如何提升大模型的推理和规划能力:思维链 CoT + 由少至多提示 Least-to-Most Prompting
如何提升大模型的推理和规划能力
- 思维链 - CoT
- 思维链改进:Auto-CoT
- 由少至多提示 - Least-to-Most Prompting
思维链 - CoT
最初的语言模型都是基于经验的,只能根据词汇之间的相关性输出答案,根本没有思考能力……
但是从使用思维链后,大模型已经是有思考能力的。能进行一定的推理。
2021年,OpenAI在训练神经网络过程中有一个意外发现。
神经网络他可以很好地模仿现有的数据,很少犯错误。
可是如果你给他出个没练过的题目,他还是说不好。于是你就让他继续练。
继续训练好像没什么意义,因为现在只要是模仿他就都能说得很好,只要是真的即兴发挥他就不会。
但你不为所动,还是让他练。

1 0 2 10^2 102 到 1 0 5 10^5 105 训练完全没有成果。
就这样练啊练,惊奇地发现,他会即兴演讲了!给他一个什么题目,他都能现编现讲,发挥得很好!
- 一千步乃至一万步,模型对训练题的表现已经非常好了,但是对生成性题目几乎没有能力
- 练到10万步,模型做训练题的成绩已经很完美,对生成性题也开始有表现了
- 练到100万步,模型对生成性题目居然达到了接近100%的精确度
这就是量变产生质变。研究者把这个现象称为「开悟(Grokking)」。
2022年8月,谷歌大脑研究者发布一篇论文,专门讲了大型语言模型的一些涌现能力,包括少样本学习、突然学会做加减法、突然之间能做大规模、多任务的语言理解、学会分类等等……
而这些能力只有当模型参数超过1000亿才会出现 —— 涌现新能力的关键机制,叫 思维链。
此前的模式是直接让模型输出结果,而忽略了其中的思考过程。
人类在解决包括数学应用题在内的,涉及多步推理的问题时,通常会逐步书写整个解题过程的中间步骤,最终得出答案。如果明确告知模型先输出中间推理步骤,再根据生成的步骤得出答案,是否能够提升其推理表现呢?
除了将问题输入给模型外,还将类似题目的解题思路和步骤输入模型,使得模型不仅输出最终结果,还输出中间步骤,从而提升模型的推理能力的方法。
思维链就是当模型听到一个东西之后,它会嘟嘟囔囔自说自话地,把它知道的有关这个东西的各种事情一个个说出来。
思维链是如何让语言模型有了思考能力的呢?
比如你让模型描写一下“夏天”,它会说:“夏天是个阳光明媚的季节,人们可以去海滩游泳,可以在户外野餐……”等等。
只要思考过程可以用语言描写,语言模型就有这个思考能力。
怎么用思维链呢?
思维链的主要思想是通过向大语言模型展示一些少量的样例,在样例中解释推理过程。
那大语言模型在回答提示时也会显示推理过程,这种推理的解释往往会引导出更准确的结果。
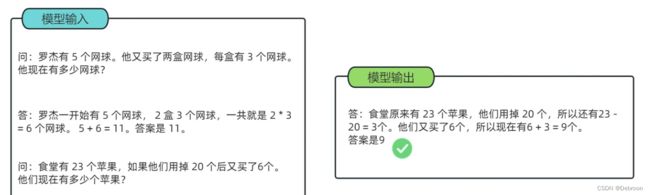
既然如此,只要我们设置好让模型每次都先思考一番再回答问题,ta就能自动使用思维链,ta就有了思考能力。
CoT(链式思考)已被证实能够改善大型AI模型在算术、常识和符号推理等任务上的表现。
用户发现,当他们在问题中添加“让我们一步步来思考”时,模型仿佛被施了魔法,之前答错的数学题突然能够正确解答,原本无理的论述变得有条有理。
不过,CoT对模型性能的提升与模型的大小成正比关系,模型参数至少达到100亿才有效果,达到1000亿效果才明显。
研究中指出,处理策略性问题通常需要大量的世界知识。
然而,小型模型由于其有限的参数,往往难以存储这些庞大的知识信息,这限制了它们在产生正确推理步骤方面的能力。
思维链改进:Auto-CoT
使用了人工构造的思维链。然而,由不同人员编写的推理范例,在准确率上存在高达 28.2% 的差异。
因此,如果能够自动构建具有良好问题和推理链的范例,则可以大幅度提升推理效果。
Auto-CoT 可以让机器从各种问题中学习,生成多种多样的推理链。
这个方法首先把类似的问题分成不同的组,然后从每一组中挑选出代表性的问题,并让机器学习如何解答这些问题。
- 问题向量表示:使用 Sentence-BERT 对问题进行编码。
- 聚类算法:使用 K-means 根据问题的向量表示进行聚类。
- 排序:根据问题到聚类中心的距离进行排序。
- 范例构建:选择距离中心近的问题,并生成推理链。

-
Clustering(聚类): 将类似问题通过聚类算法分组,如图中的几个小圆圈所示。
-
LLM Demo Construction(LLM 示范构建): 根据选择的标准,从每个问题簇中抽取一个代表性的问题,并利用语言模型构建出问题的解决步骤或推理链,即“Let’s think step by step…”的过程。
-
Sampling by Selection Criteria(按选择标准抽样): 从每个簇中选取问题并生成推理链,这可能包括使用问题本身作为提示输入到模型中,并观察模型如何一步一步解决问题。
-
Test Question(测试问题): 这是一个实际例子,说明了如何将上述方法应用于一个具体的问题——宠物店的问题。在这个例子中,解释了宠物店如何根据出售的小狗数量和每个笼子里的小狗数量来决定需要多少笼子。
这种方法可以提升大型语言模型处理复杂、多步骤问题的能力,尤其是需要详细解释步骤的场合中。
以及强调多样性在构建有效范例中的重要性。
也还有一些研究人员提出了对思维链提示的改进方法,例如从训练样本中选取推理最复杂的样本来形成示例样本,被称为 Complex-CoT。
也有研究者指出可以从问题角度考虑优化思维链提示,通过将复杂的、模糊的、低质量的问题优化为模型更易理解的高质量问题,进一步提升思维链提示的性能,被称为 Self-Polish。
由少至多提示 - Least-to-Most Prompting
通过引导模型首先将复杂问题分解为多个较为简单的子问题,然后逐一解决这些子问题,可引导模型得出最终解答,这种策略被称为 由少至多提示。
当面对复杂任务或者问题时,人类通常倾向于将其转化为多个更容易解决的子任务/子问题,并逐一解决它们,得到最终想要的答案或者结果。
这种能力就是通常所说的任务分解能力。
基于这种问题解决思路,研究人员们提出了由 少至多提示 (Least-to-Most Prompting)方法。
主要包含两个阶段:
- 问题分解阶段
- 逐步解决子问题阶段
在问题分解阶段中,模型的输入包括 k×[原始问题,子问题列表] 的组合,以及要测试的原始问题;
在逐步解决子问题阶段中,模型的输入包括 k×[原始问题,m×(子问题,子答案)] 元组,以及要测试的原始问题和当前要解决的子问题。

阶段 1:问题简化
- 在这个阶段,原始问题是关于Amy在水滑梯关闭前可以滑多少次的。问题的复杂性在于它包含多个步骤的计算。
阶段 2:顺序解决子问题
为了解决这个问题,语言模型采取了分步骤的方法,将原始问题分解为两个子问题。
-
子问题 1: 首先,模型被问到每次滑行需要多少时间。这是解决原始问题的第一步,因为只有知道了每次滑行的时间,我们才能计算出Amy在水滑梯关闭前可以滑多少次。
模型的答案是:每次滑行需要5分钟(爬上去需要4分钟,滑下来需要1分钟)。
-
子问题 2: 接下来,模型使用了子问题 1 的答案来解决最初的问题——Amy在水滑梯关闭前可以滑多少次。
模型的答案是:水滑梯在15分钟内关闭,每次滑行需要5分钟,所以Amy可以在水滑梯关闭前滑3次。
通过将一个问题分解成多个更简单的子问题,一个语言模型可以逐步构建答案,并最终解决原始问题。
分步解决问题的逻辑思维,及如何有效地使用语言模型来辅助问题解决过程。