【Transformer系列】深入浅出理解Transformer网络模型(综合篇)
一、参考资料
The Illustrated Transformer
图解Transformer(完整版)
Attention Is All You Need: The Core Idea of the Transformer
transformer 总结(超详细-初版)
Transformer各层网络结构详解!面试必备!(附代码实现)
大语言模型核心技术-Transformer 详解
论文:Attention Is All You Need
二、Transformer相关介绍
T r a n s f o r m e r 是既 M L P 、 R N N 、 C N N 之后的第四大特征提取器,也被称为第四大基础模型。 \textcolor{red}{Transformer是既MLP、RNN、CNN之后的第四大特征提取器,也被称为第四大基础模型。} Transformer是既MLP、RNN、CNN之后的第四大特征提取器,也被称为第四大基础模型。
0. Transformer-CNN-RNN
Transformer的multi-head attention类似于CNN的多个不同kernel,可以提取丰富的上下文特征。但CNN的kernel只能处理局部的上下文特征,Transformer的attention的机制可以处理远距离的上下文特征,同时相对于RNN的架构,Transformer可以使用attention连接,进一步解决RNN网络在时序上面梯度消失的问题,使得Transformer能够处理更长的上下文特征。
1. RNN的缺点
RNN由于其顺序结构,训练速度常常受到限制。
RNN系列的模型,并行计算能力很差。RNN并行计算的问题就出在这里,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
2. seq2seq的缺点
seq2seq最大的问题在于,将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。
3. Transformer的优势和缺点
3.1 优势
-
并行计算能力。Transformer并行计算的能力是远远超过seq2seq系列的模型。
-
表征能力。Transformer让源序列和目标序列“自关联”起来,源序列和目标序列自身的embedding所蕴含的信息更加丰富,而且后续的FFN(前馈神经网络)层也增强了模型的表达能力。
-
特征提取能力。Transformer论文提出深度学习既MLP、CNN、RNN后的第4大特征提取器。Transformer具有全局视野,其特征提取能力比RNN系列的模型要好。具体实验对比可以参考:放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较。
-
语义结构。Transformer擅长捕捉文本和图像中的语义结构,它们比其他技术更好地捕捉文本甚至图像中的语义结构。Transformer的泛化能力和Diffusion Model(扩散模型)的细节保持能力的结合,提供了一种生成细粒度的高度详细图像的能力,同时保留图像中的语义结构。
-
泛化能力。在视觉应用中,Transformer表现出泛化和自适应的优势,使其适合通用学习。
3.2 缺点
第一,计算量大,对硬件要求高,在许多视觉领域也面临着性能方面的问题。
第二,因为无归纳偏置,需要大量的数据才可以取得很好的效果。
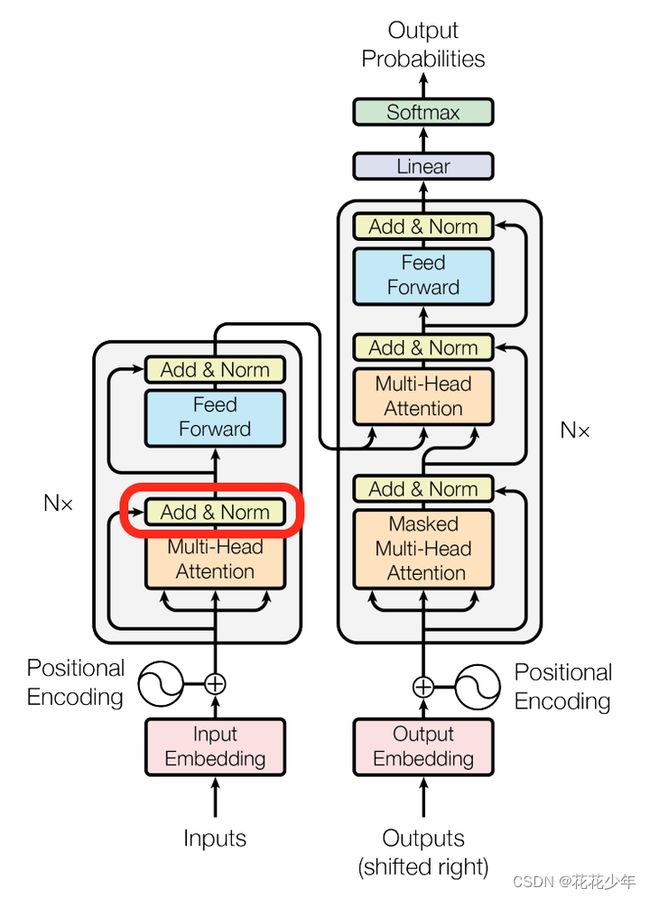
4. Transformer工作流
- 输入的词向量首先叠加上
Positional Encoding,然后输入至Transformer内; - 每个
Encoder Transformer会进行一次Multi-head Attention->Add & Normalize->FFN->Add & Normalize流程,然后将输出输入至下一个Encoder中; - 最后一个Encoder的输出将会作为memory保留;
- 每个
Decoder Transformer会进行一次Masked Multi-head Attention->Multi-head Attention->Add & Normalize->FFN->Add & Normalize流程,其中Multi-head Attention的K、V至来自于Encoder的memory。根据任务要求输出需要的最后一层Embedding; - Transformer的输出向量可以用来做各种下游任务。
5. Transformer输入输出维度变换
Transformer的整体结构,大致可分为:Input、Encoder、Decoder、Output。
- 输入:假设输入序列长度为T,则Encoder输入的维度为
[batch_size, T],经过embedding层、position encoding等流程后,生成[batch_size, T, D]的数据,D表示模型隐层维度; - Encoder:假设输入序列长度为T,则Encoder输入的维度为
[batch_size, T],经过embedding层、position encoding等流程后,生成[batch_size, T, D]的数据,D表示模型隐层维度; - Decoder:Decoder的输入也经过类似的变换得到
[batch_size, T', D],T’是Decoder输入长度。之后会进入多个相同结果的模块,每个模块包括:Self Multi-head Attention,表示Decoder序列上的元素内部做Attention,和Encoder是一样的;Add&Norm;Cross Multi-head Attention,是Decoder每个位置和Encoder各个位置进行Attention,类似于传统的seq2seq中的Attention,用来进行Decoder和Encoder的对齐;Add&Norm;Feed Forward;Add&Norm。
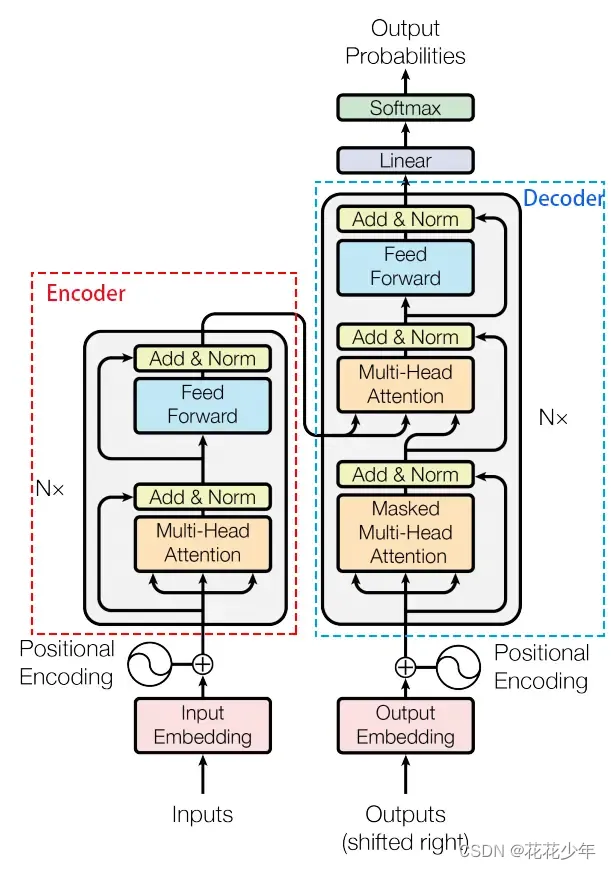
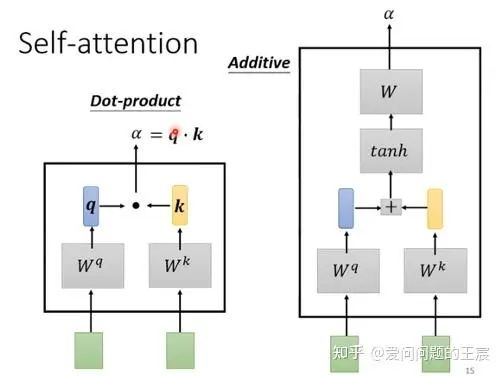
6. Scaled Dot-Product Attention
通过 query 和 key 的相似性程度来确定 value 的权重分布的方法,被称为 Scaled Dot-Product Attention。
Transformer为什么采用Scaled Dot-Product Attention?
-
目前常见的注意力机制有:加性注意力(additive attention)与点乘注意力(dot-product attention)。两者在理论复杂度相近,但由于矩阵乘法的代码已经比较优化,所以点乘注意力在实际中,不论是计算还是存储上都更有效率。
-
点乘注意力增加了1个缩放因子( 1 d k \frac1{\sqrt{d_k}} dk1 )。增加的原因是:当 d k \sqrt{d_k} dk 较小时,两种注意力机制的表现情况类似;而 d k \sqrt{d_k} dk 增大时,点乘注意力的表现变差,认为是由于点乘后的值过大,导致softmax函数趋近于边缘,梯度较小。
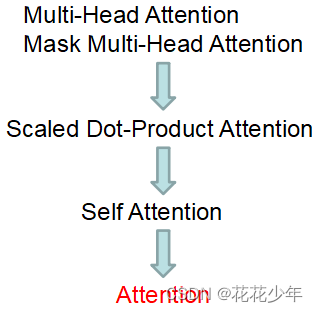
7. Attention与Transformer的关系
在Transformer中最多的 Multi-Head Attention 和 Mask Multi-Head Attention 来自 Scaled Dot-Product Attention,而 Scaled Dot-Product Attention来自 Self-Attention,而 Self-Attention 是 Attention 的一种,Attention与Transformer的关系,如下图所示。
8. Transformer在CV领域的应用
- 2020 年 5 月,Facebook AI 实验室推出Detection Transformer(DETR),用于目标检测和全景分割。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架, 在大型目标上的检测性能要优于 Faster R-CNN。
- 2020 年 10 月,谷歌提出了Vision Transformer (ViT),可以直接利用 Transformer 对图像进行分类,而不需要卷积网络。ViT 模型取得了与当前最优卷积网络相媲美的结果,但其训练所需的计算资源大大减少。
三、Transformer结构
全网最强ViT (Vision Transformer)原理及代码解析
Transformer的结构和Attention模型一样,采用 encoer-decoder 架构。但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
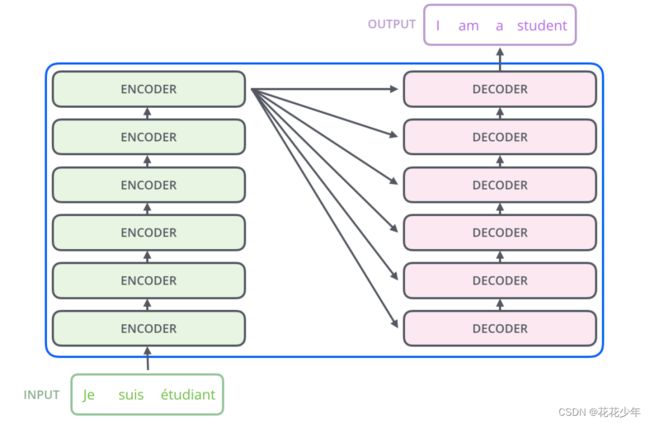
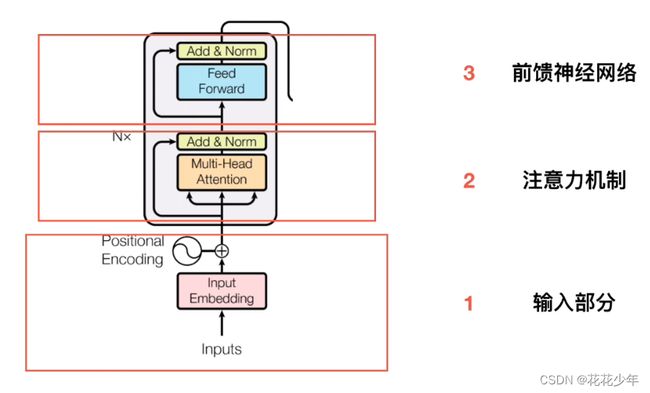
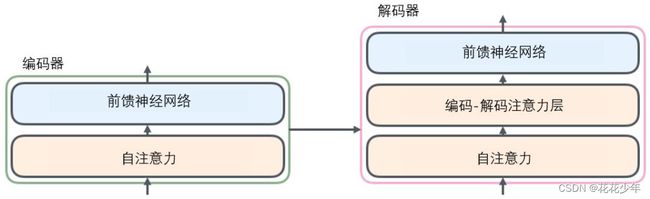
0. 总体结构
Transformer是由一堆Encoder和Decoder形成的,Encoder和Decoder均由多头注意力层和全连接前馈网络组成,网络的高层结构如下:
- Encoder由N个编码器块(
Encoder Block)串联组成,每个编码器块包含:- 一个多头注意力(
Multi-Head Attention)层; - 一个前馈全连接神经网络(
Feed Forward Neural Network);
- 一个多头注意力(
- Decoder也由N个解码器块(
Decoder Block)串联组成,每个解码器块包含:- 一个多头注意力层;
- 一个对Encoder输出的多头注意力层;
- 一个前馈全连接神经网络;
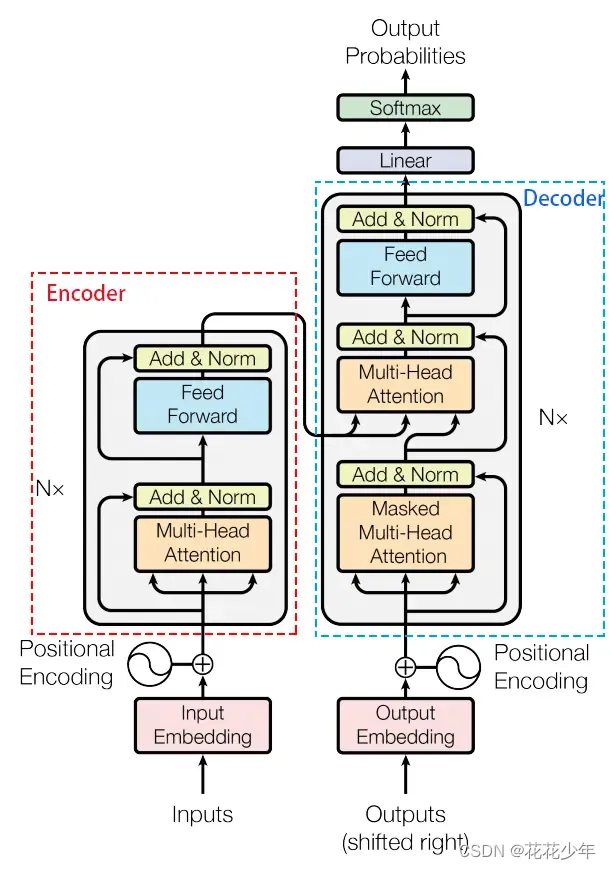
1. Transformer 输入
Transformer 中单词的输入表示 x 由 词嵌入(Embedding) 和 位置编码(Positional Encoding) 相加得到。
1.1 词嵌入(Embedding)
Embedding 原理的详细介绍,请查阅博客:【Transformer系列】深入浅出理解Embedding(词嵌入)
Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
1.2 位置编码(Positional Embedding)
Positional Embedding 原理的详细介绍,请查阅博客:【Transformer系列】深入浅出理解Positional Encoding位置编码
Transformer 中除了 Embedding(词嵌入),还需要使用 Positional Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用 Positional Embedding 保存单词在序列中的相对或绝对位置。
Attention中缺少一种解释输入序列中单词顺序的方法,它跟序列模型(RNN)还不一样。为了处理这个问题,Transformer对输入进行位置编码,以便在翻译中考虑单词在句子中的位置。具体来说,Transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,Transformer论文中使用一组正弦和余弦方程来实现,计算方法如下:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i)=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i+1)=cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i+1)=cos(10000dmodel2ipos)
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
最后把这个Positional Encoding与embedding的值相加,作为输入送到下一层。
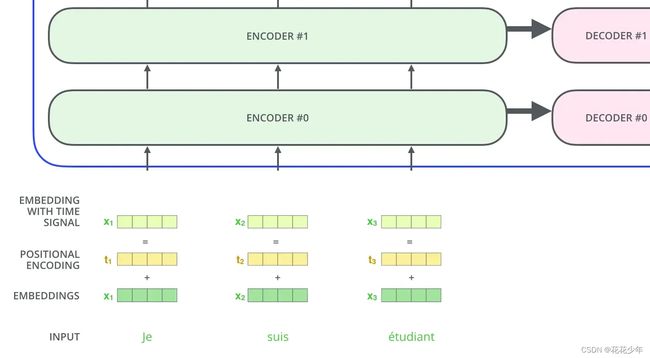
2. 编码器(Encoder)
2.1 Encoder编码过程
首先,模型需要对输入的数据进行一个词嵌入(embedding)操作,也可以理解为类似w2c的操作,enmbedding结束之后,输入到encoder层,self-attention处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个encoder。
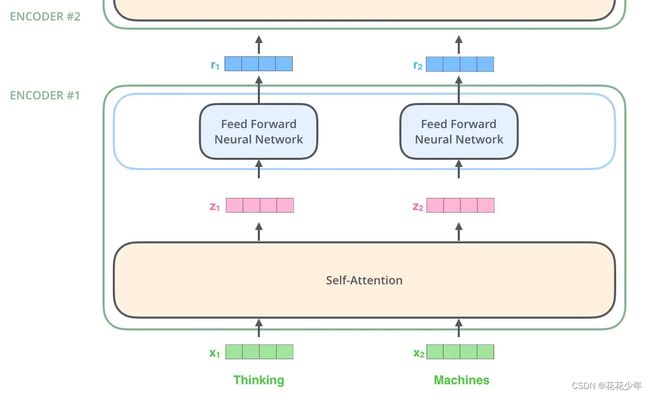

2.2 Encoder结构
Encoder 结构由 N = 6 \text{N} = 6 N=6 个相同的 Encoder block 堆叠而成,Encoder block 由 Multi-Head Attention、Add&Norm、Feed Forward层组成。每个 Encoder block 的输入矩阵和输出矩阵维度是一样的,每一层主要有两个子层:
- 第一个子层是多头注意力机制(
Multi-Head Attention); - 第二个是简单的位置全连接前馈网络(
Positionwise Feed Forward)。
2.3 Self-Attention
Self-Attention原理的详细介绍,请查阅博客:【Transformer系列】深入浅出理解Attention和Self-Attention机制
2.4 Multi-Headed Attention
Multi-Headed Attention原理的详细介绍,请查阅博客:【Transformer系列】深入浅出理解Attention和Self-Attention机制
Multi-Headed Attention是在Self-Attention基础上改进的,也就是在产生q,k,v的时候,对q,k,v进行了切分,分别分成了num_heads份,对每一份分别进行self-attention的操作,最后再拼接起来,这样在一定程度上进行了参数隔离。
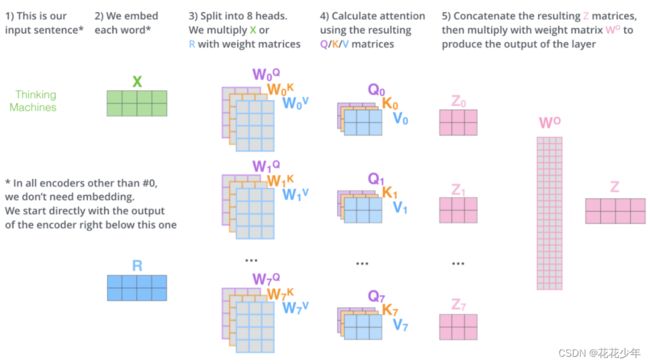
Multi-Headed Attention 不仅仅只初始化一组Q、K、V的矩阵,而是初始化多组,Transformer是使用了8组,所以最后得到的结果是8个矩阵。
Multi-head Attention的示意图如下:

2.5 Add & Norm结构
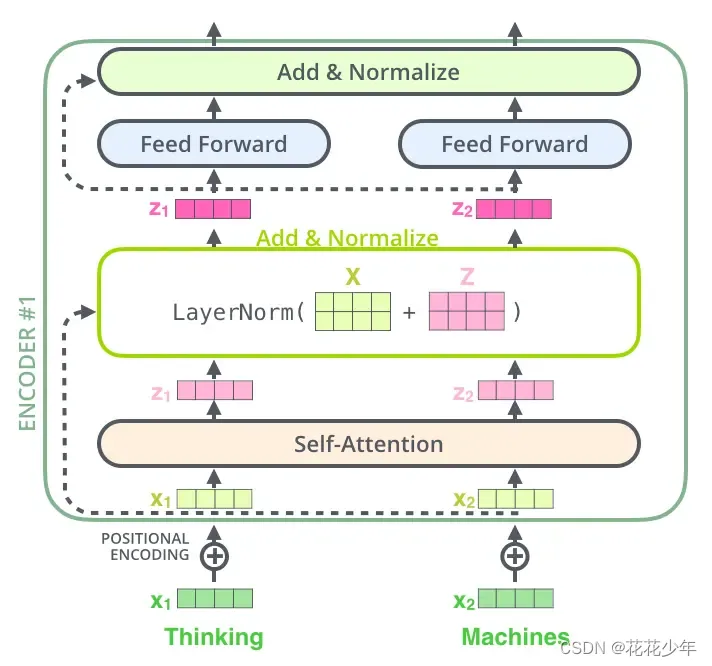
在Transformer中,每一个子层(self-attetion,Feed Forward Neural Network)之后都会接一个残缺模块,并且有一个Layer normalization。
Add & Norm 层由 Add 和 Norm 两部分组成。这里的 Add 指 X + MultiHeadAttention(X),是一种残差连接。Norm 指的是 Layer Normalization。Add & Norm 层计算过程用数学公式可表达为:
Layer Norm ( X + MultiHeadAttention ( X ) ) \text{Layer Norm}(X+\text{MultiHeadAttention}(X)) Layer Norm(X+MultiHeadAttention(X))
其中,Add代表 Residual Connection 残差连接,是为了解决多层神经网络训练困难的问题。通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分,这一方法在图像处理结果如ResNet等中常常用到。
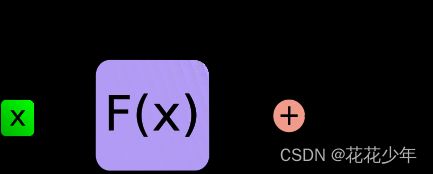
Layer Normalization 是一种常用的神经网络归一化技术,可以使得模型训练更加稳定,收敛更快。Layer Normalization和 Batch Normalization 有相同的作用,都是为了使输入的样本均值为零,方差为1。Layer Normalization对每个样本在特征维度上进行归一化,减少了不同特征之间的依赖关系,提高了模型的泛化能力,其原理可参考论文:Layer Normalization。
Layer Norm 层的计算可视化如下图所示:
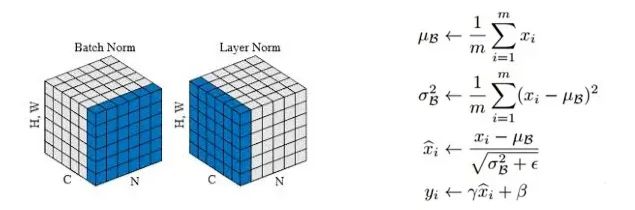
为什么不使用 Batch Normalization,使用的是 Layer Normalization 呢?
因为一个时序数据,句子输入长度有长有短,如果使用 Batch Normalization,则很容易造成因样本长短不一造成“训练不稳定”。BN是对同一个batch内的所有数据的同一个特征数据进行操作;而LN是对同一个样本进行操作。
2.6 Feed Forward结构
前馈神经网络( Feed Forward Neural Network,简称FFN),其本质是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,计算过程用数学公式可表达为:
FFN ( X ) = max ( 0 , X W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(X)=\max(0,XW_1+b_1)W_2+b_2 FFN(X)=max(0,XW1+b1)W2+b2
除了使用两个全连接层来完成线性变换,另外一种方式是使用 kernal_size = 1 的两个 1 × 1 1\times 1 1×1 卷积层,输入输出维度不变,都是 512,中间维度是 2048。
Feed Forward没法输入 8 个矩阵,这该怎么办呢?所以我们需要一种方式,把 8 个矩阵降为 1 个。首先,我们把 8 个矩阵连在一起,这样会得到一个大矩阵,再随机初始化一个权重矩阵,并与这个组合好的大矩阵相乘,得到一个最终的矩阵。
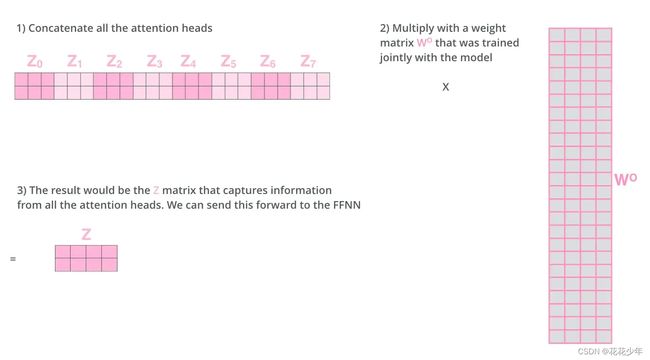
3. 编码器(Decoder)
根据上面的总体结构图可以看出,Decoder的结构与Encoder结构大同小异,先添加一个 Positional Encoding 位置向量,再接一个masked mutil-head attetion,这里的mask是Transformer一个很关键的技术,本章节对其进行详细介绍。其余的层结构与Encoder一样,请参考Encoder层结构。
3.1 Decoder结构

3.2 Masked Multi-Head Attention
3.2.1 Masked Multi-Head Attention的概念
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。由于使用了 Masked Multi-Head Attention,所以每个位置的词只能看到前面词的状态,不会“看见”后面的词,所以 Masked Multi-Head Attention 是一个单向的Self-Attention结构。Transformer预测第T个时刻的输出,不能看到T时刻之后的那些输入,从而保证训练和预测一致。
知识 t i p s \textcolor{red}{知识tips} 知识tips:
什么是单向Transformer?在Decoder Block中,使用了Masked Self-Attention,即句子中的每个词,都只能对包括自己在内的前面所有词进行Attention,这就是单向Transformer。换句话说,采用了mask操作的是单向Transformer,否则为双向Transformer。
3.2.2 mask的分类
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
通过 query 和 key 的相似性程度来确定 value 的权重分布的方法,被称为
scaled dot-product attention。
-
对于 decoder 的 self-attention,里面使用到的
scaled dot-product attention,同时需要padding mask和sequence mask作为attn_mask,具体实现就是两个mask相加作为attn_mask。 -
其他情况,
attn_mask一律等于padding mask。
3.2.2.1 padding mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的,也就是说,我们要对输入序列进行对齐。具体来说,就是给较短的序列后面填充 0。如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。对于太长的输入序列,这些填充的位置,是没什么意义的,attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样经过 softmax,这些位置的概率就会接近0。
padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
3.2.2.2 Sequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
3.2.3 Masked Multi-Head Attention 计算过程
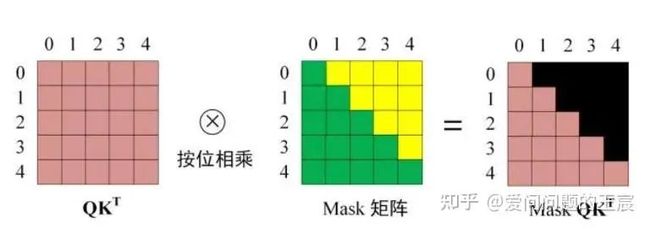
Masked Multi-Head Attention 的实现也非常简单,只要在普通的Self Attention的Softmax步骤之前,与(&)上一个mask矩阵M(下三角矩阵)就好了,其公式如下所示:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T ⊙ M d k ) V Attention(Q,K,V)=Softmax(\frac{QK^T\odot M}{\sqrt{d_k}})V Attention(Q,K,V)=Softmax(dkQKT⊙M)V
Q1只跟K1计算,Q2只跟K1、K2计算,而对于K3、K4等,在softmax之前给一个非常大的负数,由此经过softmax之后变为0,其在矩阵上的计算原理实现如下图所示。
3.3 Output层
当decoder层全部执行完毕后,怎么把得到的向量映射为我们需要的词呢,很简单,只需要在结尾再添加一个全连接层和 softmax层。假如词典有1w个词,那最终softmax会输入1w个词的概率,概率值最大的对应的词就是最终的结果。
4. 动态流程图
编码器阶段,编码器通过处理输入序列开启工作。顶端编码器的输出之后会转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 ,这是并行化操作。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列的相关性(重要程度):
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列的元素(例如,English翻译成German)。
接下来的步骤,重复这个过程,直到到达一个特殊的终止符号,它表示Transformer的解码器已经完成了它的输出。每个步骤的输出在下一个time_step(时间步)被提供给底端解码器,这些解码器会输出它们的解码结果 。
5. Transformer总结
- Transformer 与 RNN 不同,可以较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加
Positional Encoding位置编码,否则 Transformer 就是一个词袋模型了。 - Transformer 的重点是
Self-Attention结构,其中用到的Q, K, V矩阵通过线性变换得到。 - Transformer 中
Multi-Head Attention中有多个Self-Attention,可以捕获单词之间多种维度上的相关系数Attention Score。
四、相关经验
A TensorFlow Implementation of Attention Is All You Need
Transformer解析与tensorflow代码解读
熬了一晚上,我从零实现了Transformer模型,把代码讲给你听
零基础理解为什么是Transformer?什么是Transformer?(深入浅出 通俗理解Transformer及其pytorch源码)
1. 开源项目
Transformers
NLP_ability
ML-NLP
2. Self-Attention代码实现
class ScaleDotProductAttention(nn.Module):
def __init__(self, ):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim = -1)
def forward(self, Q, K, V, mask=None):
K_T = K.transpose(-1, -2) # 计算矩阵 K 的转置
d_k = Q.size(-1)
# 1, 计算 Q, K^T 矩阵的点积,再除以 sqrt(d_k) 得到注意力分数矩阵
scores = torch.matmul(Q, K_T) / math.sqrt(d_k)
# 2, 如果有掩码,则将注意力分数矩阵中对应掩码位置的值设为负无穷大
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3, 对注意力分数矩阵按照最后一个维度进行 softmax 操作,得到注意力权重矩阵,值范围为 [0, 1]
attn_weights = self.softmax(scores)
# 4, 将注意力权重矩阵乘以 V,得到最终的输出矩阵
output = torch.matmul(attn_weights, V)
return output, attn_weights
# 创建 Q、K、V 三个张量
Q = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
K = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
V = torch.randn(5, 10, 64) # (batch_size, sequence_length, d_k)
# 创建 ScaleDotProductAttention 层
attention = ScaleDotProductAttention()
# 将 Q、K、V 三个张量传递给 ScaleDotProductAttention 层进行计算
output, attn_weights = attention(Q, K, V)
# 打印输出矩阵和注意力权重矩阵的形状
print(f"ScaleDotProductAttention output shape: {output.shape}") # torch.Size([5, 10, 64])
print(f"attn_weights shape: {attn_weights.shape}") # torch.Size([5, 10, 10])
3. Multi-head Attention代码实现
class MultiHeadAttention(nn.Module):
"""Multi-Head Attention Layer
Args:
d_model: Dimensions of the input embedding vector, equal to input and output dimensions of each head
n_head: number of heads, which is also the number of parallel attention layers
"""
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model) # Q 线性变换层
self.w_k = nn.Linear(d_model, d_model) # K 线性变换层
self.w_v = nn.Linear(d_model, d_model) # V 线性变换层
self.fc = nn.Linear(d_model, d_model) # 输出线性变换层
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) # size is [batch_size, seq_len, d_model]
# 2, split by number of heads(n_head) # size is [batch_size, n_head, seq_len, d_model//n_head]
q, k, v = self.split(q), self.split(k), self.split(v)
# 3, compute attention
sa_output, attn_weights = self.attention(q, k, v, mask)
# 4, concat attention and linear transformation
concat_tensor = self.concat(sa_output)
mha_output = self.fc(concat_tensor)
return mha_output
def split(self, tensor):
"""
split tensor by number of head(n_head)
:param tensor: [batch_size, seq_len, d_model]
:return: [batch_size, n_head, seq_len, d_model//n_head], 输出矩阵是四维的,第二个维度是 head 维度
# 将 Q、K、V 通过 reshape 函数拆分为 n_head 个头
batch_size, seq_len, _ = q.shape
q = q.reshape(batch_size, seq_len, n_head, d_model // n_head)
k = k.reshape(batch_size, seq_len, n_head, d_model // n_head)
v = v.reshape(batch_size, seq_len, n_head, d_model // n_head)
"""
batch_size, seq_len, d_model = tensor.size()
d_tensor = d_model // self.n_head
split_tensor = tensor.view(batch_size, seq_len, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return split_tensor
def concat(self, sa_output):
""" merge multiple heads back together
Args:
sa_output: [batch_size, n_head, seq_len, d_tensor]
return: [batch_size, seq_len, d_model]
"""
batch_size, n_head, seq_len, d_tensor = sa_output.size()
d_model = n_head * d_tensor
concat_tensor = sa_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return concat_tensor
4. Add & Norm代码实现
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True) # '-1' means last dimension.
var = x.var(-1, keepdim=True)
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
# 1,Activate nn.LayerNorm module
layer_norm1 = nn.LayerNorm(embedding_dim)
pytorch_ln_out = layer_norm1(embedding)
# 2,Activate my nn.LayerNorm module
layer_norm2 = LayerNorm(embedding_dim)
my_ln_out = layer_norm2(embedding)
# 比较结果
print(torch.allclose(pytorch_ln_out, my_ln_out, rtol=0.1,atol=0.01)) # 输出 True
5. Feed Forward代码实现
PositionwiseFeedForward 层的 Pytorch 实现代码如下所示:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_diff, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_diff)
self.fc2 = nn.Linear(d_diff, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(drop_prob)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
6. Encoder代码实现
基于前面 Multi-Head Attention, Feed Forward, Add & Norm 的内容我们可以完整的实现 Encoder 结构。
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, n_head)
self.ffn = PositionwiseFeedForward(d_model, ffn_hidden)
self.ln1 = LayerNorm(d_model)
self.ln2 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(drop_prob)
self.dropout2 = nn.Dropout(drop_prob)
def forward(self, x, mask=None):
x_residual1 = x
# 1, compute multi-head attention
x = self.mha(q=x, k=x, v=x, mask=mask)
# 2, add residual connection and apply layer norm
x = self.ln1( x_residual1 + self.dropout1(x) )
x_residual2 = x
# 3, compute position-wise feed forward
x = self.ffn(x)
# 4, add residual connection and apply layer norm
x = self.ln2( x_residual2 + self.dropout2(x) )
return x
class Encoder(nn.Module):
def __init__(self, enc_voc_size, seq_len, d_model, ffn_hidden, n_head, n_layers, drop_prob=0.1, device='cpu'):
super().__init__()
self.emb = TransformerEmbedding(vocab_size = enc_voc_size,
max_len = seq_len,
d_model = d_model,
drop_prob = drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model, ffn_hidden, n_head, drop_prob)
for _ in range(n_layers)])
def forward(self, x, mask=None):
x = self.emb(x)
for layer in self.layers:
x = layer(x, mask)
return x
7. Decoder代码实现
Decoder 组件的代码实现如下所示:
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, n_head)
self.ln1 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.mha2 = MultiHeadAttention(d_model, n_head)
self.ln2 = LayerNorm(d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model, ffn_hidden)
self.ln3 = LayerNorm(d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec_out, enc_out, trg_mask, src_mask):
x_residual1 = dec_out
# 1, compute multi-head attention
x = self.mha1(q=dec_out, k=dec_out, v=dec_out, mask=trg_mask)
# 2, add residual connection and apply layer norm
x = self.ln1( x_residual1 + self.dropout1(x) )
if enc_out is not None:
# 3, compute encoder - decoder attention
x_residual2 = x
x = self.mha2(q=x, k=enc_out, v=enc_out, mask=src_mask)
# 4, add residual connection and apply layer norm
x = self.ln2( x_residual2 + self.dropout2(x) )
# 5. positionwise feed forward network
x_residual3 = x
x = self.ffn(x)
# 6, add residual connection and apply layer norm
x = self.ln3( x_residual3 + self.dropout3(x) )
return x
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output
8. Transformer代码实现
大语言模型核心技术-Transformer 详解
基于前面实现的 Encoder 和 Decoder 组件,我们可以实现 Transformer 模型的完整代码,如下所示:
import torch
from torch import nn
from models.model.decoder import Decoder
from models.model.encoder import Encoder
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size, d_model, n_head, max_len,
ffn_hidden, n_layers, drop_prob, device):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.device = device
self.encoder = Encoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
enc_voc_size=enc_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
self.decoder = Decoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
dec_voc_size=dec_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
def forward(self, src, trg):
src_mask = self.make_pad_mask(src, src, self.src_pad_idx, self.src_pad_idx)
src_trg_mask = self.make_pad_mask(trg, src, self.trg_pad_idx, self.src_pad_idx)
trg_mask = self.make_pad_mask(trg, trg, self.trg_pad_idx, self.trg_pad_idx) * \
self.make_no_peak_mask(trg, trg)
enc_src = self.encoder(src, src_mask)
output = self.decoder(trg, enc_src, trg_mask, src_trg_mask)
return output
def make_pad_mask(self, q, k, q_pad_idx, k_pad_idx):
len_q, len_k = q.size(1), k.size(1)
# batch_size x 1 x 1 x len_k
k = k.ne(k_pad_idx).unsqueeze(1).unsqueeze(2)
# batch_size x 1 x len_q x len_k
k = k.repeat(1, 1, len_q, 1)
# batch_size x 1 x len_q x 1
q = q.ne(q_pad_idx).unsqueeze(1).unsqueeze(3)
# batch_size x 1 x len_q x len_k
q = q.repeat(1, 1, 1, len_k)
mask = k & q
return mask
def make_no_peak_mask(self, q, k):
len_q, len_k = q.size(1), k.size(1)
# len_q x len_k
mask = torch.tril(torch.ones(len_q, len_k)).type(torch.BoolTensor).to(self.device)
return mask
9. 机器翻译(示例)
我们以一个法语翻译成英语的例子,来讲解Transformer进行机器翻译的的过程:

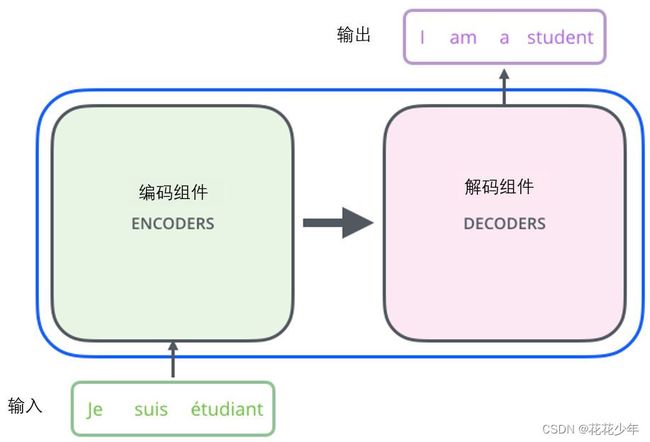
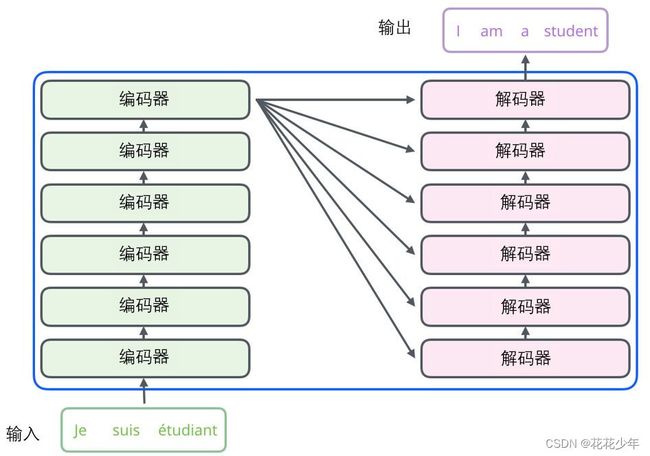
9.1 Step 1
首先,输入句子的Embedding(词嵌入)会被传递到编码器块,该块具有多头注意力机制。将词嵌入和权重矩阵计算出的Q,K和V值输入到这个模块,然后生成一个可以传递到前馈神经网络的矩阵。在Transformer的论文中,这个编码块会被重复N次,一般N的值为6。

9.2 Step 2
然后,编码器的输出会被输入到解码器块。解码器的任务是输出英文翻译。解码器块的每一步都会输入已经生成的翻译的前几个单词。刚开始时,翻译会以一个开始句子的标记开始。这个标记被输入到多头注意力块,并用于计算这个多头注意力块的Q,K和V。这个块的输出会用于生成下一个多头注意力块的Q矩阵,而编码器的输出会用于生成K和V。
9.3 Step 3
解码器块的输出被输入到前馈神经网络,该网络的任务是预测句子中的下一个单词。
10. Transformer代码解析
The Annotated Transformer
annotated-transformer