确率不会有明显的波动。
针对前两个版本 YOLO 存在的问题, YOLOv3 通过采用 Darknet-53 作为基础网络结
构 [44] ,通过不同的卷积层对图像进行降采样,舍弃原本的池化处理,有效减弱了池化处
理带来的梯度消失缺陷。同时 YOLOv3 将原先一层检测层扩展为 13x13 、 26x26 和 52x52
三个不同尺度的特征图,同时沿用了 K-means 聚类出的边界框,增加了边界框数量 [45] ,
根据其大小分别在三个特征图进行预测。
4 目标检测系统软件的原理与设计
通过在第三章介绍了卷积神经网络与目标检测算法 YOLOv3 的算法原理,本章针对
传统目标检测算法存在运行环境需求较高和无法用于复杂环境的缺陷,以 YOLOv3 为
改进基础,提出一种适用于嵌入式平台的目标检测模型。同时,本章对系统地软件部分
如数据集制作和图像增强处理进行了论述。
4.1 目标检测算法软件设计
目标检测系统的图像识别软件运行流程如图 4-1 所示。

最终得到的数据集文件如下所示。

JPEGImages 包含数据集所有的图像信息,包括训练图像和测试图像。 Annotations
中包含标签文件,每个标签文件对应于 JPEGImages 文件夹中的一个图像;
label.txt 用于 保存目标类别(背景类别除外)的文件;train_list.txt , test_list .txt 和 trainval.txt 存储学 习所需的图像和注释文件的相对路径; 这三个文件的区别在于它们包含不同的数据集。
train_list 约为全部数据集的 50 %, trainval 是整个数据集的其余 50 %; test_list 是训练
量的剩余 50 %。


其中, Windows 平台、 Linux 虚拟机 Ubuntu 与嵌入式开发平台通过路由器连接在同
一个局域网内,可以在 Windows 平台对代码进行编写和修改,虚拟机 Ubuntu 则可以将
编写好的代码交叉编译为能够在嵌入式系统中运行的文件,并且通过在虚拟机 Linux 系
统下完成对嵌入式平台运行所需的 Bootloader 、系统内核的裁剪和移植、根文件系统的
搭建以及对检测算法的移植和模型转换,最终通过交叉编译工具链将整体程序编译为可
执行文件。在调试过程中, Ubuntu 虚拟机可以通过串口打印嵌入式平台的系统运行信
息和调试信息,也可以通过局域网实时对系统中的文件进行操作。将 RK3399 目标检测
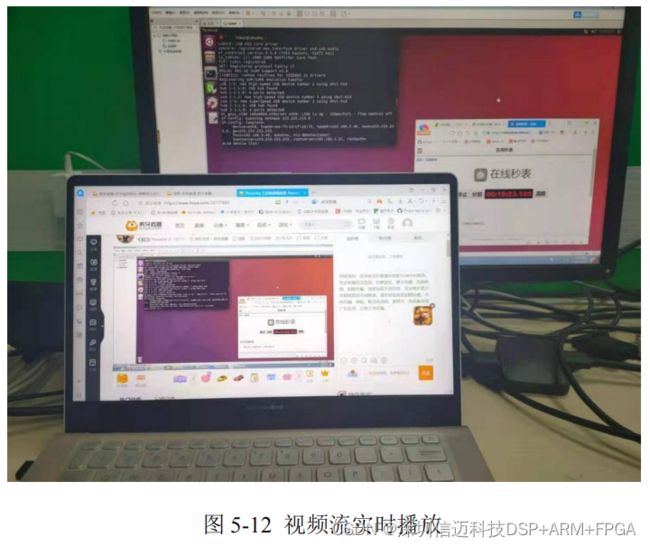
系统通过 HDMI 线与显示屏相连。系统连接如图 5-3 所示:



本章对目标检测系统的硬件平台和测试环境进行了搭建,包括在开发主机上搭建开
发环境以及 OpenCV 库和 TensorFlow 框架的搭建。本目标检测系统既实现了低功耗、
结构紧凑的特点,又留有足够的接口,可对系统进行进一步的优化。并且对图像增强算
法和目标检测算法的性能指标做出介绍,最后对系统的图像增强、目标检测和视频实时
推流功能进行了测试,对测试结果进行了多方面的分析。通过测试并分析可得出结论,
本系统在测试精确率方面优于传统目标检测算法,可以大范围在实际生活场景中运用。
信迈提供RK3399/3568+YOLO软硬件一体解决方案。