MybatisPlus框架入门级理解
MybatisPlus
-
- 快速入门
-
- 入门案例
- 常见注解
- 常用配置
- 核心功能
-
- 条件构造器
- 自定义SQL
- Service接口
快速入门
入门案例
使用MybatisPlus的基本步骤:
1.引入MybatisPlus的起步依赖
MybatisPlus官方提供了starter,其中集成了Mybatis和MybatisPlus的所有功能,并且实现了自动装配效果。因此,可以使用MybatisPlus的starter代替Mybatis的starter。
pom.xml
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.5.3.1version>
dependency>
2.自定义的Mapper继承MybatisPlus提供的BaseMapper接口
public interface UserMapper extends BaseMapper<User> {
}
3.在实体类上添加注解声明表信息
4.在application.yml中根据需要添加配置
注:如果application.yml没有显示绿叶,可以按照以下步骤进行添加:
File --> Project Structure --> Facets --> “+” Spring --> 右上角小绿叶 Customize Spring Boot --> 将项目中的application.yml添加进去即可
常见注解
MybatisPlus是如何获取实现CRUD的数据库信息的?
- 默认以类名驼峰转下划线作为表名
- 默认把名为id的字段作为主键
- 默认把变量名驼峰转下划线作为表的字段名
MybatisPlus通过扫描实体类,并基于反射获取实体类信息作为数据库表信息。
MybatisPlus中比较常用的几个注解如下:
-
@TableName:用来指定表名 -
@TableId:用来指定表中的主键字段信息
IdType枚举:
①AUTO:数据库自增长
②INPUT:通过set方法自行输入
③ASSIGN_ID:分配ID,接口IdentifierGenerator的方法nextId来生成id -
@TableField:用来指定表中的普通字段信息
使用场景:
①成员变量名与数据库字段名不一致
②成员变量名以is开头,且是布尔值
③成员变量名与数据库关键字冲突,如“order”,在@TableField中要用转义字符括起来
⑩成员变量不是数据库字段,@TableField(exist = false)
常用配置
MyBatisPlus的配置项继承了MyBatis原生配置和一些自己特有的配置。
application.yml
mybatis-plus:
type-aliases-package: com.wmy.mp.domain.po # 别名扫描包
mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址 默认值
configuration:
map-underscore-to-camel-case: true # 是否开启下划线和驼峰的映射
cache-enabled: false # 是否开启二级缓存
global-config: # 全局配置 优先级低于局部的配置
db-config:
id-type: assign_id # id为雪花算法生成
update-strategy: not_null # 更新策略:只更新非空字段
MybatisPlus官方文档
核心功能
条件构造器
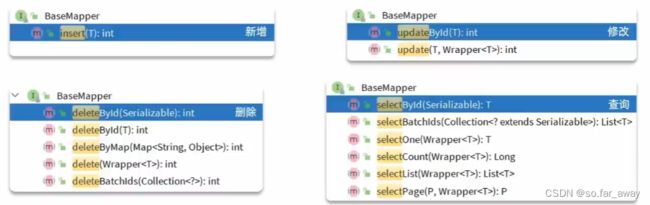
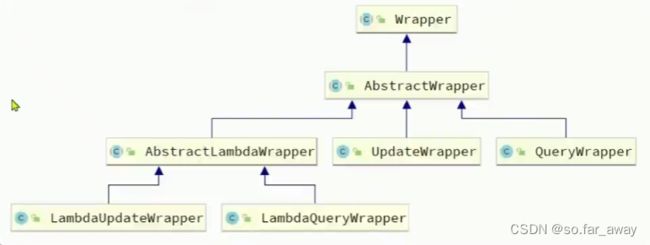
MybatisPlus支持各种复杂的where条件,可以满足日常开发的所有需求。在MybatisPlus中BaseMapper接口是用来提供增删改查功能的,其中一些比较特殊的方法的参数都不再是简单的id,而是一个Wrapper类型的参数,所谓的Wrapper就是条件构造器,用以构造复杂的sql语句。Wrapper并不是一个简单的类,而是类似于Collection,具备一个复杂的继承体系。
比如说:
QueryWrapper就是在父类基础上拓展了select相关的功能,允许构造SQL语句时能指定select哪些字段;
UpdateWrapper就是在父类基础上拓展了set相关的功能,它的setSql(boolean , String ) : UpdateWrapper方法允许将set部分的字符串当做参数传递进去,后边可以拼接到SQL语句中。
基于QueryWrapper的查询案例
需求
①查询出名字中带"o"的,存款大于等于1000元的人的id、username、info、balance字段。
SQL语句
SELECT id,username,info,balance
FROM user
WHERE username LIKE ? AND balance >= ?
QueryWrapper查询:UserMapperTest.java
@Test
void testQueryWrapper(){
//1.构件查询条件
QueryWrapper<User> wrapper = new QueryWrapper<User>()
.select("id", "username", "info", "balance")
.like("username", "o")
.ge("balance", 1000);
//2.查询
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
//或者
@Test
void testLambdaQueryWrapper(){
//1.构件查询条件
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.select(User::getId, User::getUsername, User::getInfo, User::getBalance)
.like(User::getUsername, "o")
.ge(User::getBalance, 1000);
//2.查询
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
加粗样式
②更新用户名为jack的用户的余额为2000。
SQL语句
UPDATE user
SET balance = 2000
WHERE (username = "jack")
QueryWrapper查询
@Test
void testUpdateByQueryWrapper() {
//1.要更新的数据
User user = new User();
user.setBalance(2000);
//2.更新的条件
QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "jack");
//3.执行更新
userMapper.update(user, wrapper);
}
基于UpdateWrapper的更新案例
需求
更新id为1,2,4的用户的余额,扣200
SQL语句
UPDATE user
SET balance = balance - 200
WHERE id in (1, 2, 4)
UpdateWrapper查询:UserMapperTest.java
@Test
void testUpdateWrapper(){
List<Long> ids = List.of(1L ,2L ,4L);
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
.setSql("balance = balance - 200")
.in("id" , ids);
userMapper.update(null , wrapper);
}
小结
- QueryWrapper和LambdaQueryWrapper通常用来构建select、delete、update的where条件部分
- UpdateWrapper和LambdaUpdateWrapper通常只有在set语句比较特殊才使用
- 尽量使用LambdaQueryWrapper和LambdaUpdateWrapper,避免硬编码
自定义SQL
从条件构造器的学习中可以看出,虽然MybatisPlus提供了非常灵活的关于Where条件的SQL语句拼接方式,但是它是在业务逻辑层完成的,违背了企业开发的一些规范,如果不使用的话自己在xml文件中编写完整的SQL语句又会很麻烦。因此,我们可以利用MyBatisPlus的Wrapper来构建复杂的Where条件,然后自定义SQL语句中剩下的部分。我们需要想一种办法把mp构建好的条件往下传递给mapper层,在xml中最终实现SQL语句的组装。
步骤:
1.基于Wrapper构建where条件
UserMapperTest.java
@Test
void testCustomSqlUpdate() {
//1.更新条件
List<Long> ids = List.of(1L , 2L , 4l);
int amount = 200;
//2.定义条件
QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id" , ids);
//3.调用自定义SQL方法
userMapper.updateBalanceByIds(wrapper, amount);
}
2.在mapper方法参数中用Param注解声明wrapper变量名称,必须是ew
UserMapper.java
void updateBalanceByIds(@Param("ew") QueryWrapper<User> wrapper, @Param("amount") int amount);
3.自定义SQL,并使用Wrapper条件
UserMapper.xml
<update id="updateBalanceByIds">
UPDATE tb_user SET balance = balance - #{amount} ${ew.customSqlSegment}
update>
Service接口
Service接口类似于BaseMapper接口,包含了一些基本的增删改查的代码,跟BaseMapper相比,只多不少。
基本用法
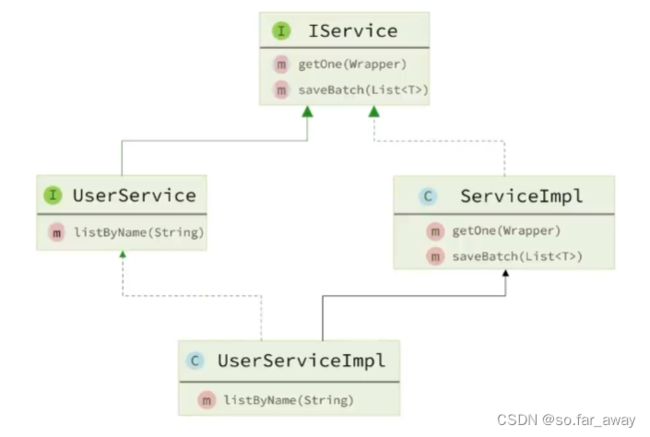
自定义接口需要实现IService接口,自定义实现类需要继承IService的实现类ServiceImpl。
IUserService.java
public interface IUserService extends IService<User>{
}
UserServiceImpl.java
@Service
public class UserServiceImpl extends IServiceImpl<UserMapper, User> implements IUserService {
}
批量新增
IUserServiceTest.java
//方式一:普通for循环插入 提交了100000次网络请求
@Test
void testSaveOneByOne(){
long b = System.currentTimeMillis();
for(int i = 1; i <= 100000 ; i++ ){
userService.save(builderUser(i));
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}
//方式二:IService的批量插入 每次批量插入1000条数据 插入100次即10万条数据
@Test
void testSaveBatch(){
//1.准备一个容量为1000的集合
List<User> list = new ArrayList<>(1000);
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000 ; i++){
//2.添加一个user
list.add(buildUser(i));
//3.每1000条批量插入一次
if (i % 1000 == 0){
userService.saveBatch(list);
//4.清空集合 准备下一批数据
list.clear();
}
}
}
方式二相较于方式一,采用的是批处理的方式,速度快了近十倍,方拾贰需要向网络请求100次,但是由于在预编译的过程中,每次的1000条数据是被编译成了1000条SQL语句,所以MySQL在执行的过程中就是逐条执行的,所以方式二仍然有改进空间,可以通过配置jdbc参数,在application.yaml的url后面拼接上一个参数rewriteBatchedStatements=true,开启该参数之后,相当于把100000条插入语句变成了一个包含了100000条插入值的语句,只需要执行一次,速度上会快很多,这才是真正意义上的批处理。