Go语言高并发系列一:基础理论
Go语言的一个核心优势就是它的并发能力。但是在实际工作中,有很多小伙伴还不能纯熟的掌握Go语言的并发和goroutine的控制,导致有时候会出现一些性能问题和严重的bug。
所以我准备写四篇文章来系统的整理一下Go语言并发相关的知识,自己复习的同时,也可以给公司的其他小伙伴巩固一下,顺便介绍一下我封装的一些并发控制器,方便其他小伙伴使用。
闲话不多说了,下面进入正题。
我打算写总共四篇文章来梳理Go语言并发的核心知识:
- 基础理论
- Go语言并发基础
- context
- 并发模式
进程
进程的定义
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。 程序是指令、数据及其组织形式的描述,进程是程序的实体
进程池
比如PHP在做后端开发的时候,在部署时一般会采用 NGINX + PHP-FPM的架构。
这种架构就是以进程池的形式来进行并发。
进程池一般由两部分组成:master 和 worker
master进程主要管理事件信号的接受与任务分配,创建新的worker进程,回收空闲的worker进程
worker进程就是勤劳的打工人,埋头苦干由master分配的任务。
这种并发的方式属于简单粗暴+稳定可靠,进程之间天然的相互隔离,某一个进程崩溃也不会影响其他进程的运行。
但是进程的创建和销毁消耗的系统资源会比较多,进程间通信也会比较麻烦。
线程
线程的定义
线程是操作系统能够进行调度的最小单位,大部分情况下,它是被包含在进程中。一条线程是指进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并发执行不同的任务。
同一进程中的多条线程将共享该进程中的全部系统资源,比如虚拟地址空间、文件描述符、信号处理等。但是同一进程的多条线程有各自的调用栈、寄存器、线程本地存储。
线程池
线程过多会带来额外的开销,包括创建和销毁线程的开销,调度线程的开销等。所以采用多线程并发时,一般会使用线程池来维护多个进程,等待任务分配。
线程池的实现一般是生产者消费者模型,由生产者、任务队列、消费者三部分组成。
生产者:生产工作任务并存入任务队列
消费者:从任务队列取出任务进行处理,如果任务队列没有任务,就进入挂起状态
线程池的数量控制一般由两步分组成,核心线程和非核心线程。核心线程在线程池启动时就进行创建,并且长期存在,无限期的等待任务。非核心线程则是当任务数量超出核心线程负荷时,进行创建,如果执行完任务后一段时间内没有新的任务,就回收掉。
线程控制主要需要注意:
- 创建太多线程,将会浪费一定的资源,有些线程未被充分使用。
- 销毁太多线程,将导致之后浪费时间再次创建它们。
协程
协程的定义
协程,英文叫作 Coroutine,协程是一种用户态的轻量级线程。
协程拥有自己的上下文和栈,协程调度切换的时候,将寄存器上下文和栈保存下来,在切回来的时候,又恢复之前保存的上下文和栈。所以协程可以保留上一次执行时的状态,即局部状态的一个特定组合,每次切换回来时就相当于进入上次调用的状态。
协程本质上是在单线程内运行,在线程内进行切换。
阻塞与非阻塞
阻塞:阻塞状态是指程序未得到所需计算资源时,被挂起的状态,程序在等待某个操作完成,自身无法继续处理其他事情。
常见的阻塞有:网络IO阻塞,磁盘IO阻塞等
非阻塞:非阻塞是指程序在等待期间,仍然可以继续处理其他事情。阻塞操作会导致耗时和效率低下,变成非阻塞一般可以提高效率。
同步与异步
同步:不同的程序单元为了完成某个任务,有序的依次执行,称为同步执行。比如更新数据库的一条数据,对行加锁使得不同的更新请求依次排队执行,就是同步操作。
异步:为了完成某个任务,不同的程序单元之间无需协同,一个程序单元的执行不需要等待另一个程序单元执行完毕,就是异步操作。
比如程序执行的操作日志,当程序需要记录日志时,可以将日志信息丢给日志程序去保存,而它本身不需要等待日志程序保存完成,就可以继续执行其他操作了。
小结
我们到现在为止了解了大量的概念,其实这些概念的出现,都是为了提高效率,为了更高效的利用系统资源。
为了更高效的利用系统资源,我们就要让程序尽量以非阻塞的形式异步运行。
例如:我们服务器向外发送一个http请求,这之间会有较长一段时间的网络IO阻塞。这个时候我们就可以把它挂起,去做其他的事情,等到响应返回,再来继续处理。
这种情况下程序就以异步非阻塞的方式运行,大大提高了执行效率,充分利用了cpu的计算能力。
goroutine
现在开始讲我们今天的重点:goroutine。
goroutine是Go语言的一种机制,是Go语言中协程的实现。Go语言会智能地将goroutine中的任务合理的分配给cpu,因为它在语言层面已经内置了调度和切换上下文的机制。
在Go语言中,当我们需要某个任务并发执行的时候,只需要将任务包装成一个函数,开启一个goroutine去执行就可以了。
栈
goroutine的栈在生命周期开始的时候只有很小的容量,一般情况下是2kb。但goroutine栈的大小是不固定的,可以根据需要增大和缩小。所以在Go语言中一次创建十万的goroutine也是没问题的。
GPM
GPM是Go语言自己实现的一套调度系统
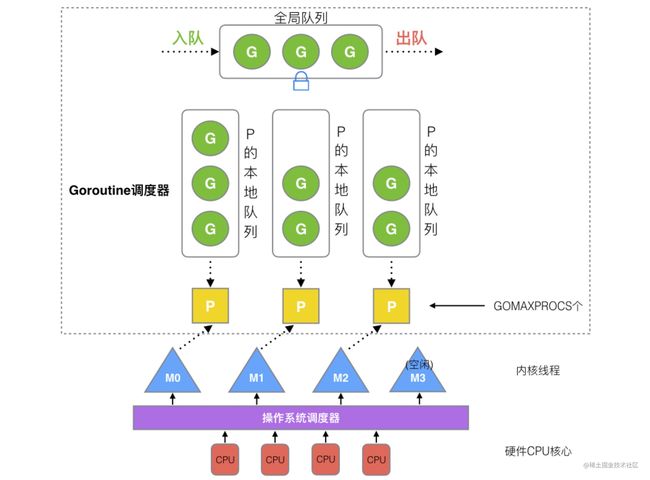
首先有一个全局队列,里面存放着待运行的goroutine
- P 管理着一组goroutine队列,容量有限,只能放256个。新建G时会优先放入P的队列,如果队列满了就会把队列的一半放入全局队列。
- P 里面会存储当前G的上下文环境(函数指针、堆栈地址、地址边界),P会对自己管理的G队列进些调度,当自己队列消费完了,就去全局队列里取。如果全局队列也消费完了,就去其他P里抢任务。
- M 是Go的runtime对操作系统内核线程的虚拟,M与内核线程一般一一对应。P管理的G会在M上运行,然后OS调度器会把内核线程分配到CPU执行。
P的个数
- P的数量由启动时的$GOMAXPROCS环境变量,或者由runtime的方法GOMAXPROCS()决定。
- Go1.5以后默认的GOMAXPROCS数量是物理线程数
M的个数
- M的最大数量限制默认是10000,但是内核一般很难支持这么多。
- runtime/debug中的SetMaxThreads函数,可以设置M的最大数量
- M的数量是不固定的,当一个M阻塞住,P就会换一个M或者创建一个新的M。所以就算P的数量是1,也可能会创建很多个M。
GPM可视化
要查看GPM的运行情况,我们可以通过: go tool trace
下面让我们来简单测试一下:
package main
import (
"os"
"runtime/trace"
"sync"
)
func run(wg *sync.WaitGroup) {
wg.Add(1)
go gofun(wg)
}
func gofun(wg *sync.WaitGroup) {
defer wg.Done()
n := 1
for i := 0; i < 100000; i++ {
n += 1
}
}
func main() {
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
var wg sync.WaitGroup
run(&wg)
run(&wg)
run(&wg)
run(&wg)
wg.Wait()
}
首先运行程序:
$ go run main.go
此时会得到一个trace.out文件,我们用go tool trace 来打开它
$ go tool trace trace.out
2022/04/12 11:12:58 Parsing trace...
2022/04/12 11:12:58 Splitting trace...
2022/04/12 11:12:58 Opening browser. Trace viewer is listening on http://127.0.0.1:51019
现在我们打开浏览器,访问http://127.0.0.1:51019 ,点击view trace就可以看到我们刚才运行程序时,GPM的调度情况了。
概览

G信息
点击Goroutines这一行,任一时间段,就可以看到详细信息。
比如我们现在点击100μs这个时间:
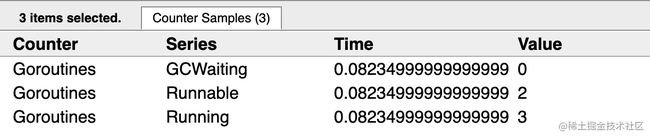
详细信息里,第一行是一个特殊的G,是每个M必须有的一个初始化的G,这个我们不必讨论。
我们可以看到有3个G正在运行中
P信息
P这里我们可以看到,一共有6个G被3个P分别调度运行

M信息
M这里我们可以看到,随着P的调度,M的数量会增加和减少
![]()
总结
从线程调度上来讲,一般语言是由OS内核直接进行线程调度,而Go的gorountine是有Go自己的调度器进行调度,这种调度是在用户态完成的,不涉及内核的频繁切换。
包括内存的分配,也是在用户态维护者一块大的内存池,不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。
另一方面充分利用了多核的硬件资源,近似把若干goroutine均分到物理线程上。
再加上本身goroutine也很轻量,各方面来讲保证了Go的并发性能。