NAS入门(学习笔记)
文章目录
- AutoML
- NAS
-
- 初期NAS
- 当前NAS框架
-
-
- One-Shot NAS
- 权重共享策略
- Zero-Shot NAS
-
- Zen-NAS
- NASWOT
- EPENAS
-
- 参考资料

AutoML
深度学习使特征学习自动化
AutoML 使深度学习自动化
自动化机器学习 (automated machine learning) 是一种自动化的数据驱动方法, 并做出一系列决策。
按模型类型划分,分为以下两类:

Classical ML:传统机器学习模型的自动化学习,包括基础算法的选择和超参数优化以及机器学习pipeline的自动合成等。
NAS:神经网络架构搜索 (Neural Architecture Search,NAS)是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
NAS
NAS 是 AutoML子领域,是一种搜索最佳神经网络结构的方法。
2017年 nas 出现
2018 NAS开始流行
2019 2020更加成熟 成为标准技术
根据专家预先定义的搜索空间 (search space), 神经结构搜索算法在一个庞大的神经网络集合中评估 结构性能并寻找到表现最佳的网络结构。
自动化结构搜索的结果往往是专家手工设计过程中未考虑的, 能够取得 更加优异的性能表现, 尤其在一些硬件资源受限的应用场景中, NAS 往往能取得惊人的效果。
神经结构搜索在超 参数选择的过程中扮演着关键角色, 而且具有重要的理论意义和应用价值。
面向一种特殊的神经网络结构超参数, 神经结构搜索联合优化理论和机器学习理论, 有效地解决神经网络模型的调参问题, 降低神经网络的使用成本与 实现成本, 促使模型设计的智能化与神经网络应用的大众化。
初期NAS
NAS 算法通常采用采样 重新训练的策略, 即从预先定义好的搜索空间中采样数量庞大的网络结构, 分别对每个采样
结构重新训练并评估 性能, 以获取表现最佳的神经网络。实验结果优越但十分耗费资源。
对于 Cifar-10 数据集, 这类方法需要应用 800 个GPU, 持续近一个月才能完成 对最佳结构的搜索。
因此, 这种采样重新训练策略对计算资源的需求过大, 不利于 NAS 领域的发展与落地应用

当前NAS框架
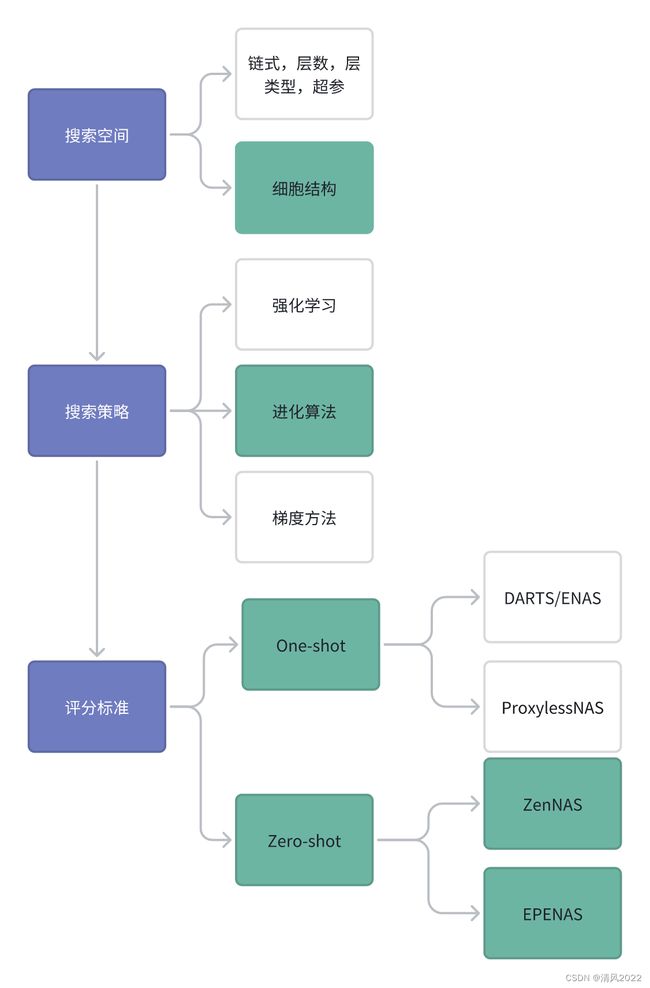
为了降低搜索阶段的资源消耗, 神经结构搜索领域内应用最广的一种加速方式:
One-Shot NAS
它训练一个大型超网,然后评估其内部子网的性能,以及在训练过程中预测模型最终性能
One-Shot NAS 有一个很大的特性就是:训练一次 Supernet,便可以针对各种不同的constraint,得到多种不同的 network。
One-Shot NAS可以分成两个阶段,分别是 training stage 和 searching stage:
-
Training stage:在这个阶段,并不会进行搜索,而是单纯训练 Supernet ,使得 Supernet 收敛至一定的程度。
当 Training stage 结束时, Supernet 中的参数就被训练收敛了,这个时候进入第二阶段。 -
Searching stage:从 Supernet 中不断取出 Sub-network,并使用 Supernet 的 weight 给Sub-network赋权重,这样就可以得到不同的Sub-network 的 validation accuracy,直到取得最好且符合 hardware constraint 的 Sub-network。
权重共享策略
权重共享策略(weight-sharing strategy)即尽可能地利用已经训练好的模型, 避免重新训练. 目前这种权重共享的搜索策略已经成为神经网络结 构搜索的主流方向。
简而言之, 首先将预先设定的搜索空间表示为已经训练好的超级网络 (super-network), 然后在 保留原始权重的同时, 直接对采样的子结构 (sub-architectures) 进行性能评估, 不需要重新进行模型训练。
Zero-Shot NAS
0样本学习
Zen-NAS
一个用于评估架构性能的零点指标。Zen-NAS使用Zen-Score作为评估架构准确性的代理,成功地探索了架构,比现有的NAS方法更快、更准确。Zen-Score是一个用于评估架构性能的Zero-Shot指标,包含两个主要建议

NASWOT
Paper
Code
EPENAS
受NASWOT启发搜索空间是NAS-Bench-201,数据集是CIFAR-10, CIFAR-100, ImageNet16-120
参考资料
华为学习资料
EPE-NAS
NASWOT