Pytorch2
Day2
Python对应pytorch数据类型
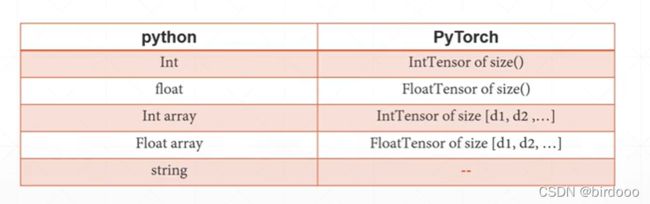
例如表示3,则IntTensor(3) ,dimension为0
表示一个矩阵,则dimension为2
string例如‘hello’,没有对应的,因为pytorch是处理数值的
所以用pytorch处理string类型时,用数字编码表示
One-hot
例如
[1,0]表示dog
[0,1]表示cat
但是两个单词的相关性无法在one-hot中显示,比如I like和I don’t like
A的ASCII码为0x34

数据类型
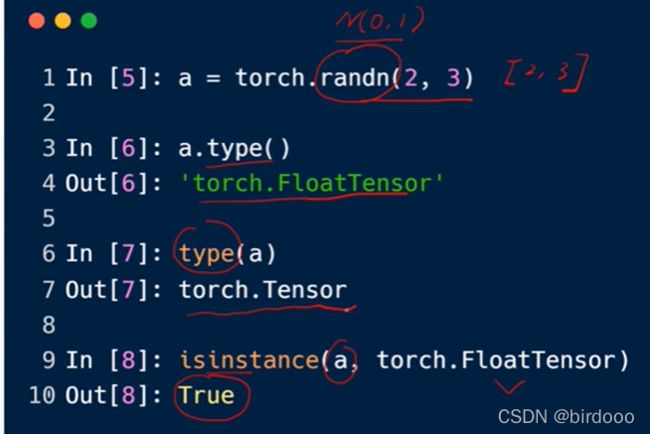
randn(2,3)随机初始化一个2行3列的tensor,均值0,方差为1
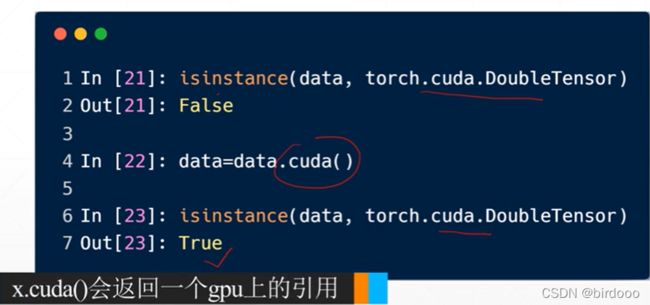
isinstance可以用作参数的检验
.X.cuda()会返回一个gpu上的引用,在gpu中数据类型需要多加.cuda
Pytorch中维度(Dimension)概念的理解
标量,Dimension为0
例如python中1.0,2.2
pytorch中即torch.tensor(2.2)

例如:神经网络中损失函数loss是dimension为0的标量
size和shape在pytorh中都表示tensor的类型
标量的形状
a.shape
a.dim()
a.size()

【例】
| #导入torch import torch #创建一个维度为0的tensor a = torch.tensor(1.) print(a)#输出a print(a.size())#表示tensor的类型,size和shape在pytorh中都表示tensor的类型 print(a.shape) print(len(a.shape)) 输出: tensor(1.) torch.Size([]) torch.Size([]) 0 |
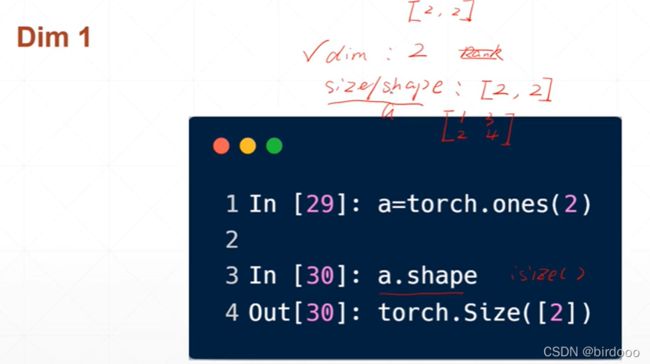
dimension为1的tensor,数学中叫向量,在pytorch称为张量
维度为1的tensor,与维度为0的张量创建时相比,仅仅只多了一个[ ]
.tensor接受的是数据的内容,.tensor([1.1,2.2]) 具体的数据
.FloatTensor接受的是数据的shape,.FloatTensor(2),给定向量的长度为2,则会随机初始化两个向量
dimension为1的tensor一般用在Bias(偏置),是一个dimension为1的tensor
或神经网络中线性层的输入
例如一张图片[28,28]可以用[784]即dimension为1的tensor送到神经网络中

如何得到dimension为1的shape
2行2列,即dimension为2
【例】
| #导入torch import torch #创建一个维度为1的tensor a = torch.tensor([1.1]) print(a)#输出a print(a.shape)#输出形状 print(len(a.shape)) |
| 输出: tensor([1.1000])#python中默认为浮点数类型 torch.Size([1])#中括号里边的1,即代表1维 1 |
dimension为2的tensor
使用随机正态分布生成2行3列的tensor,torch.randn(2,3)
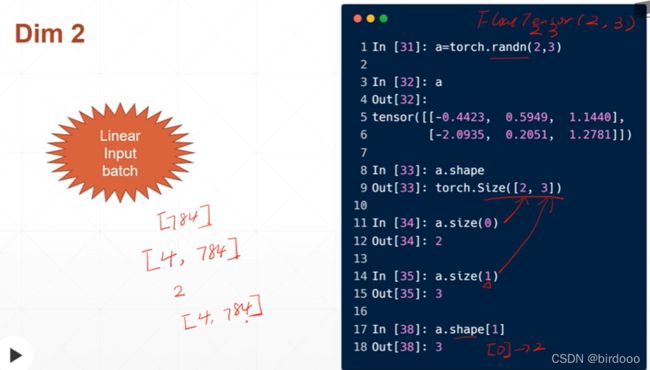
dimension为2的tensor经常使用:带有batch的Linear的输入
例如4张图片,每张图片用784的维度来表示
[4,784]
4表示哪一张照片,第0,1,2,3张照片
784表示照片的具体的数据内容
【例】
| #导入torch import torch #创建一个维度为2的tensor b = torch.randn(2,3)#randn是正态分布,即创建一个2行3列的矩阵,矩阵内元素符合均值为0方差为1的分布 print(b)#输出b print(b.size())#输出tensor的类型 print(len(b.shape)) |
| tensor([[-0.6245, -0.9659, 0.8636], [-0.9493, 0.6241, -1.5067]]) torch.Size([2, 3])#tensor类型为2行3列的矩阵 2 |
那么我们如何来理解这个二维的tensor呢?实际上,这个二维的tensor就是一个二维矩阵,2维即可理解为矩阵的行和列,行即维度为0,列即维度为1。我们再来看一下:
| print(b.shape[0]) print(b.shape[1]) |
| 2 3 |
显示,我们可以更加直观的看出,2维的tensor,其索引为0和1,0代表其行数,1代表其列数。在大致了解了二维的tensor后,我们再来理解一下他的物理意义:
一个带有batch的线性层输入,即加入一个图片的宽和高为[25,25],打平后为[625],
则[2,625]即表示2张图片一块输入,每个图片的大小是625
dimension为3的tensor
rand随机均匀分布,torch.rand(1,2,3)

dimension为3较多的使用场景RNN,适合文字处理,对于一个RNN,一句话有10个单词,一个单词我们用一个one-hot编码
每个feature用100维向量表示即[10,100]
[10,20,100],10表示10个单词,20表示一次送20个句子,100表示一次用100维的向量表示一个单词
【例】
| #导入torch import torch #创建一个维度为3的tensor c = torch.rand(3,2,3) print(c) print(c.shape) |
| tensor([[[0.0932, 0.7748, 0.1215], [0.6337, 0.3522, 0.1062]], [[0.5779, 0.6993, 0.0230], [0.9226, 0.5299, 0.1861]], [[0.0227, 0.3016, 0.9368], [0.7684, 0.7787, 0.6171]]]) torch.Size([3, 2, 3]) |
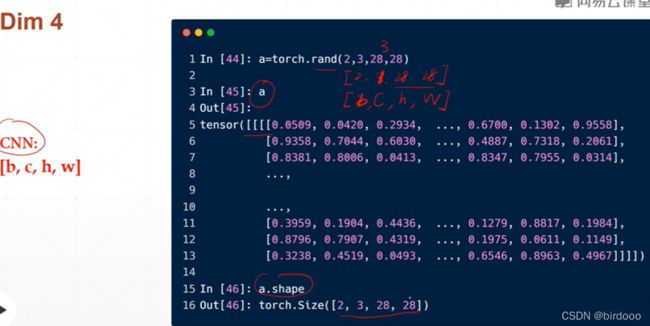
dimension为4的tensor
适合图片这种类型维度为4的tensor,最常见的情况就是在卷积神经网络 中,[batch,channel,height,width]。
【例】
| #导入torch import torch #创建一个维度为4的tensor c = torch.rand(2,3,25,25) """ 上边创建的四维tensor ,各参数的物理意义可理解为;2表示进行处理的图片batch,这里为两张; 3表示的是该图片为彩色图片,channel数量为RGB3通道,25*25表示图片的长和宽。 """ print(c) print(c.shape) print(c.numel() )#numel函数,及number element。即逐元素相乘。 print(c.dim())#求tensor的维度为多少 |
| tensor([[[[0.0885, 0.7384, 0.6371, ..., 0.3208, 0.0581, 0.7142], [0.8130, 0.0404, 0.7012, ..., 0.6019, 0.1015, 0.9588], [0.4855, 0.6130, 0.1593, ..., 0.1474, 0.3851, 0.5320], ..., [0.1728, 0.4715, 0.3917, ..., 0.9605, 0.8233, 0.8145], [0.6379, 0.7163, 0.2047, ..., 0.2210, 0.8876, 0.7437], [0.2638, 0.3275, 0.7637, ..., 0.5851, 0.0522, 0.8435]], [[0.4587, 0.2620, 0.5742, ..., 0.1823, 0.1100, 0.7643], [0.8904, 0.8908, 0.1480, ..., 0.3918, 0.3410, 0.7371], [0.6350, 0.4235, 0.4947, ..., 0.1291, 0.7077, 0.4199], ..., [0.9750, 0.9149, 0.0253, ..., 0.7849, 0.9863, 0.4276], [0.4117, 0.9636, 0.2074, ..., 0.5924, 0.8397, 0.5174], [0.6355, 0.9376, 0.6325, ..., 0.5065, 0.9398, 0.4591]], [[0.7319, 0.3808, 0.3656, ..., 0.6158, 0.8127, 0.5377], [0.7817, 0.5277, 0.9428, ..., 0.0032, 0.7543, 0.2630], [0.3526, 0.2539, 0.6907, ..., 0.7403, 0.6150, 0.8632], ..., [0.9896, 0.2491, 0.9341, ..., 0.5563, 0.1472, 0.7592], [0.5110, 0.8409, 0.2105, ..., 0.9475, 0.0620, 0.6796], [0.6519, 0.9809, 0.7917, ..., 0.7317, 0.0315, 0.7892]]], [[[0.2208, 0.9637, 0.9443, ..., 0.4771, 0.5033, 0.2917], [0.1701, 0.8320, 0.3640, ..., 0.5074, 0.6219, 0.1707], [0.4048, 0.1494, 0.9358, ..., 0.8532, 0.2298, 0.0691], ..., [0.2787, 0.3809, 0.9087, ..., 0.4491, 0.4912, 0.4132], [0.1516, 0.4484, 0.4718, ..., 0.9796, 0.8061, 0.4744], [0.6960, 0.5026, 0.5266, ..., 0.7811, 0.4093, 0.5238]], [[0.3725, 0.7506, 0.8075, ..., 0.9897, 0.6699, 0.3276], [0.3139, 0.5054, 0.3133, ..., 0.3512, 0.1084, 0.8433], [0.8386, 0.3877, 0.1941, ..., 0.0903, 0.6257, 0.2474], ..., [0.0579, 0.4931, 0.8824, ..., 0.1812, 0.8336, 0.0030], [0.2589, 0.3976, 0.6554, ..., 0.1437, 0.4533, 0.0758], [0.2885, 0.1804, 0.6388, ..., 0.4709, 0.2782, 0.8804]], [[0.4836, 0.3040, 0.6066, ..., 0.6594, 0.3668, 0.4089], [0.4970, 0.8915, 0.5742, ..., 0.5544, 0.2297, 0.8319], [0.8399, 0.8372, 0.8259, ..., 0.8524, 0.0242, 0.1726], ..., [0.1040, 0.3566, 0.1785, ..., 0.4557, 0.4020, 0.7327], [0.0273, 0.0586, 0.4000, ..., 0.8475, 0.2587, 0.6252], [0.1678, 0.0942, 0.1210, ..., 0.1048, 0.4521, 0.5950]]]]) torch.Size([2, 3, 25, 25]) 3750#这里即为2*3*25*25 4 |
Mixed
numerl是指tensor占用内存的数量
number element
2*3*28*28 = 4704

创建Tensor
1)从numpy导入
先创建一个dimension为1,长度为2的向量
从numpy导入的Float其实是Double类型
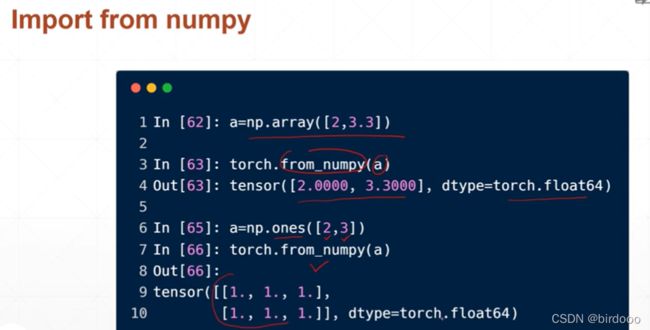
2)从List导入
torch.tensor():接受现有的数据
torch.Tensor():接受数据的维度,也可以接受现有数据(必须用list表示)
torch.FloatTensor(2,3):即生成一个2行3列(shape为(2,3))的tensor
#尽量使用
torch.FloatTensor(d1,d2,d3) 表示shape
或
torch.tensor([2. ,3.2])
少使用torch.FloatTenor([2. ,3.2]) 这种形式,容易引起混淆

Tensor是多维矩阵,矩阵的元素都是同一种数据类型。
tensor需要确切的数据对它进行赋值。
Tensor主要是创建多维矩阵的,标量从某种意义上,不算矩阵。所以Tensor可以通过赋值多维矩阵的方式创建,但是无法指定标量值进行创建。如果想创建单个值,采用[5.6] 这种形式,指定一行一列的矩阵。
同时,Tensor可以指定多维矩阵形状的大小,并且默认的数据类型是FloatTensor。
tensor主要是根据确定的数据值进行创建,无法直接指定形状大小,需要根据数据的大小进行创建。但同时,tensor没有赋值数据值是矩阵的限制,可以直接使用tensor(5.6)
张量(Tensor)
几何代数中定义的张量是基于向量和矩阵的推广,通俗一点来理解,我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量。

张量
在PyTorch中,张量Tensor是最基础的运算单位,与NumPy中的NDArray类似,张量表示的是一个多维矩阵。不同的是,PyTorch中的Tensor可以运行在GPU上,而NumPy的NDArray只能运行在CPU上。由于Tensor能在GPU上运行,因此大大加快了运算速度。
可以通过rand( )函数生成一个简单的张量,例如生成一个2行3列0-1的随机数Tensor。
torch.rand(2, 3)
通过shape属性或使用size( )函数可以查看Tensor的大小。

查看Tensor大小
在同构的意义下,我们设r为张量的秩或阶,那么,第零阶张量(r = 0)为标量,第一阶张量(r = 1)为向量,第二阶张量(r = 2)为矩阵,第三阶以上(r > 2)的统称为多维张量。
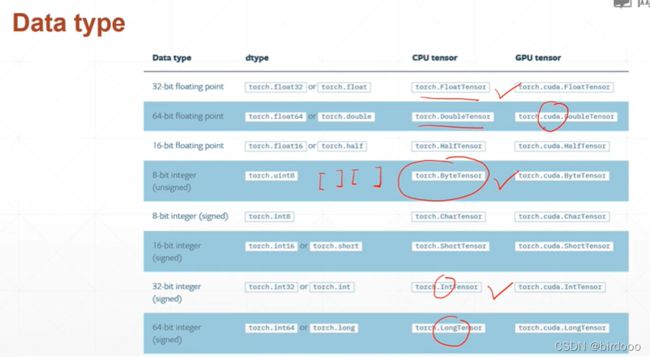
Tensor基本数据类型
Tensor的常用基本数据类型主要有以下五种:
1.32位浮点型:torch.FloatTensor。Tensor的默认数据类型。
2.64位浮点型:torch.DoubleTensor。
3.64位整型:torch.LongTensor。
4.32位整型:torch.IntTensor。
5.16位整:torch.ShortTensor。

Tensor初始化
除了使用rand( )函数外,PyTorch中还提供了许多初始化张量的方法,可以类比NumPy中对NDArray的初始化。
randn( ):初始化一个均值为0,方差为1的随机数Tensor。
ones( ):初始化一个全为1的Tensor。
zeros( ):初始化一个全为0的Tensor。
eye( ):初始化一个主对角线为1,其余都为0的Tensor(只能是二阶,即矩阵)。

Tensor和tensor的区别
在PyTorch中,Tensor和tensor都能用于生成新的张量:
首先,我们需要明确一下,torch.Tensor()是python类,更明确地说,是默认张量类型torch.FloatTensor()的别名,torch.Tensor([1,2])会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。
| >>> a=torch.Tensor([1,2]) >>> a.type() 'torch.FloatTensor' |
而torch.tensor()仅仅是python函数
函数原型是:
| torch.tensor(data, dtype=None, device=None, requires_grad=False) |
其中data可以是:list, tuple, NumPy ndarray, scalar和其他类型。
torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor、torch.FloatTensor和torch.DoubleTensor。
| >>> a=torch.tensor([1,2]) >>> a.type() 'torch.LongTensor' |
| >>> a=torch.tensor([1.,2.]) >>> a.type() 'torch.FloatTensor' |
| >>> a=np.zeros(2,dtype=np.float64) >>> a=torch.tensor(a) >>> a.type() 'torch.DoubleTensor' |
empty()创建任意数据类型的张量,torch.tensor()只创建torch.FloatTensor类型的张量。
empty()返回一个包含未初始化数据的张量。使用参数可以指定张量的形状、输出张量、数据类型这意味着你可以创建一个浮点张量,int
如果未指定数据类型,则所选数据类型是默认的torch.Tensor类型
由于torch.Tensor()只能指定数据类型为torch.float,所以torch.Tensor()可以看做torch.empty()的一个特殊情况。
PyTorch的Tensor与NumPy的NDArray转换
Tensor转NDArray
使用PyTorch的numpy( )函数将Tensor转换为NDArray。

NDArray转Tensor
使用PyTorch的from_numpy( )函数将NDArray转换为Tensor。

随机初始化
rand(通过0,1的均值分布)会随机产生0-1之间的数值,不包括1
randint需要指定最大最小值randint(min,max,shape)

正态分布
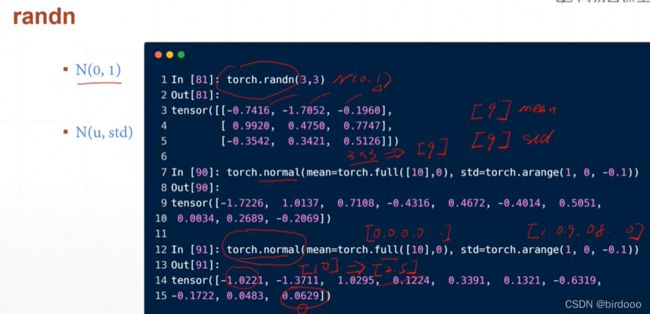
arange是不包含有边界的,也就是[1.09,...0.1]
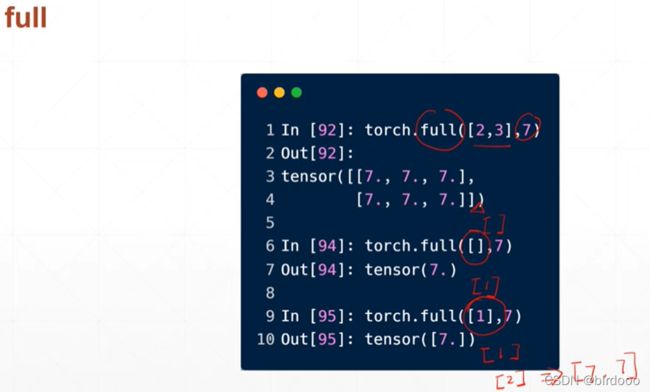
想全部赋值为一个数
数据类型默认floatTensor
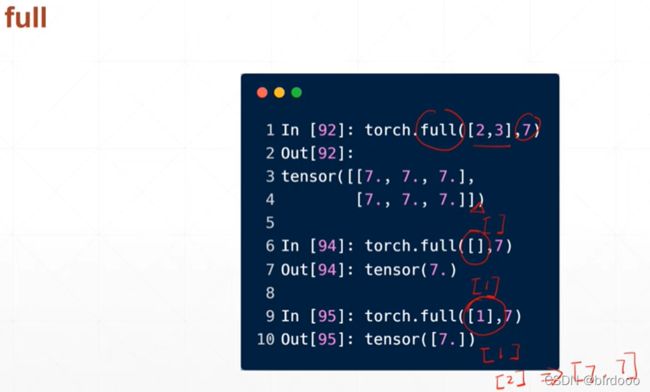
logspace的base参数可以设置为2,10,e等底数
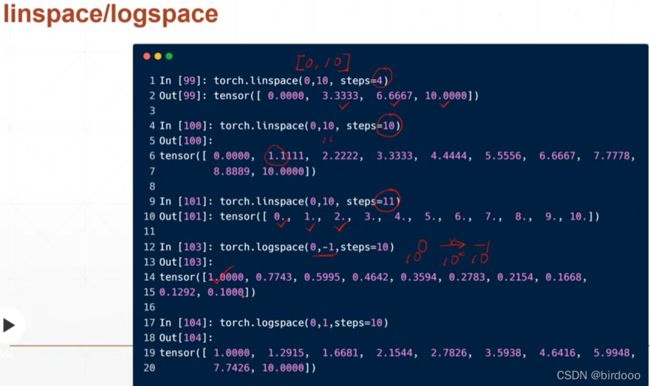
生成0-10的随机索引,然后可以random.shuffle打乱数据
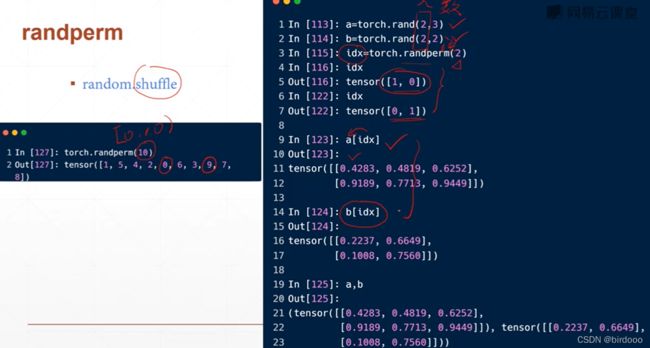
索引与切片
以dimension=4为例
从最左边开始索引

例:取前两张或后两张图片,连续选取
a[:2]取0,1张图片
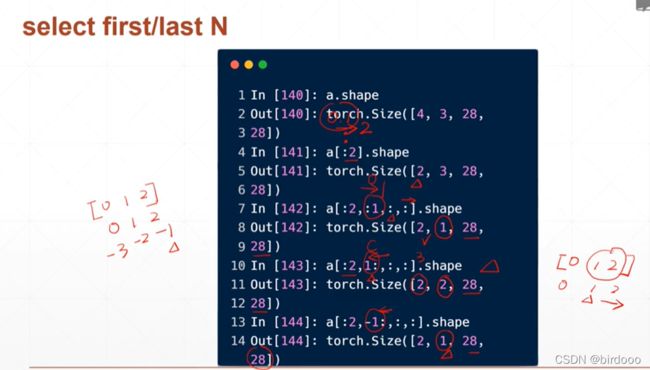
不连续选取


当有...出现时,右边的索引需要理解为最右边
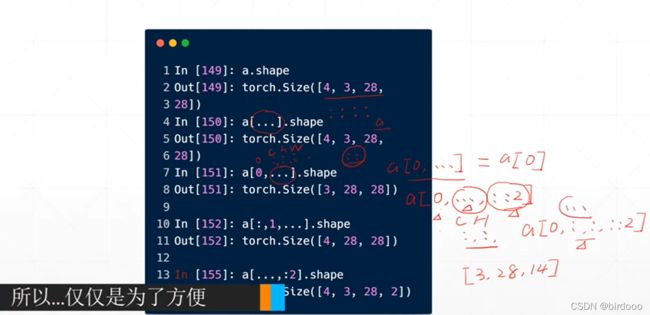


Tensor维度变化
api:
View/reshape 转变shape
Squeeze/unsqueeze 删减/增加维度
Transpose/t/permute 维度转置(单次/多次)
Expand/repeat 低维度转高纬度
数据的存储/维度顺序非常重要,需要时刻记住
例如本来[b,c,H,W]即第几张图片,频道(色彩),宽高
原来:[4,1,28,28]
之后恢复为了[4,28,28,1],这样就造成了数据的损坏
因此恢复数据时,要按照原来维度的顺序

view还原时,和原来的size不一样也会报错,原来是[4,784]
因此[4,783]报错

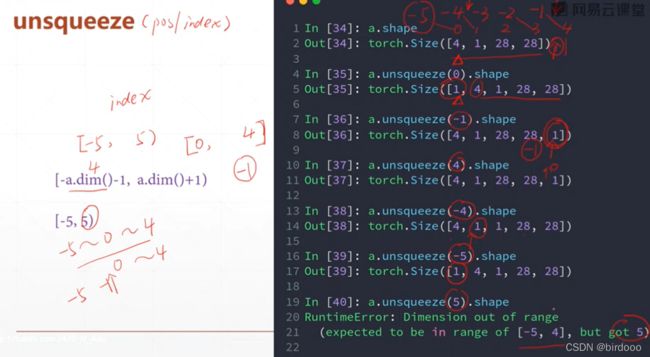
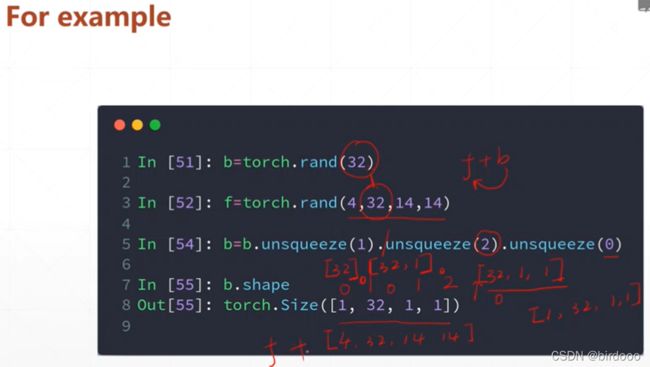
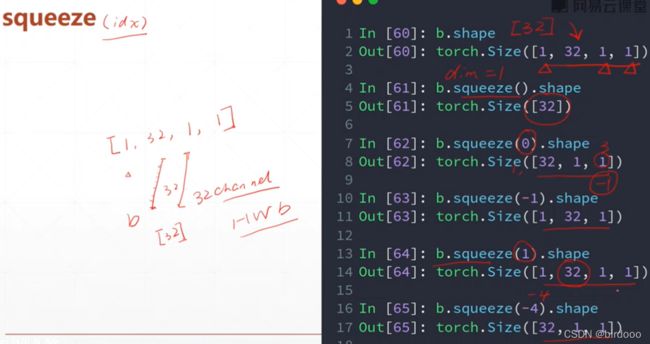
Squeeze v.s. unsqueeze
(挤压)减少维度/ (展开)增加维度

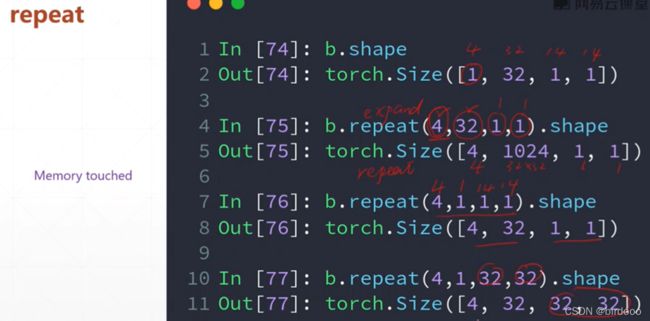
Expand/repeat(不建议使用)
扩展(不会主动复制数据,推荐)/扩展(增加数据)
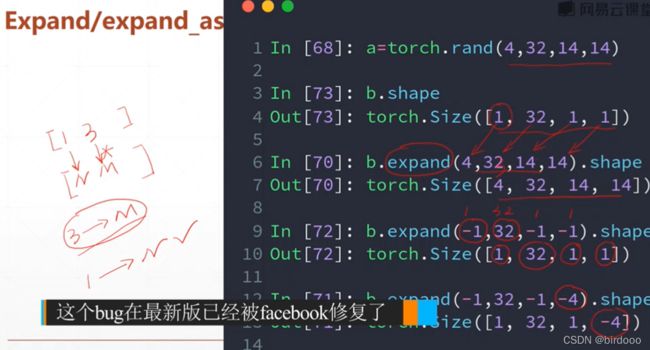
(-4为bug,新版本已经修复)
repeat中的参数,即原维度参数重复拷贝几次
.t 转置
.t只能适用于2D的tensor即二维矩阵

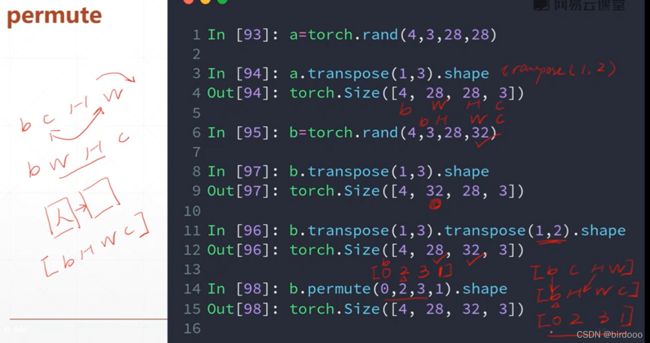
Transpose 维度交换(两两交换)
.transpose(1,3)即交换1,3维度
[b,c,H,W] ->[b,W,H,c]
.contiguous先让数据变为连续
恢复数据时需要按照原来数据/维度的顺序,否则会导致数据的污染
view会导致维度顺序关系变模糊,所以需要人为记住维度顺序,并跟踪注意,展开的时候也要按照原来的顺序
permute (任意的交换)
[b,H,W,c]是numpy存储图片的格式,需要这一步才能导出numpy
原本是[b,c,H,W]需要变为[b,H,W,c]
只需要permute(0,2,3,1) ,2代表原来的W,3代表原来的W,1代表原来的c
但也可能会导致内存的打乱