【计算机图形学】Few-Shot Physically-Aware Articulated Mesh Generation via Hierarchical Deformation
文章目录
- 1. 为什么要提出这个工作
- 2. 之前的工作(Privous Work)
-
- 网格生成模型
- Few-shot生成
- 物理感知的机器学习
- 3. Pipeline
-
- Overview
- 分层网格变形
- 物理感知的变形校正
- 4. 实验
-
- 评价指标
- 定性实验
- 5. 限制
- 6. 其他补充
-
- 关于什么是few-shot
- 重心坐标内插矩阵
1. 为什么要提出这个工作
作者观察到,之前的铰接物体生成模型存在两个问题:
- 一个是生成出来的铰接物体缺乏创新性(缺乏一种通过少量数据来学习广泛数据空间的能力)
- 通过生成模型得到的铰接物体,往往无法确保其物理性质是合理的(也就是生成出来的铰接物体违反物理性质/规律)
针对这两个存在的问题,作者想要做的事情是:通过观察涵盖少量示例的铰接物体数据集(目前比较火的Few-shot learning),进一步地生成更加多样化的mesh,同时使得这些生成的mesh在视觉上保真、物理上合理。
为了解决这两个存在的问题,并达到目标,作者在Abstract中引出了他的key innovations:
- 基于分而治之的哲学理论,建立一个分层次的基于变形的mesh生成模型。也就是将一个完整的铰接物体分成多个部件(分),从而进一步为Few-shot learning提供了可能。同时通过将大规模刚性mesh范式转移到这些部件上(治),来实现部件的变形(PS: 后面这一步,是因为在分的那步中,作者观察到,部件级别的mesh几乎都共享了相同的变形范式,这个范式可以直接从具有丰富数据的大规模刚性数据集迁移而来,学习这种基于大规模数据得到的生成能力)
- 通过一个物理感知的变形校正框架,来保证物理上合理的生成
2. 之前的工作(Privous Work)
网格生成模型
直接表面生成,这种生成方式的显式优点是合成高质量的n边形网格,但它们通常受限于其生成能力,且无法将其生成能力拓展到一些复杂物体上。
基于变形的网格生成,受限于较低的自由度。
基于混合表示的生成将网格表面结构生成问题从内容生成中分离出来。但是生成结果的质量仍与表面重建技术相关。
文章将采用基于变形的网格生成,与以往直接变形整个物体或物体部件不同,作者设计了一种分层变形策略,通过大规模刚性网格中跨类别共享的变形模式来增强变形的灵活性。
Few-shot生成
这种生成的目标是仅通过新类别较少的案例来创造内容、语义上与目标类别保持一致的更多数据。
在这篇文章中,作者利用迁移学习使得目标铰接类别能够适应大规模刚性数据集的shape范式。
设计这种迁移学习方法需要找到正确的intermediates,使得网络能够跨类别迁移的shape范式,作者在这里选择convexes作为这种intermediateates。
物理感知的机器学习
生成物理上合理的铰接物体这个问题可以被视作在网格生成的过程中,需解决网格自交的问题。文章的策略是使用物理监督和形状优化策略。
3. Pipeline
问题的目标是:few-shot的物理感知铰接网格生成。给定一组感兴趣类别的铰接网格,方法能够学习到一个条件生成模型,该生成模型能够将铰接网格变形成相同类别的多样化形状。
想要达到这个目标要解决的两个挑战如1中所说:
- 如何从少量的例子中精确地表示复杂的shape变形空间?
- 如何确保生成的网格支持物理真实的铰接?
为了解决这两个挑战:
针对第一个问题,文章的想法是借用其他类别物体的知识来学习变形空间。这个想法是不平凡的,因为作者需要找到哪些知识是跨类别、可迁移的。进一步地,文章提出了分层网格变形策略,允许在local convexes segement level来迁移变形先验,同时保持整体shape的变形一致性
针对第二个问题,文章的想法是引入物理感知的变形校正框架,以避免在网格铰接过程中出现一些不想要的artifacts,如自交等。
Overview
完整Pipeline
给定一组感兴趣类别的、具有相同部件和铰接的、数量较少的铰接物体集合 A A A,文章想要去描绘多样化且可信的铰接形状空间。
文章运用分而治之的哲学,采用分层变形框架,结合迁移学习来解决few-shot生成问题。
首先,让生成模型学会在lowest convex level上描绘一个多样化的形状空间。这一步借用了从大规模刚性网格数据 B B B中学习的生成范式。
其次,设计一个合成策略,能够将变形后的convex一致的组合成一个合理的shape。
最后则是运用一个物理感知的校正框架来解决一些物理上不自然的现象,如自交问题。
更细节地说
首先,将网格a分割成convex集合 C a C_a Ca,构建object-convex的分层框架。
然后,在叶子层,将每一个属于convex集合 C a C_a Ca的convex c c c通过一个条件生成模型 g C ( z c ∣ c ) g_C(z_c|c) gC(zc∣c),得到一个变形后的结果。这里的z_c是对应于convex c c c的一个噪声参数。
最后,在root-level上合成这些变形后的结果。将噪声参数 z c z_c zc使用 S c z S_cz Scz进行替代, S c S_c Sc是一个线性变形, z z z是一个所有convex共享的合成噪声参数,通过对齐不同convex的噪声空间,构建整个网格的变形。
g ( z ∣ a ) = { g C ( S c z ∣ c ) ∣ c ∈ C a } g(z|a)=\{g_C(S_cz|c)|c∈C_a\} g(z∣a)={gC(Scz∣c)∣c∈Ca}
训练流程
在训练过程中,首先使用BSP-Net来将A和B分割成convex segements C A C_A CA和 C B C_B CB。接着在 C B C_B CB上训练convex-level的条件生成模型 g C ( z c ∣ c ) g_C(z_c|c) gC(zc∣c),让生成模型学会如何去做变形,最后在 C A C_A CA上微调预训练模型,同时估计噪声合成迁移 S C S_C SC。同时利用物理感知的变形校正框架(一个辅助loss惩罚自交的情况以提供物理监督,一个基于碰撞的形状优化策略鼓励模型学习物理真实的网格。前者仅在测试中作为loss辅助训练,后者作为一种优化框架在训练和测试中共同使用)
分层网格变形
整体网格变形等于网格的convex集合逐个变形的集合: g ( z ∣ a ) = { g C ( S c z ∣ c ) ∣ c ∈ C a } g(z|a)=\{g_C(S_cz|c)|c∈C_a\} g(z∣a)={gC(Scz∣c)∣c∈Ca}
给定一个网格 a a a,分割后,通过convex-level的生成模型 g C g_C gC合成新的convex shapes,运用变形同步策略进一步处理变形不一致的问题,进而构建合理的物体。
Convex-level的条件生成模型(可以视作一种减少训练参数的优化)
为了简化计算,这里受到了其他一些论文的启发,对于convex c c c,使用一个粗糙的三角形网格(称为cage) t c t_c tc来包住convex c c c,进一步计算。 t c t_c tc相较于 c c c有更少的顶点,会更容易建模。convex c c c的变形 d c d_c dc只需要通过 d t c d_{t_c} dtc进行计算: d c = Φ c d t c d_c=Φ_cd_{t_c} dc=Φcdtc,其中Φ_c是基于重心坐标的内插矩阵。
为了进一步减少变形参数,cage的变形 d t c d_{t_c} dtc是通过一组K个变形基 B c = [ b c 1 . . . b c k ] B_c=[b_c^1...b_c^k] Bc=[bc1...bck]的线性连接来表示的: d t c = B c z c d_{t_c}=B_cz_c dtc=Bczc,这里 z c z_c zc是一个K维度的变形系数。
few-shot变形学习范式(网络通过迁移学习来增加变形的多样性)
对于每一个convex c c c变形的学习,根据Convex-level的条件生成模型中介绍的参数简化方式,这里实际上就变成了一组变形基 B c B_c Bc以及变形系数 z c z_c zc的学习。变形基通过 ψ θ ( ⋅ ) ψ_θ(·) ψθ(⋅)学习,有 B c = ψ θ ( c ) B_c=ψ_θ(c) Bc=ψθ(c),变形系数通过对应可用的数据集进行优化。
同时在这里应用了迁移学习,convex-level的变形都是类似的,比如条形的东西变粗/变细等。
在 B B B上预训练生成模型,优化变形系数集 z c c ^ ∣ c , c ^ ∈ B {z^{\hat{c}}_c|c,\hat{c}∈B} zcc^∣c,c^∈B和神经网络 ψ θ ( ⋅ ) ψ_θ(·) ψθ(⋅),这里的 { ( c , c ^ ) ∣ c , c ^ ∈ B } \{(c,\hat{c})|c,\hat{c}∈B\} {(c,c^)∣c,c^∈B},是使用无监督联合分割算法提前配对的。这里的优化策略是,fix B c {B_c} Bc,优化 z c c ^ z^{\hat{c}}_c zcc^;然后fix z c c ^ z^{\hat{c}}_c zcc^,优化 B c {B_c} Bc,通过Chamfer Distance作为监督。最后在 A A A上fine-tune
Convex变形同步(解决分convex下变形不一致的问题)
将变形后的convex c c c重新组合成完整的mesh a a a。由于每个convex都有自己的一组变形基 B c B_c Bc和变形参数,所以最后的变形结果很容易彼此矛盾,导致mesh-level的变形失败。为了解决这个问题,作者提出使用线性变换 S c S_c Sc来同步不同的变形基 B c B_c Bc,进一步使得单个噪声参数可以被所有的convexes所共享。
原本生成模型是 g C ( z c m ∣ c m ) g_C(z_{c_m}|c_m) gC(zcm∣cm),其中的参数是 z c m z_{c_m} zcm,且每一个convex的参数都是独立的。现在作者的目标是将这个每个convex都不同的参数 z c m z_{c_m} zcm替换成 S c m z S_{c_m}z Scmz,其中 z z z是一个全局一致的网格变形。
为了计算这个 S c m S_{c_m} Scm,对于每一个mesh a i a^i ai,为 a a a中的每个convex c m c_m cm都优化一组变形系数 { y m i } \{y^i_m\} {ymi} following g C ( z c m ∣ c m , z c m = y m i ) g_C(z_{c_m}|c_m,z_{c_m}=y^i_m) gC(zcm∣cm,zcm=ymi),接着通过解一个优化问题来获得同步transformations { S c m } \{S_{c_m}\} {Scm}

物理感知的变形校正
分层网格变形产生的结果会有物理上不真实的情况,为了解决这个问题,作者将网格 a a a的多个状态构建成了一个序列: S i m ( a ) = { a k } k = 1 K Sim(a)=\{a_k\}^K_{k=1} Sim(a)={ak}k=1K,并设计了如下的物理监督和shape优化策略。
物理监督
这一步设计了一种度量,叫做平均穿透深度(Average Penetration Depth,APD),衡量在铰接变换的过程中,每个顶点穿透其它部件的大小。即 L p h y = 1 K ∑ k = 1 K P e n e D ( a k ) L_{phy}=\frac{1}{K}\sum^{K}_{k=1}PeneD(a_k) Lphy=K1∑k=1KPeneD(ak),其中, P e n e D ( a k ) PeneD(a_k) PeneD(ak)测量了单个交接状态下的自穿透。
仅仅有这种物理监督,还是难以handle在铰接过程中多样化和复杂的物理不真实现象,所以进一步提出了一种基于碰撞反馈的shape优化策略
基于碰撞反馈的shape优化策略
设计了一种启发式的穿透解决策略,将穿透的点投影到mesh的表面。为了引导这个投影,设计了算法计算ProjD(a),为网格 a a a中每一个穿透的顶点a求导,进而学习如何投影以解决自交问题。每个交接状态下的 P r o j D ( a k ) ProjD(a_k) ProjD(ak)被视作一个loss: L p r o j = 1 K ∑ k = 1 K P r o j D ( s i m k ( a ) ) L_{proj}=\frac{1}{K}\sum^{K}_{k=1}ProjD(sim_k(a)) Lproj=K1∑k=1KProjD(simk(a)),通过迭代使用这个loss来更新网格的全局变形系数 z z z以减少 a a a的自交
4. 实验
评价指标
Minimum matching distance(MMD):评估生成样例的保真度
Coverage(COV):评估生成样例的多样性
1-NN classifier accuracy(1-NNA):基于Nearest Neighbor来分类shape属于“reference”类还是“training”类
Jenson-Shannon divergence(JSD):计算生成样例和参考样例之间的相似性
Average penetration depth(APD):文章自己提出的,用于评估自交深度
定性实验
自由变形
目标驱动的变形
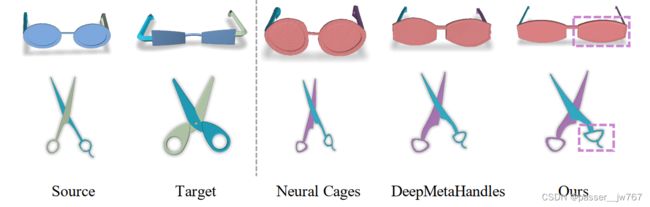
5. 限制
本篇工作是category-level的工作,并假设已知articulation chain和articulation states的状态。开发一种不需要这种假设的生成方法可以进一步增加实用价值。
变形校正框架依赖于手工设计的关节状态链来检测自穿透,并在这个基础上优化形状,一种自然的替代方法是从真实世界图像中得到铰接状态。
目前,本篇工作的生成结果质量受到训练数据的质量限制,除减轻自我渗透外还可以设计一种智能的自我纠正策略进一步提高有效性。
6. 其他补充
关于什么是few-shot
我找到了一篇参考性比较高的文章:【计算机视觉】Zero-shot, One-shot和Few-shot的理解。根据我从这篇文章中得到的理解,few-shot应该是用少量的数据,让网络学到这一个数据类别的一些特征/性质。也就是对于要处理的对象,仅需少量的样本进行学习。
重心坐标内插矩阵
参考Games101计算机图形学入门(8)shader ——插值、高级纹理映射,里面介绍了重心坐标及意义
重心坐标其实就是可以理解为三角形的中心点。假如我们知道三角形顶点属性,为了实现三角形内部进行平滑过渡,就可以通过求重心坐标实现。