动手学大模型应用开发-第二章 调用大模型API
导航概览
- 如何调用大语言模型的API?
-
- 1、调用参数
- 2、API申请
- 3、实践
-
- 3.1 仓库代码拉取
- 3.2、百度文心
- 3.3、OpenAI
- 3.3、讯飞星火
-
- 3.3.1、直接调用
- 3.3.2、本地端口服务调用
- 3.4、智谱
-
- 3.4.1、问答调用
- 3.4.2、智谱Embedding
- 4、次数限制
- 5、其他ChatGPT网站
-
- 5.1、爬虫方式请求Poe并获取结果
-
- 5.1.1、安装插件
- 5.1.2、导出Cookies
- 5.1.3、下载chromedriver
- 5.1.4、简易爬虫代码
- 6、总结
如何调用大语言模型的API?
百闻不如一见,百见不如一试,这一章主要学习如何调用现有大模型的API。
1、调用参数
调用大语言模型的API,相当于调用已经写好的函数,我们只需要结合我们的实际需求进行包装一下(也就是学会用哪些参数去调用就行)。
model,即调用的模型,一般取值包括“gpt-3.5-turbo”(ChatGPT-3.5)、“gpt-3.5-16k-0613”(ChatGPT-3.5 16K 版本)、“gpt-4”(ChatGPT-4)。注意,不同模型的成本是不一样的。
message,即我们的 prompt。ChatCompletion 的 message 需要传入一个列表,列表中包括多个不同角色的 prompt。我们可以选择的角色一般包括 system:即前文中提到的 system prompt;user:用户输入的 prompt;assitance:助手,一般是模型历史回复,作为给模型参考的示例。
temperature,温度。即前文中提到的 Temperature 系数。
max_tokens,最大 token 数,即模型输出的最大 token 数。OpenAI 计算 token 数是合并计算 Prompt 和 Completion 的总 token 数,要求总 token 数不能超过模型上限(如默认模型 token 上限为 4096)。因此,如果输入的 prompt 较长,需要设置较小的 max_token 值,否则会报错超出限制长度。
2、API申请
DataWhale大语言学习网站有具体的 API申请教程 大家跟着操作即可。
3、实践
3.1 仓库代码拉取
代码仓库为:llm-universe,按照流程创建虚拟环境 conda + python3.8。
3.2、百度文心
import requests
import json
import time
# import os
# # 如果你需要通过代理端口访问,你需要如下配置
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:1080'
# os.environ["HTTP_PROXY"] = 'http://127.0.0.1:1080'
def get_access_token():
api_key = "*****"
secret_key = "*****"
url = f"https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}"
# 设置 POST 访问
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
# 通过 POST 访问获取账户对应的 access_token
response = requests.request("POST", url, headers=headers, data=payload)
print(response.json())
return response.json().get("access_token")
# 一个封装 Wenxin 接口的函数,参数为 Prompt,返回对应结果
def get_completion_weixin(prompt, temperature = 0.1, access_token = ""):
'''
prompt: 对应的提示词
temperature:温度系数
access_token:已获取到的秘钥
'''
url = f"https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={access_token}"
# 配置 POST 参数
payload = json.dumps({
"messages": [
{
"role": "user",# user prompt
"content": "{}".format(prompt)# 输入的 prompt
}
],
"temperature" : temperature
})
headers = {
'Content-Type': 'application/json'
}
time.sleep(3)
# 发起请求
response = requests.request("POST", url, headers=headers, data=payload)
# 返回的是一个 Json 字符串
js = json.loads(response.text)
print(js)
return js["result"]
if __name__ == "__main__":
access_token = get_access_token()
prompt = f"Given the sentence, assign a sentiment label from ['positive', 'negative', 'neutral']. Sentence: Ok, first assesment of the #kindle2 ...it fucking rocks!!! Return label only without any other text."
ans = get_completion_weixin(prompt=prompt, access_token=access_token)
print(ans)
3.3、OpenAI
注意在 .env文件里设置自己的openai key。
import os
import openai
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,你需要如下配置
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:1080'
os.environ["HTTP_PROXY"] = 'http://127.0.0.1:1080'
# 获取环境变量 OPENAI_API_KEY
openai.api_key = os.environ['OPENAI_API_KEY']
# 一个封装 OpenAI 接口的函数,参数为 Prompt,返回对应结果
def get_completion(prompt, model="gpt-3.5-turbo", temperature = 0):
'''
prompt: 对应的提示词
model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT) / text-davinci-003 ,有内测资格的用户可以选择 gpt-4
'''
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # 模型输出的温度系数,控制输出的随机程度
)
# 调用 OpenAI 的 ChatCompletion 接口
print(response.choices[0].message["content"])
return response.choices[0].message["content"]
if __name__ == "__main__":
get_completion(prompt="你好")

3.3、讯飞星火
先拷贝一些文件,以便好调用。

3.3.1、直接调用
import SparkApi
#以下密钥信息从控制台获取
appid = "****" #填写控制台中获取的 APPID 信息
api_secret = "****" #填写控制台中获取的 APISecret 信息
api_key = "****" #填写控制台中获取的 APIKey 信息
#用于配置大模型版本,默认“general/generalv2”
domain = "general" # v1.5版本
# domain = "generalv2" # v2.0版本
#云端环境的服务地址
Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
def getText(role, content, text = []):
# role 是指定角色,content 是 prompt 内容
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
if __name__ == "__main__":
prompt = f"Given the sentence, assign a sentiment label from ['positive', 'negative', 'neutral']. Sentence: Ok, first assesment of the #kindle2 ...it fucking rocks!!! Return label only without any other text."
question = getText("user", prompt)
print(question)
response = SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question)
print(response)

3.3.2、本地端口服务调用
命令行1先运行:uvicorn spark_api:app

# cmd-> uvicorn spark_api:app
import requests
def get_completion_spark(prompt, temperature = 0.1, max_tokens = 4096):
api_url = "http://127.0.0.1:8000/spark"
headers = {"Content-Type": "application/json"}
data = {
"prompt" : prompt,
"temperature" : temperature,
"max_tokens" : max_tokens
}
response = requests.post(api_url, headers=headers, json=data)
print("response:", response)
print()
print()
return response.text
if __name__ == "__main__":
ans = get_completion_spark("你好")
print(ans)

3.4、智谱
先拷贝一些文件,以便好调用。

3.4.1、问答调用
import zhipuai
from zhipuai_llm import ZhipuAILLM
zhipuai.api_key = "******" #填写控制台中获取的 APIKey 信息
model = "chatglm_std" #用于配置大模型版本
def getText(role, content, text = []):
# role 是指定角色,content 是 prompt 内容
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
if __name__ == "__main__":
# question = getText("user", "你好")
# print(question)
# # 请求模型
# response = zhipuai.model_api.invoke(
# model=model,
# prompt=question
# )
# print(response)
zhipuai_model = ZhipuAILLM(model="chatglm_std", temperature=0, zhipuai_api_key=zhipuai.api_key)
response = zhipuai_model.generate(['你好'])
print(response)

3.4.2、智谱Embedding
import zhipuai
zhipuai.api_key = "*****" #填写控制台中获取的 APIKey 信息
model = "text_embedding" #选择调用生成 embedding 的模型
if __name__ == "__main__":
text = "要生成 embedding 的输入文本,字符串形式。每个输入不得超过模型的最大输入tokens数量512"
response = zhipuai.model_api.invoke(
model=model,
prompt=text
)
print("response: ", response)
print(response['code'])
print(f"生成的 embedding 长度为: {len(response['data']['embedding'])}")
print(f"用户输入的 tokens 数量为: {response['data']['usage']['prompt_tokens']}")
print(f"用户输入的文本长度为: {len(text)}")
print(f"本次 token 和字数的换算比例为: {response['data']['usage']['prompt_tokens']/len(text)}, 和理论值 1:1.8 = {1/1.8} 接近")
print(f"模型输出的 tokens 数量为: {response['data']['usage']['completion_tokens']}")
print(f"总 tokens 数量为: {response['data']['usage']['total_tokens']}")

4、次数限制
没有马内之前,针对OpenAI,ChatGpt的调用次数限制,目前要求每分钟不能调用超过3次,每天要求调用不能超过200次。但是又要完成多轮预测任务,可以参考代码和数据格式,从而能完成多轮预测,这个代码主要解决了请求重试问题。
5、其他ChatGPT网站
Poe提供国外各个大语言模型的聊天窗口。
5.1、爬虫方式请求Poe并获取结果
5.1.1、安装插件
Chrome 浏览器,安装EditThisCookies插件

5.1.2、导出Cookies
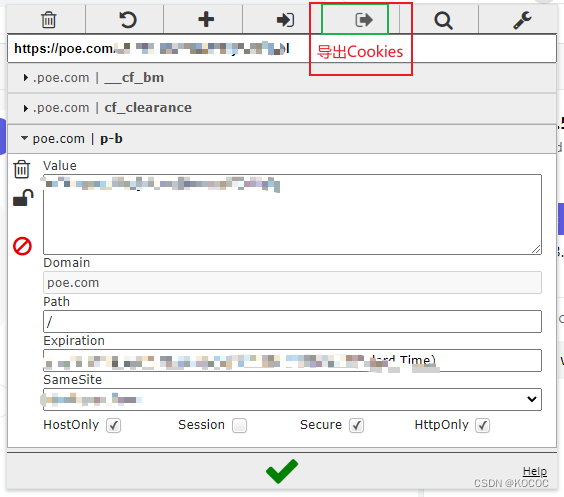
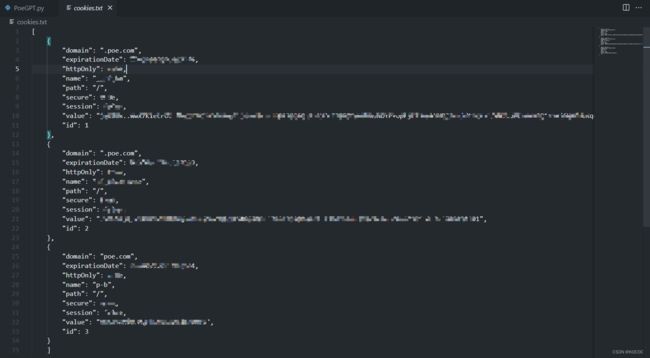
将粘贴板上的cookies粘贴到cookies.txt文件中。每一项只保留这些字段(“domain”、“expirationDate”、“httpOnly”、“name”、“path”、“secure”、“session”、“value”、“id”)以及对应值,其余字段删除。
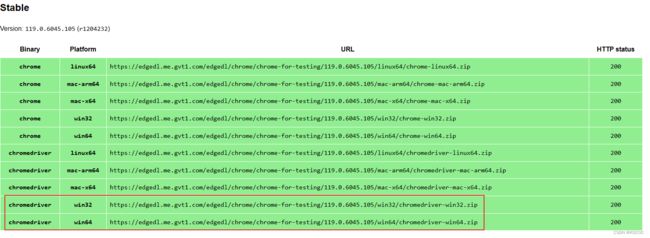
5.1.3、下载chromedriver
chrome://settings/help 查看 浏览器版本。

117/118/119版本通过点击进入到Chrome for Testing availability,
5.1.4、简易爬虫代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import os
import json
import time
import pandas as pd
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:1080'
os.environ["HTTP_PROXY"] = 'http://127.0.0.1:1080'
def query_sentiment():
label_space = ["positive", "negative", "neutral"]
cls_task = f"Given the sentence, assign a sentiment label from {label_space}."
cls_output = "Return label only without any other text."
df = pd.read_csv("test.csv")
text = df['text'].to_list()
prompts = [(cls_task + " Sentence: " + ele +" "+ cls_output) for ele in text]
return df, prompts
def main():
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(executable_path="./chromedriver/chromedriver.exe", options=option)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
# 访问链接地址
# driver.get("https://poe.com/chat/************")
driver.get("https://poe.com/chat/***************")
# 添加cookies
with open('cookies.txt','r') as cookief:
cookieslist = json.load(cookief)
print(cookieslist)
for cookie in cookieslist:
driver.add_cookie(cookie)
# 刷新页面
driver.refresh()
# 页面下方的聊天窗口元素
footer = driver.find_element(by=By.CLASS_NAME, value="ChatPageMainFooter_footer__HBGcX")
# print(footer)
button = footer.find_element(by=By.CLASS_NAME, value="ChatMessageInputContainer_sendButton__dBjTt")
# print(button)
input = footer.find_element(by=By.CLASS_NAME, value="GrowingTextArea_textArea__ZWQbP")
# print(input)
df, prompts = query_sentiment()
predictions = []
for prompt in prompts:
time.sleep(6)
# 页面上可能存在之前的聊天记录
init_ZEXUz = len(driver.find_elements(by=By.CLASS_NAME, value="ChatMessagesView_messagePair__ZEXUz"))
input.send_keys(prompt)
button.click()
time.sleep(12)
curr_ZEXUz = driver.find_elements(by=By.CLASS_NAME, value="ChatMessagesView_messagePair__ZEXUz")
if len(curr_ZEXUz) - init_ZEXUz == 1:
xkgHx = curr_ZEXUz[-1].find_elements(by=By.CLASS_NAME, value="ChatMessage_chatMessage__xkgHx")
if len(xkgHx) == 2:
the_ans = xkgHx[-1].find_element(by=By.CLASS_NAME, value="Markdown_markdownContainer__Tz3HQ").text
print(prompt + "\nAnswer: " + the_ans)
print()
else:
exit
df["prediction"] = predictions
df["prompt"] = prompts
output_path = "prediction.csv"
df.to_csv(output_path, index=False)
if __name__ == '__main__':
main()
6、总结
学习了国内外不同的大模型API的调用方式,同时基于Poe聊天界面开发一个小的爬虫问答应用,但是Poe的聊天界面也有轮次限制,基于爬虫的方式是高度定制的,针对每个聊天窗口是不太现实的,但是最起码可以自动化问答了,有助于利用大模型进行预测任务的完成。