Googlev2Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
文章目录
- 批标准化:缓解内部协变量偏移加快深度神经网络训练
- GoogleNetv2全文翻译
- 论文结构
-
- 摘要
- 1 引言
- 2 减少内部协变量偏移(ICS)
- 3 通过小批量统计进行标准化
-
- 3.1 使用批量归一化网络进行训练和推理
- 指数滑动平均
- 3.2 批量归一化卷积网络
- 3.3 批量归一化可实现更高的学习率
- 奇异值分解SVD
- 3.4 批量归一化对模型进行正则化
- 4 实验
-
- 4.1 随着时间的推移激活
- 4.2 ImageNet 分类
-
- 4.2.1 加速BN网络
-
- 提高学习率
- 删除Dropout
- 减少 L2 权重正则化
- 加速学习率衰减
- 删除本地响应归一化
- 更彻底地打乱训练示例
- 减少光度畸变
- 相关知识
-
- 权重衰减
- L1和L2简要区别
- 4.2.2 单网络分类
- 4.2.3 集成分类
- 5 总结
- 附录
-
- GoogleNetv2和v1网络结构对比
- 论文研究背景、成果及意义
-
- ICS现象
- 白化(whitening)
- 研究成果
- 研究意义
- 论文图表
- 论文总结
- 论文代码复现准备工作
- BN层对神经网络神经元数据分布的影响
- BN层对神经网络初始化的影响
- BN层在训练与测试阶段的操作
批标准化:缓解内部协变量偏移加快深度神经网络训练

GoogleNetv2全文翻译

论文结构

摘要

训练深度神经网络很复杂,因为在训练过程中,随着前一层参数的变化,每层输入的分布也会发生变化。 由于需要较低的学习率和精心的参数初始化,这会减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。 我们将这种现象称为内部协变量偏移,并通过标准化层输入来解决该问题。 我们的方法的优势在于将归一化作为模型架构的一部分,并对每个训练小批量执行归一化。 批量归一化允许我们使用更高的学习率并且对初始化不那么小心。 它还充当正则化器,在某些情况下消除了 Dropout 的需要。 批量归一化应用于最先进的图像分类模型,以减少 14 倍的训练步骤实现相同的精度,并大幅优于原始模型。 使用批量归一化网络集合,我们改进了 ImageNet 分类的最佳已发表结果:达到 4.9% 的 top-5 验证误差(和 4.8% 的测试误差),超过了人类评分者的准确性。

1 引言

深度学习极大地提升了视觉、语音和许多其他领域的技术水平。 随机梯度下降(SGD)已被证明是训练深度网络的有效方法,并且 SGD 变体如动量(Sutskever 等人,2013)和 Adagrad(Duchi 等人,2011)已被用来达到最高水平性能。 SGD优化网络的参数θ,从而使损失最小化

其中 x 1... N x_{1...N} x1...N 是训练数据集。 使用 SGD,训练分步骤进行,每一步我们都会考虑大小为 m 的小批量 x 1... m x_{1...m} x1...m。 小批量用于近似损失函数相对于参数的梯度,通过计算


使用小批量示例(而不是一次使用一个示例)在很多方面都有帮助。 首先,小批量损失的梯度是训练集梯度的估计,其质量随着批量大小的增加而提高。 其次,由于现代计算平台提供的并行性,批量计算比单个示例的 m 次计算要高效得多。
虽然随机梯度简单有效,但它需要仔细调整模型超参数,特别是优化中使用的学习率以及模型参数的初始值。 由于每一层的输入都受到前面所有层的参数的影响,因此训练变得很复杂——因此,随着网络变得更深,网络参数的微小变化会放大。
层输入分布的变化带来了一个问题,因为层需要不断适应新的分布。 当学习系统的输入分布发生变化时,据说会经历协变量转变(Shimodaira,2000)。 这通常通过域适应来处理(Jiang,2008)。 然而,协变量偏移的概念可以扩展到整个学习系统之外,应用于其各个部分,例如子网络或层。 考虑网络计算

其中 F 1 F_1 F1和 F 2 F_2 F2是任意变换,并且需要学习参数 θ 1 θ_1 θ1、 θ 2 θ_2 θ2以最小化损失 ℓ ℓ ℓ 。 学习 θ 2 θ_2 θ2 可以被视为输入 x = F1(u, θ1) 被喂到子网络中

例如,梯度下降步骤

(对于批量大小 m 和学习率 α)与输入 x 的独立网络 F2 完全相同。 因此,使训练更加高效的输入分布属性(例如训练数据和测试数据之间具有相同的分布)也适用于训练子网络。 因此,x 的分布随着时间的推移保持固定是有利的。 那么,不需要重新调整 θ2 来补偿 x 分布的变化。

子网络输入的固定分布也会对子网络外部的层产生积极的影响。 考虑具有 sigmoid 激活函数 z = g ( W u + b ) z = g(Wu + b) z=g(Wu+b) 的层,其中 u 是层输入,权重矩阵 W 和偏置向量 b 是要学习的层参数,以及g(x) = 1 1 + e x p ( − x ) \frac{1}{1+exp(-x)} 1+exp(−x)1。 随着 ∣ x ∣ |x| ∣x∣ 增大, g ′ ( x ) g′(x) g′(x) 趋于零。 这意味着,对于 x = W u + b x = Wu+b x=Wu+b 的所有维度(除了绝对值较小的维度之外),流向 u 的梯度将消失,并且模型将缓慢训练。 然而,由于 x 受到 W、b 以及下面所有层的参数的影响,因此在训练期间更改这些参数可能会将 x 的许多维度移动到非线性的饱和状态并减慢收敛速度。 随着网络深度的增加,这种效应会被放大。 在实践中,饱和问题和由此产生的梯度消失通常通过使用修正线性单元来解决(Nair & Hinton, 2010)ReLU(x) = max(x, 0),精心初始化(Bengio & Glorot, 2010;Saxe 等人) ., 2013),并且学习率较小。 然而,如果我们能够确保非线性输入的分布在网络训练时保持更加稳定,那么优化器就不太可能陷入饱和状态,并且训练将加速
我们将训练过程中深度网络内部节点分布的变化称为内部协变量偏移。 消除它可以保证更快的训练。 我们提出了一种新的机制,我们称之为批量归一化,它朝着减少内部协变量偏移迈出了一步,从而显着加速了深度神经网络的训练。 它通过固定层输入的均值和方差的标准化步骤来实现这一点。 通过减少梯度对参数规模或其初始值的依赖性,批量归一化还对网络的梯度流产生有益的影响。 这使我们能够使用更高的学习率,而不会出现发散的风险。 此外,批量归一化可以正则化模型并减少 Dropout 的需要(Srivastava 等人,2014)。 最后,批量归一化可以使用饱和非线性防止网络陷入饱和模式来。
在第 4.2 节中,我们将批量归一化应用于性能最佳的 ImageNet 分类网络,并表明我们仅使用 7% 的训练步骤就可以匹配其性能,并且可以进一步大幅超过其准确性。 使用通过批量归一化训练的此类网络的集合,我们实现了top 5 error rate,该错误率提升 ImageNet 分类的最佳已知结果(即GoogleNetv1)。

2 减少内部协变量偏移(ICS)

我们将内部协变量偏移定义为由于训练期间网络参数的变化而导致的网络激活分布的变化。 为了改进训练,我们寻求减少内部协变量偏移。 通过随着训练的进行固定层输入 x 的分布,我们期望提高训练速度。 众所周知(LeCun 等人,1998b;Wiesler & Ney,2011)如果输入被白化,即线性变换为具有零均值和单位方差,并且去相关,则网络训练收敛得更快。 由于每一层都会观察下面层产生的输入,因此对每一层的输入实现相同的白化将是有利的。 通过白化每一层的输入,我们将朝着实现输入的固定分布迈出一步,从而消除内部协变量偏移的不良影响。

我们可以考虑在每个训练步骤或某个间隔对激活进行白化,方法是直接修改网络或根据网络激活值更改优化算法的参数(Wiesler 等人,2014 年;Raiko 等人,2012 年;Povey 等人,2014;Desjardins 和 Kavukcuoglu)。 然而,如果这些修改散布在优化步骤中,那么梯度下降步骤可能会尝试以需要更新归一化的方式来更新参数,这会降低梯度步骤的效果。 例如,考虑一个具有输入 u 的层,该层添加了学习偏差 b,并通过减去在训练数据上计算的激活平均值来标准化结果: x ^ = x − E [ x ] \hat{x} = x − E[x] x^=x−E[x] 其中 x = u + b x = u + b x=u+b, X = { x 1... N } X = \{x_{1...N} \} X={x1...N}是训练集上 x 值的集合,并且 E [ x ] = 1 N ∑ i = 1 N x i E[x] = \frac{1}{N}\sum_{i=1}^{N} x_i E[x]=N1∑i=1Nxi。如果梯度下降步骤忽略 E[x] 对 b 的依赖性,那么它将更新 b

符号“∝”表示成正比例。 一个物理量y随另一个物理量x的正比关系,可以表示为y∝x(读作“y正比于x”)
因此,b 的更新和随后的归一化变化相结合不会导致该层的输出发生变化,也不会导致损失。 随着训练的继续,b 将无限增长,而损失保持不变。 如果标准化不仅中心化而且还缩放激活,这个问题可能会变得更糟。 我们在最初的实验中凭经验观察到了这一点,当在梯度下降步骤之外计算归一化参数时,模型就会崩溃。
上述方法的问题在于梯度下降优化没有考虑到归一化发生的事实。 为了解决这个问题,我们希望确保对于任何参数值,网络始终产生具有所需分布的激活。 这样做将允许相对于模型参数损失的梯度考虑归一化及其对模型参数 θ 的依赖性。 再次让 x 为层输入,被视为向量,X 为训练数据集上这些输入的集合。 然后标准化可以写成一个变换
x ^ = N o r m ( x , X ) \hat{x} = Norm(x, X) x^=Norm(x,X)
这不仅取决于给定的训练示例 x,还取决于所有示例 X,如果 x 由另一层生成,则每个示例都取决于 θ。 对于反向传播,我们需要计算雅可比行列式 ∂ N o r m ( x , X ) ∂ x \frac{\partial Norm(x, X)}{\partial x} ∂x∂Norm(x,X) 和 ∂ N o r m ( x , X ) ∂ X \frac{\partial Norm(x, X)}{\partial X} ∂X∂Norm(x,X);
忽略后一项将导致上述爆炸。 在此框架内,白化层输入的成本很高,因为它需要计算协方差矩阵 C o v [ x ] = E x ∈ X [ x x T ] − E [ x ] E [ x ] T Cov[x] = E_{x\in{X}}[xx^\mathrm{T}] - E[x]E[x]^\mathrm{T} Cov[x]=Ex∈X[xxT]−E[x]E[x]T和其平方根倒数,去产生白化激活 C o v [ x ] − 1 / 2 ( x − E [ x ] ) Cov[x]^{-1/2}(x-E[x]) Cov[x]−1/2(x−E[x]),以及这些变换的导数用于反向传播。 这促使我们寻求一种替代方案,以可微分的方式执行输入标准化,并且不需要在每次参数更新后分析整个训练集。

之前的一些方法(例如(Lyu & Simoncelli,2008))使用在单个训练示例上计算的统计数据,或者在图像网络的情况下,在给定位置的不同特征图上计算的统计数据。 然而,这通过丢弃激活的绝对规模来改变网络的表示能力。 我们希望通过相对于整个训练数据的统计数据标准化训练示例中的激活来保留网络中的信息。
3 通过小批量统计进行标准化

由于每层输入的完全白化成本高昂,而且并非处处可微,因此我们进行了两项必要的简化。 第一个是,我们不是联合白化层输入和输出中的特征,而是独立地标准化每个标量特征,使其均值为零,方差为 1。对于具有 d 维输入 x = ( x ( 1 ) . . . x ( d ) ) x = (x^{ (1) }. . . x^{(d)}) x=(x(1)...x(d)),我们将标准化每个维度

其中期望和方差是在训练数据集上计算的。 如(LeCun 等人,1998b)所示,即使特征没有去相关,这种归一化也能加速收敛。

k=3表示有三个特征

请注意,简单地规范化层的每个输入可能会改变该层可以表示的内容。 例如,标准化 sigmoid 的输入会将它们限制为非线性的线性状态。 为了解决这个问题,我们确保插入网络中的变换可以代表恒等变换。 为了实现这一点,我们为每个激活 x ( k ) x^{(k)} x(k) 引入一对参数 γ ( k ) 、 β ( k ) γ^{(k)}、β^{(k)} γ(k)、β(k),用于缩放和移动归一化值:

这些参数与原始模型参数一起学习,并恢复网络的表示能力。 事实上,通过设置 γ ( k ) = V a r [ x ( k ) ] γ^{(k)} = \sqrt{Var[x^{(k)}]} γ(k)=Var[x(k)] 和 β ( k ) = E [ x ( k ) ] β^{(k)} = E[x^{(k)}] β(k)=E[x(k)],我们可以恢复原始激活,如果这是最佳做法的话。


在批处理设置中,每个训练步骤都基于整个训练集,我们将使用整个训练集来标准化激活。 然而,当使用随机优化时,这是不切实际的。 因此,我们进行第二次简化:由于我们在随机梯度训练中使用小批量,因此每个小批量都会生成每个激活的均值和方差的估计。 这样,用于归一化的统计量就可以充分参与梯度反向传播。 请注意,小批量的使用是通过计算每维方差而不是联合协方差来实现的; 在联合情况下,需要进行正则化,因为小批量大小可能小于白化激活的数量,从而导致奇异协方差矩阵。
考虑大小为 m 的小批量 B。 由于归一化独立地应用于每个激活,因此为了清楚起见,让我们关注特定的激活 x ( k ) x^{(k)} x(k) 并省略 k。 我们在小批量中拥有此激活的 m 个值
B = { x 1... m } B = \{x_{1...m}\} B={x1...m}
令归一化值为 x ^ 1... m \hat{x} _{1...m} x^1...m,其线性变换为 y 1... m y_{1...m} y1...m。 我们参考变换

作为批量归一化变换。 我们在算法 1 中提出了 BN 变换。在该算法中,ε 是为了数值稳定性而添加到小批量方差中的常数。

算法 1:批量归一化变换,应用于小批量上的激活 x。

BN 变换可以添加到网络中以操纵任何激活。 在符号 y = B N γ , β ( x ) y = BN_{γ,β(x)} y=BNγ,β(x) 中,我们表明要学习参数 γ 和 β,但应该注意的是 BN 变换并不独立处理每个训练示例中的激活。相反, B N γ , β ( x ) BN_{γ,β(x)} BNγ,β(x) 取决于训练示例和小批量中的其他示例。 缩放和移动的值 y 被传递到其他网络层。 归一化激活 x ^ \hat{x} x^ 是我们转换的内部因素,但它们的存在至关重要。只要每个小批量的元素是从同一分布中采样的,并且如果我们忽略 ε,则任何 x ^ \hat{x} x^ 值的分布的期望值为 0,方差为 1。 这可以通过观察 ∑ i = 1 m x i ^ = 0 \sum_{i=1}^{m} \hat{x_i}=0 ∑i=1mxi^=0 和 1 m ∑ i = 1 m x i 2 ^ = 1 \frac{1}{m}\sum_{i=1}^{m} \hat{x_i^2}= 1 m1∑i=1mxi2^=1 并取期望来看出。 每个归一化激活 x ^ ( k ) \hat{x}^{(k)} x^(k) 都可以视为由线性变换 y ( k ) = γ ( k ) x ^ ( k ) + β ( k ) y^{(k)}= γ^{(k)}\hat{x}^{(k)} + β^{(k)} y(k)=γ(k)x^(k)+β(k)组成的子网络的输入,然后由原始网络完成其他处理。 这些子网络输入都具有固定的均值和方差,尽管这些归一化 x ^ ( k ) \hat{x}^{(k)} x^(k)的联合分布可以在训练过程中发生变化,但我们期望归一化输入的引入会加速子网络的训练,并且, 因此,网络作为一个整体。

在训练过程中,我们需要通过该变换反向传播损失 ℓ ℓ ℓ 的梯度,并计算相对于 BN 变换参数的梯度。 我们使用链式法则,如下(简化之前):

因此,BN 变换是一种可微变换,它将归一化激活引入到网络中。 这确保了模型在训练时,各层可以继续学习内部协变量变化较小的输入分布,从而加速训练。 此外,应用于这些归一化激活的学习仿射变换允许 BN 变换来表示恒等变换并保留网络容量。
3.1 使用批量归一化网络进行训练和推理

为了对网络进行批量标准化,我们指定一个激活子集,并根据 Alg1 为每个激活子集插入 BN 变换。 之前接收 x 作为输入的任何层现在都接收 BN(x)。 采用批量归一化的模型可以使用批量梯度下降或小批量大小 m > 1 的随机梯度下降或其任何变体(例如 Adagrad)进行训练(Duchi 等人,2011)。 依赖于小批量的激活标准化可以实现高效的训练,但在推理过程中既不必要也不可取; 我们希望输出确定性地仅依赖于输入。 为此,一旦网络经过训练,我们就使用归一化


使用总体统计而不是小批量统计。 忽略 ε,这些归一化激活与训练期间具有相同的均值 0 和方差 1。 我们使用无偏方差估计 V a r [ x ] = m m − 1 ⋅ E B [ σ B 2 ] Var[x] = \frac{m}{m-1}\cdot E_B[σ^2_B] Var[x]=m−1m⋅EB[σB2],其中期望超过训练大小为 m 的小批量, σ B 2 σ^2_B σB2 是它们的样本方差。 使用移动平均值,我们可以跟踪模型训练时的准确性。 由于均值和方差在推理过程中是固定的,因此归一化只是应用于每个激活的线性变换。 它可以进一步由 γ 缩放和 β 移位组成,以产生替代 BN(x) 的单个线性变换。 算法 2 总结了训练批量归一化网络的过程。


指数滑动平均

decay是小于1的数




3.2 批量归一化卷积网络

批量归一化可以应用于网络中的任何激活集。 在这里,我们关注由仿射变换和逐元素非线性组成的变换:
z = g ( W u + b ) z = g(Wu + b) z=g(Wu+b)
其中W和b是模型的学习参数, g ( ⋅ ) g(·) g(⋅)是非线性激活函数,例如sigmoid或ReLU。 该公式涵盖了全连接层和卷积层。 我们通过归一化 x = W u + b x = Wu+ b x=Wu+b,在非线性之前添加 BN 变换。 我们还可以对层输入 u 进行归一化,但由于 u 可能是另一个非线性的输出,因此其分布的形状在训练期间可能会发生变化,并且约束其一阶矩和二阶矩不会消除协变量偏移。 相比之下, W u + b Wu + b Wu+b 更有可能具有对称的、非稀疏的分布,即“更多高斯分布”(Hyvarinen & Oja,2000); 对其进行标准化可能会产生具有稳定分布的激活。

请注意,由于我们对 W u + b Wu+b Wu+b 进行了归一化,因此可以忽略偏差 b,因为其影响将被随后的均值减法所抵消(偏差的作用被算法 1 中的 β 所包含)。 因此, z = g ( W u + b ) z = g(Wu + b) z=g(Wu+b) 被替换为 z = g ( B N ( W u ) ) z = g(BN(Wu)) z=g(BN(Wu))

其中 BN 变换独立应用于 x = W u x = Wu x=Wu 的每个维度,每个维度都有一对单独的学习参数 γ ( k ) 、 β ( k ) γ^{(k)}、β^{(k)} γ(k)、β(k)。
对于卷积层,我们还希望标准化遵循卷积属性——以便同一特征图的不同元素在不同位置以相同的方式标准化。 为了实现这一目标,我们在所有位置联合标准化小批量中的所有激活。 在算法1,我们让 B 是跨小批量元素和空间位置的特征图中所有值的集合,因此对于大小为 m 的小批量和大小为 p × q p × q p×q 的特征图,我们使用大小为 m ′ = ∣ B ∣ = m ⋅ p q m^′ = |B| = m \cdot pq m′=∣B∣=m⋅pq 的有效小批量 。 我们为每个特征图而不是每个激活学习一对参数 γ ( k ) 和 β ( k ) γ^{(k)} 和 β^{(k)} γ(k)和β(k)。 算法2 也进行了类似的修改,以便在推理过程中 BN 变换对给定特征图中的每个激活应用相同的线性变换。

3.3 批量归一化可实现更高的学习率

在传统的深度网络中,过高的学习率可能会导致梯度爆炸或消失,以及陷入不良的局部最小值。 批量归一化有助于解决这些问题。 通过对整个网络的激活进行标准化,它可以防止参数的微小变化放大为梯度激活中较大的和次优的变化; 例如,它可以防止训练陷入非线性饱和状态。
批量归一化还使训练对参数规模更具弹性。 通常,大的学习率可能会增加层参数的规模,从而放大反向传播过程中的梯度并导致模型爆炸。 然而,通过批量归一化,通过层的反向传播不受其参数规模的影响。 事实上,对于标量 a,
B N ( W u ) = B N ( ( a W ) u ) BN(Wu) = BN((aW)u) BN(Wu)=BN((aW)u)
我们可以证明

尺度不会影响雅可比行列式,因此也不影响梯度传播。 此外,较大的权重会导致较小的梯度,而 Batch Normalization 将稳定参数的增长。

我们进一步推测批量归一化可能会导致雅可比行列式的奇异值接近 1,这对训练是有利的(Saxe et al., 2013)。 考虑具有归一化输入的两个连续层,以及这些归一化向量之间的变换: z ^ = F ( x ^ ) \hat{z} = F(\hat{x}) z^=F(x^)。 如果我们假设 x ^ \hat{x} x^ 和 z ^ \hat{z} z^ 是高斯分布且不相关,并且 F ( x ^ ) ≈ J x ^ F(\hat{x}) \approx J\hat{x} F(x^)≈Jx^ 是给定模型参数的线性变换,则 x ^ \hat{x} x^ 和 z ^ \hat{z} z^ 都具有单位协方差,并且 I = C o v [ z ^ ] = J C o v [ x ^ ] J T = J J T I = Cov[\hat{z}] = JCov[\hat{x}]J^\mathrm{T} = JJ^\mathrm{T} I=Cov[z^]=JCov[x^]JT=JJT。 因此, J J T = I JJ^\mathrm{T} = I JJT=I,因此 J 的所有奇异值都等于 1,这在反向传播期间保留了梯度幅度。 实际上,变换不是线性的,并且归一化值不能保证是高斯分布或独立的,但我们仍然期望批量归一化有助于使梯度传播表现更好。 批量归一化对梯度传播的精确影响仍然是进一步研究的领域

奇异值分解SVD



3.4 批量归一化对模型进行正则化

当使用批量归一化进行训练时,训练示例与小批量中的其他示例一起出现,并且训练网络不再为给定的训练示例生成确定性值。 在我们的实验中,我们发现这种效应有利于网络的泛化。 尽管 Dropout(Srivastava 等人,2014)通常用于减少过度拟合,但在批量归一化网络中,我们发现它可以被删除或降低强度。



4 实验
4.1 随着时间的推移激活


为了验证内部协变量偏移对训练的影响以及批量归一化对抗它的能力,我们考虑了在 MNIST 数据集上预测数字类别的问题(LeCun 等人,1998a)。 我们使用了一个非常简单的网络,以 28x28 的二值图像作为输入,以及 3 个全连接的隐藏层,每个隐藏层有 100 次激活。 每个隐藏层使用 sigmoid 非线性计算 y = g ( W u + b ) y = g(Wu+b) y=g(Wu+b),并且权重 W 初始化为小的随机高斯值。 最后一个隐藏层后面是一个全连接层,具有 10 个激活(每个类一个)和交叉熵损失。 我们对网络进行了 50000 个步骤的训练,每个小批量有 60 个示例。 我们将批量归一化添加到网络的每个隐藏层,如第 3.1 节中所示。我们感兴趣的是基线网络和批量归一化网络之间的比较,而不是在 MNIST 上实现最先进的性能(所描述的架构没有实现)。

图 1(a) 显示了随着训练的进行,两个网络对保留测试数据的正确预测的比例。 批量归一化网络具有更高的测试精度。 为了探究原因,我们在训练过程中研究了原始网络 N 和批量归一化网络 N B N t r N^{tr}_{BN} NBNtr(算法 2)中 sigmoid 的输入。 在图 1(b,c) 中,我们展示了每个网络最后一个隐藏层的一个典型激活,其分布如何演变。 原始网络中的分布随着时间的推移,其均值和方差都会发生显着变化,这使得后续层的训练变得复杂。 相比之下,随着训练的进行,批量归一化网络中的分布更加稳定,这有助于训练。

图 1:(a) 使用和不使用批量归一化训练的 MNIST 网络的测试准确性与训练步骤数的关系。 批量归一化有助于网络更快地训练并实现更高的准确性。 (b,c) 在训练过程中输入分布向典型 sigmoid 的演变,显示为第 {15, 50, 85} 个百分位数。 批量归一化使分布更加稳定并减少内部协变量偏移。

4.2 ImageNet 分类

我们将批量归一化应用于 Inception 网络的新变体(Szegedy 等人,2014),并在 ImageNet 分类任务上进行训练(Russakovsky 等人,2014)。 该网络有大量的卷积层和池化层,并有一个 softmax 层来预测图像类别,从 1000 种可能性中预测。 卷积层使用 ReLU 作为非线性。 与(Szegedy et al., 2014)中描述的网络的主要区别在于,5 × 5 卷积层被两个连续的 3 × 3 卷积层(最多 128 个滤波器)取代。 该网络包含 13.6 ⋅ 106 13.6 \cdot 106 13.6⋅106 个参数,并且除了顶部的 softmax 层之外,没有全连接层。 附录中给出了更多详细信息。 在本文的其余部分中,我们将此模型称为 Inception。 该模型使用带有动量的随机梯度下降版本(Sutskever 等人,2013)进行训练,使用的小批量大小为 32。训练是使用大规模分布式架构(类似于(Dean 等人) .,2012))。 随着训练的进展,所有网络都通过计算验证精度 @1 进行评估,即在保留集上,使用每个图像的单个裁剪,从 1000 种可能性中预测正确标签的概率。


在我们的实验中,我们评估了批标准化对 Inception 的几种修改。 在所有情况下,批量归一化都以卷积方式应用于每个非线性的输入,如第 3.2 节所述,同时保持架构的其余部分不变。
4.2.1 加速BN网络

简单地将批量归一化添加到网络中并不能充分利用我们的方法。 为此,我们进一步更改了网络及其训练参数,如下:
提高学习率
在批量归一化模型中,我们已经能够通过更高的学习率实现训练加速,并且没有不良副作用(第 3.3 节)。
删除Dropout
如第 3.4 节所述。Batch Normalization 实现了一些与 Dropout 相同的目标。 从修改的 BN-Inception 中删除 Dropout 可加快训练速度,而不会增加过度拟合。
减少 L2 权重正则化
在 Inception 中,模型参数上的 L2 损失控制了过度拟合,而在 Modified BN-Inception 中,该损失的权重减少了 5 倍。我们发现这提高了保留验证数据的准确性。
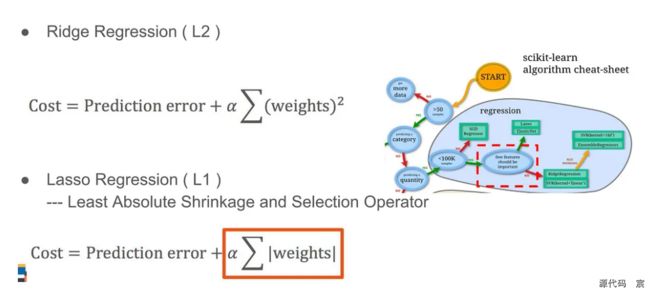
L2值越小,这里是0.2倍,就能让权重尺度更大一些。权重很大,容易让神经元的值也很大,落入饱和区,但是有BN,可以把它们从饱和区拉回非饱和区
加速学习率衰减
在训练 Inception 时,学习率呈指数衰减。 因为我们的网络训练速度比 Inception 快,所以我们将学习率降低了 6 倍。
删除本地响应归一化
虽然 Inception 和其他网络(Srivastava 等人,2014)从中受益,但我们发现用批量归一化,那LRN是不必要的
更彻底地打乱训练示例
我们启用了训练数据的分片内混洗,这可以防止相同的示例始终一起出现在小批量中。 这导致验证准确性提高了约 1%,这与批量归一化作为正则化器的观点一致(第 3.4 节):可以看到当我们的方法中固有的随机化每次对示例的影响不同时,它应该是最有益的。
减少光度畸变
由于批量归一化网络训练速度更快,并且观察每个训练示例的次数更少,因此我们让训练者通过减少扭曲来专注于更“真实”的图像。
相关知识
权重衰减


L1和L2简要区别
4.2.2 单网络分类

我们评估了以下网络,所有网络均在 LSVRC2012 训练数据上进行训练,并在验证数据上进行测试:
Inception:4.2 节开头描述的网络,以 0.0015 的初始学习率进行训练。
BN-Baseline:与 Inception 相同,在每个非线性之前进行批量归一化
BN-x5:批量归一化的Inception以及第 4.2.1 节中的修改。初始学习率增加了 5 倍,达到 0.0075。 与原始 Inception 相同的学习率增加导致模型参数达到机器无穷大。
BN-x30:与BN-x5类似,但初始学习率为0.045(Inception的30倍)
BN-x5-Sigmoid:与 BN-x5 类似,但使用 sigmoid 非线性 g ( t ) = 1 1 + e x p ( − x ) g(t) = \frac{1}{1+exp(−x)} g(t)=1+exp(−x)1 而不是 ReLU。 我们还尝试用 sigmoid 训练原始的 Inception,但模型的准确度仍然与机会相当。
在图 2 中,我们显示了网络的验证准确性,作为训练步骤数的函数。 经过 31 ⋅ 1 0 6 31\cdot10^6 31⋅106 个训练步骤后,Inception 的准确率达到了 72.2%。 图 3 显示了每个网络达到相同 72.2% 准确度所需的训练步骤数,以及网络达到的最大验证准确度和达到该准确度的步骤数。
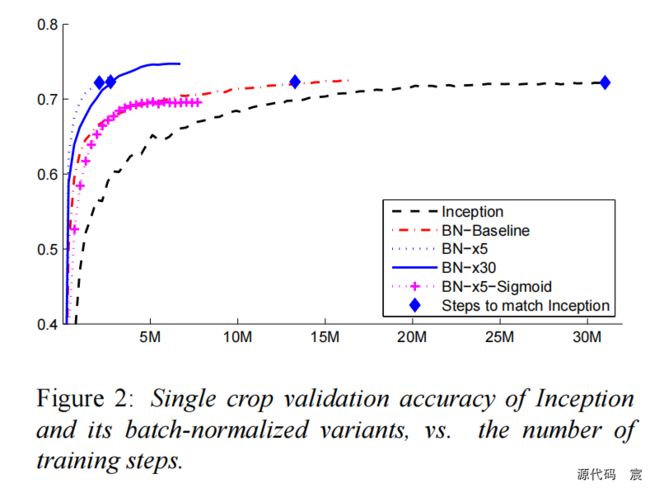
图 2:Inception 及其批量归一化变体的Single crop验证准确性与训练步骤数的关系。

图 3:对于 Inception 和批量归一化变体,达到 Inception 最大准确度 (72.2%) 所需的训练步骤数,以及网络达到的最大准确度。
通过仅使用批量归一化(BN-Baseline),我们可以用不到一半的训练步骤来匹配 Inception 的准确性。 通过应用第 4.2.1 节中的修改,我们显着提高了网络的训练速度。 BN-x5 需要比 Inception 少 14 倍的步骤就能达到 72.2% 的准确率。 有趣的是,进一步提高学习率 (BN-x30) 会导致模型最初训练速度稍慢,但可以达到更高的最终精度。 经过 6 ⋅ 1 0 6 6\cdot10^6 6⋅106 个步骤后,它达到了 74.8%,即比 Inception 达到 72.2% 所需的步骤少了 5 倍。
我们还验证了,当使用 sigmoid 作为非线性时,内部协变量偏移的减少允许训练具有批量归一化的深度网络,尽管训练此类网络存在众所周知的困难。 事实上,BN-x5-Sigmoid 的准确率达到了 69.8%。 如果没有批量归一化,使用 sigmoid 的 Inception 永远无法达到高于 1/1000 的精度。


4.2.3 集成分类

目前在 ImageNet 大规模视觉识别竞赛中报告的最佳结果是由传统模型的深度图像集成(Wu et al., 2015)和集成模型(He et al., 2015)获得的。 根据 ILSVRC 服务器的评估,后者报告的 top-5 error为 4.94%。 在这里,我们报告的 top-5 验证错误为 4.9%,测试错误为 4.82%(根据 ILSVRC 服务器)。 这改进了之前的最佳结果,并且超过了人类评估者根据(Russakovsky 等人,2014)估计的准确性。
对于我们的集成,我们使用了 6 个网络。 每个都基于 BN-x30,并通过以下一些修改:增加了卷积层中的初始权重; 使用 Dropout(Dropout 概率为 5% 或 10%,而原始 Inception 的 Dropout 概率为 40%); 并对模型的最后隐藏层使用非卷积、每次激活批量归一化。 每个网络在大约 6 ⋅ 1 0 6 6\cdot10^6 6⋅106 个训练步骤后达到了最大准确度。 整体预测基于组成网络预测的类别概率的算术平均值。 集成和多裁剪推理的细节类似于(Szegedy et al., 2014)。
我们在图 4 中证明,批量归一化使我们能够在 ImageNet 分类挑战基准上以健康的幅度设定新的最先进技术。

图 4:在所提供的包含 50000 张图像的验证集上,批量归一化 Inception 与先前先进技术水平的比较。 *根据测试服务器的报告,BN-Inception ensemble 在 ImageNet 测试集的 100000 张图像上达到了 4.82% 的 top-5 error

5 总结

我们提出了一种显着加速深度网络训练的新颖机制。 它基于这样一个前提:协变量移位(已知会使机器学习系统的训练变得复杂)也适用于子网络和层,并且将其从网络的内部激活中删除可能有助于训练。 我们提出的方法从标准化激活中汲取力量,并将这种标准化纳入网络架构本身。 这确保了用于训练网络的任何优化方法都能正确处理归一化。 为了启用深度网络训练中常用的随机优化方法,我们对每个小批量进行归一化,并通过归一化参数反向传播梯度。 批量归一化每次激活仅添加两个额外参数,这样做保留了网络的表示能力。 我们提出了一种使用批量归一化网络构建、训练和执行推理的算法。 由此产生的网络可以用饱和非线性进行训练,更能容忍增加的训练率,并且通常不需要 Dropout 进行正则化。
仅仅将批量归一化添加到最先进的图像分类模型中就可以显着提高训练速度。 通过进一步提高学习率、消除 Dropout 并应用批归一化提供的其他修改,我们仅用一小部分训练步骤就达到了之前的最先进水平,然后在单网络图像分类中击败了最先进技术 。 此外,通过结合使用 Batch Normalization 训练的多个模型,我们的表现比 ImageNet 上最知名的系统要好很多。
有趣的是,我们的方法与(Gülc¸ehre & Bengio,2013)的标准化层相似,尽管这两种方法源于非常不同的目标,并执行不同的任务。 批量归一化的目标是在整个训练过程中实现激活值的稳定分布,在我们的实验中,我们在非线性之前应用它,因为这是匹配一阶矩和二阶矩更有可能产生稳定的分布。 相反,(Gülc¸ehre & Bengio,2013)将标准化层应用于非线性的输出,这会导致更稀疏的激活。 在我们的大规模图像分类实验中,无论有没有批归一化,我们都没有观察到非线性输入是稀疏的。 批量归一化的其他显着差异化特征包括允许 BN 变换表示身份的学习尺度和移位(标准化层不需要这一点,因为它后面跟着学习的线性变换,从概念上讲,吸收了必要的尺度和移位), 卷积层的处理、不依赖于小批量的确定性推理以及对网络中每个卷积层进行批量归一化。
在这项工作中,我们尚未探索批量标准化可能实现的全部可能性。 我们未来的工作包括将我们的方法应用于循环神经网络(Pascanu et al., 2013),其中内部协变量偏移和梯度消失或爆炸可能特别严重,这将使我们能够更彻底地检验归一化的假设,改进梯度传播(第 3.3 节)。 我们计划研究批量归一化是否有助于传统意义上的领域适应,即网络执行的归一化是否可以使其更轻松地推广到新的数据分布,也许只需重新计算总体均值和方差( 算法 2)。 最后,我们相信对该算法的进一步理论分析将带来更多的改进和应用。
附录

图 5 记录了与 GoogleNet 架构相比所执行的更改。 对于该表的解释,请查阅(Szegedy et al., 2014)。 与 GoogLeNet 模型相比,显着的架构变化包括:
- 5×5 卷积层被两个连续的 3×3 卷积层替代。 这将网络的最大深度增加了 9 个权重层。 同时参数数量增加了25%,计算成本增加了约30%。
- 28×28 inception 模块数量从2增加到3
- 在模块内部,有时采用平均池化,有时采用最大池化。 这在与表的池化层相对应的条目中指示。
- 任何两个 Inception 模块之间没有全面的池化层,但在模块 3c、4e 中的过滤器串联之前采用了 stride-2 卷积/池化层。
我们的模型在第一个卷积层上采用深度乘数为 8 的可分离卷积。 这降低了计算成本,同时增加了训练时的内存消耗。

图 5:Inception 架构

GoogleNetv2和v1网络结构对比

论文研究背景、成果及意义




ICS现象


白化(whitening)
白化指的是对数据预处理,再输入模型之前对数据进行操作;BN是在模型当中对这些网络层输出的神经元的值在输入到激活函数,把这些数据进行一系列处理

将一组数据的每一个数据都加上或减去同一个数,方差和标准差都不变,都乘以或除以同一个数,方差就扩大或缩小这个数的平方倍,标准差就扩大或缩小多少倍.
研究成果

研究意义

论文图表










论文总结







论文代码复现准备工作



BN层对神经网络神经元数据分布的影响






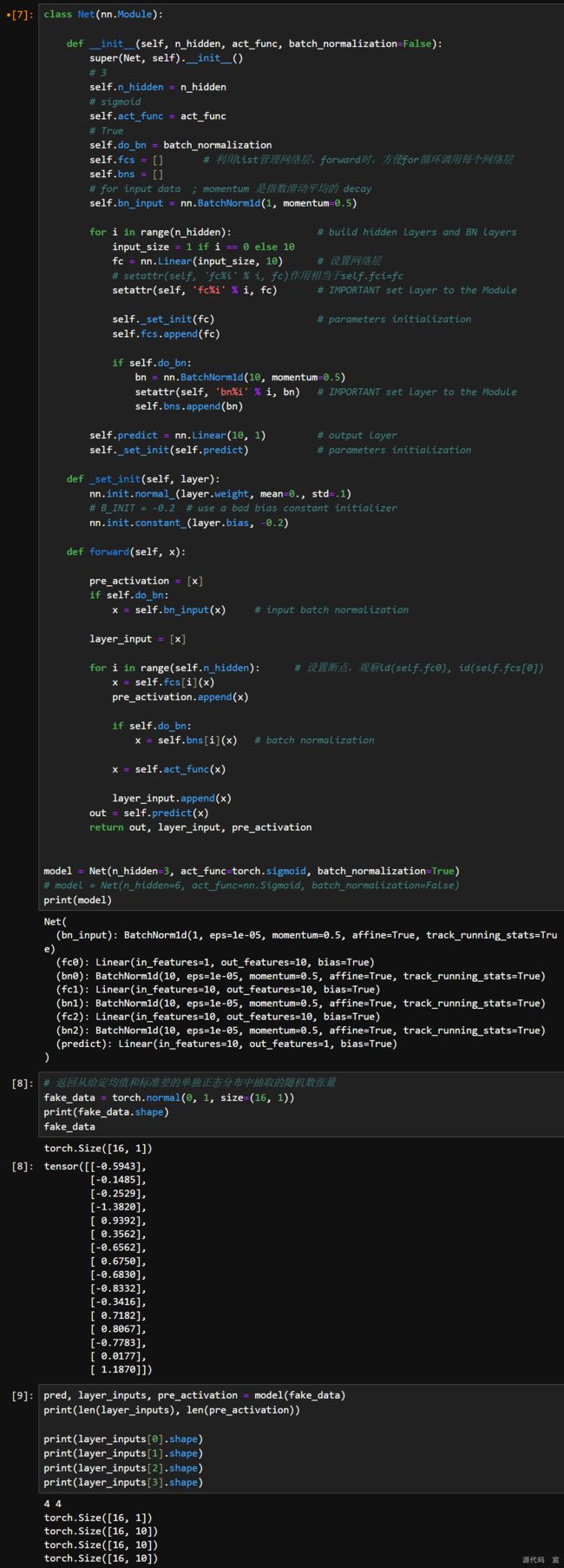
BN_FC.py
# -*- coding: utf-8 -*-
"""
# @file name : BN_visual.py
# @author : TingsongYu https://github.com/TingsongYu,代码来自莫烦:
https://morvanzhou.github.io/tutorials/machine-learning/torch/5-04-batch-normalization/
# @brief : BN层对数据分布对影响
"""
import torch
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from tools.common_tools import generate_data, Net
# 设置随机种子,便于复现
torch.manual_seed(1) # reproducible
np.random.seed(1)
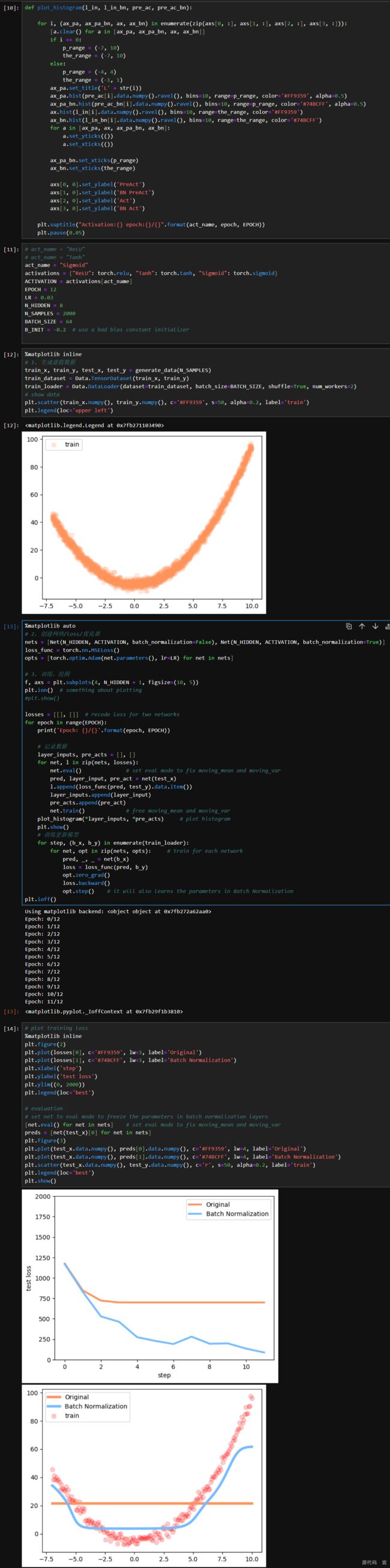
def plot_histogram(l_in, l_in_bn, pre_ac, pre_ac_bn):
for i, (ax_pa, ax_pa_bn, ax, ax_bn) in enumerate(zip(axs[0, :], axs[1, :], axs[2, :], axs[3, :])):
[a.clear() for a in [ax_pa, ax_pa_bn, ax, ax_bn]]
if i == 0:
p_range = (-7, 10)
the_range = (-7, 10)
else:
p_range = (-4, 4)
the_range = (-1, 1)
ax_pa.set_title('L' + str(i))
ax_pa.hist(pre_ac[i].data.numpy().ravel(), bins=10, range=p_range, color='#FF9359', alpha=0.5)
ax_pa_bn.hist(pre_ac_bn[i].data.numpy().ravel(), bins=10, range=p_range, color='#74BCFF', alpha=0.5)
ax.hist(l_in[i].data.numpy().ravel(), bins=10, range=the_range, color='#FF9359')
ax_bn.hist(l_in_bn[i].data.numpy().ravel(), bins=10, range=the_range, color='#74BCFF')
for a in [ax_pa, ax, ax_pa_bn, ax_bn]:
a.set_yticks(())
a.set_xticks(())
ax_pa_bn.set_xticks(p_range)
ax_bn.set_xticks(the_range)
axs[0, 0].set_ylabel('PreAct')
axs[1, 0].set_ylabel('BN PreAct')
axs[2, 0].set_ylabel('Act')
axs[3, 0].set_ylabel('BN Act')
plt.suptitle("Activation:{} epoch:{}/{}".format(act_name, epoch, EPOCH))
plt.pause(0.05)
# plt.savefig("{}.png".format(epoch))
if __name__ == "__main__":
act_name = "ReLU"
# act_name = "Tanh"
# act_name = "Sigmoid"
activations = {"ReLU": torch.relu, "Tanh": torch.tanh, "Sigmoid": torch.sigmoid}
ACTIVATION = activations[act_name]
EPOCH = 12
LR = 0.03
N_HIDDEN = 8
N_SAMPLES = 2000
BATCH_SIZE = 64
B_INIT = -0.2 # use a bad bias constant initializer
# 1. 生成虚假数据
train_x, train_y, test_x, test_y = generate_data(N_SAMPLES)
train_dataset = Data.TensorDataset(train_x, train_y)
train_loader = Data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
# show data
plt.scatter(train_x.numpy(), train_y.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
plt.legend(loc='upper left')
# 2. 创建网络/loss/优化器
nets = [Net(N_HIDDEN, ACTIVATION, batch_normalization=False), Net(N_HIDDEN, ACTIVATION, batch_normalization=True)]
loss_func = torch.nn.MSELoss()
opts = [torch.optim.Adam(net.parameters(), lr=LR) for net in nets]
# 3. 训练,绘图
f, axs = plt.subplots(4, N_HIDDEN + 1, figsize=(10, 5))
plt.ion() # something about plotting
plt.show()
losses = [[], []] # recode loss for two networks
for epoch in range(EPOCH):
print('Epoch: {}/{}'.format(epoch, EPOCH))
# 记录数据
layer_inputs, pre_acts = [], []
for net, l in zip(nets, losses):
net.eval() # set eval mode to fix moving_mean and moving_var
pred, layer_input, pre_act = net(test_x)
l.append(loss_func(pred, test_y).data.item())
layer_inputs.append(layer_input)
pre_acts.append(pre_act)
net.train() # free moving_mean and moving_var
plot_histogram(*layer_inputs, *pre_acts) # plot histogram
# 训练更新模型
for step, (b_x, b_y) in enumerate(train_loader):
for net, opt in zip(nets, opts): # train for each network
pred, _, _ = net(b_x)
loss = loss_func(pred, b_y)
opt.zero_grad()
loss.backward()
opt.step() # it will also learns the parameters in Batch Normalization
plt.ioff()
# plot training loss
plt.figure(2)
plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
plt.xlabel('step')
plt.ylabel('test loss')
plt.ylim((0, 2000))
plt.legend(loc='best')
# evaluation
# set net to eval mode to freeze the parameters in batch normalization layers
[net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
preds = [net(test_x)[0] for net in nets]
plt.figure(3)
plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
plt.legend(loc='best')
plt.show()
common_tools.py
# -*- coding: utf-8 -*-
import numpy as np
import torch
import torch.nn as nn
import os
import random
from PIL import Image
from torch.utils.data import Dataset
import torchvision.models as models
def get_googlenet(path_state_dict, device, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.googlenet(init_weights=False)
if path_state_dict:
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
def generate_data(num_samples):
# training data
x = np.linspace(-7, 10, num_samples)[:, np.newaxis]
noise = np.random.normal(0, 2, x.shape)
y = np.square(x) - 5 + noise
# test data
test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
noise = np.random.normal(0, 2, test_x.shape)
test_y = np.square(test_x) - 5 + noise
# to tensor
train_x, train_y = torch.from_numpy(x).float(), torch.from_numpy(y).float()
test_x = torch.from_numpy(test_x).float()
test_y = torch.from_numpy(test_y).float()
return train_x, train_y, test_x, test_y
class Net(nn.Module):
def __init__(self, n_hidden, act_func, batch_normalization=False):
super(Net, self).__init__()
self.do_bn = batch_normalization
self.fcs = [] # 利用list管理网络层,forward时,方便for循环调用每个网络层
self.bns = []
self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # for input data
self.act_func = act_func
self.n_hidden = n_hidden
for i in range(n_hidden): # build hidden layers and BN layers
input_size = 1 if i == 0 else 10
fc = nn.Linear(input_size, 10) # 设置网络层
setattr(self, 'fc%i' % i, fc) # IMPORTANT set layer to the Module
self._set_init(fc) # parameters initialization
self.fcs.append(fc)
if self.do_bn:
bn = nn.BatchNorm1d(10, momentum=0.5)
setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
self.bns.append(bn)
self.predict = nn.Linear(10, 1) # output layer
self._set_init(self.predict) # parameters initialization
def _set_init(self, layer):
nn.init.normal_(layer.weight, mean=0., std=.1)
nn.init.constant_(layer.bias, -0.2) # B_INIT = -0.2 # use a bad bias constant initializer
def forward(self, x):
pre_activation = [x]
if self.do_bn:
x = self.bn_input(x) # input batch normalization
layer_input = [x]
for i in range(self.n_hidden): # 设置断点,观察id(self.fc0), id(self.fcs[0])
x = self.fcs[i](x)
pre_activation.append(x)
if self.do_bn:
x = self.bns[i](x) # batch normalization
x = self.act_func(x)
layer_input.append(x)
out = self.predict(x)
return out, layer_input, pre_activation
BN层对神经网络初始化的影响
BN层在训练与测试阶段的操作
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!