php jieba,laravel下TNTSearch+jieba-php实现中文全文搜索
上篇文章我们简单介绍了全文搜索的方案;
全文搜索和中文分词;
TNTSearch+jieba-php这套组合可以在不依赖第三方的情况下实现中文全文搜索;
特别的适合博客这种小项目;
我新建一个项目用于演示;laravel new tntsearch
创建一个文章表和文章模型;php artisan make:model Models/Article -m
添加文章标题和内容字段
/database/migrations/2018_05_27_020900_create_articles_table.php/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('articles', function (Blueprint $table) {
$table->increments('id');
$table->string('title')->default('')->comment('标题');
$table->mediumText('content')->comment('文章内容');
$table->timestamps();
});
}
修改 .env 数据库配置项;DB_DATABASE=homestead
DB_USERNAME=homestead
DB_PASSWORD=secret
运行迁移生成表;php artisan migrate
创建填充文件;php artisan make:seed ArticlesTableSeeder
生成测试数据;public function run()
{
DB::table('articles')->insert([
[
'title' => 'TNTSearch',
'content' => '一个用PHP编写的功能齐全的全文搜索引擎'
],
[
'title' => 'jieba-php',
'content' => '"结巴"中文分词:做最好的php中文分词、中文断词组件'
]
]);
}
运行填充;php artisan db:seed --class=ArticlesTableSeeder
/routes/web.php
use App\Models\Article;
Route::get('search', function () {
// 为查看方便都转成数组
dump(Article::all()->toArray());
});
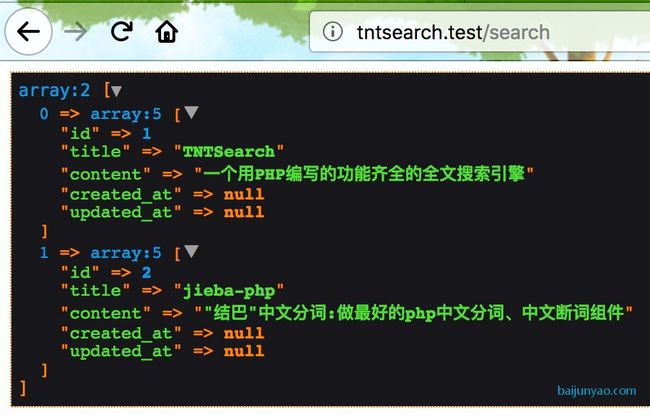
准备工作终于做完了;
另外因为依赖 SQLite 存储索引;
再确认下自己的 php 开启了以下扩展;pdo_sqlite
sqlite3
mbstring
现在开始正题;
以前;
我们需要自己 require scout;
scout 是 laravel 官方提供的用于全文搜索的扩展包;
它为我们提供了方便的命令行;
而且当我们增删改查文章后它会自动同步索引;
然后 require tntsearch 为 scout 提供的 laravel-scout-tntsearch-driver ;
再然后编写使用中文分词的逻辑;
现在有了 vanry 为我们造的轮子 laravel-scout-tntsearch ;
以前到现在这中间的步骤就可以省略了;
直接 require laravel-scout-tntsearch-driver ;composer require vanry/laravel-scout-tntsearch
添加 Provider ;
config/app.php'providers' => [
// ...
/**
* TNTSearch 全文搜索
*/
Laravel\Scout\ScoutServiceProvider::class,
Vanry\Scout\TNTSearchScoutServiceProvider::class,
],
中文分词 require jieba-phpcomposer require fukuball/jieba-php
发布配置项;php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider"
配置项中增加 tntsearch ;
/config/scout.php ;'tntsearch' => [
'storage' => storage_path('indexes'), //必须有可写权限
'fuzziness' => env('TNTSEARCH_FUZZINESS', false),
'searchBoolean' => env('TNTSEARCH_BOOLEAN', false),
'asYouType' => false,
'fuzzy' => [
'prefix_length' => 2,
'max_expansions' => 50,
'distance' => 2,
],
'tokenizer' => [
'driver' => env('TNTSEARCH_TOKENIZER', 'default'),
'jieba' => [
'dict' => 'small',
//'user_dict' => resource_path('dicts/mydict.txt'), //自定义词典路径
],
'analysis' => [
'result_type' => 2,
'unit_word' => true,
'differ_max' => true,
],
'scws' => [
'charset' => 'utf-8',
'dict' => '/usr/local/scws/etc/dict.utf8.xdb',
'rule' => '/usr/local/scws/etc/rules.utf8.ini',
'multi' => 1,
'ignore' => true,
'duality' => false,
],
],
'stopwords' => [
'的',
'了',
'而是',
],
],
增加配置项;
/.env ;SCOUT_DRIVER=tntsearch
TNTSEARCH_TOKENIZER=jieba
模型中定义全文搜索;
/app/Models/Article.php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
use Laravel\Scout\Searchable;
class Article extends Model
{
use Searchable;
/**
* 索引的字段
*
* @return array
*/
public function toSearchableArray()
{
return $this->only('id', 'title', 'content');
}
}
php 默认的 memory_limit 是 128M;
为了防止 PHP Fatal error: Allowed memory size of n bytes exhausted ;
咱给增加到 256M 以解决内存不够报错的问题;
/app/Providers/AppServiceProvider.phppublic function boot()
{
/**
* 增加内存防止中文分词报错
*/
ini_set('memory_limit', "256M");
}
生成索引;php artisan scout:import "App\Models\Article"
使用起来也相当简单;
只需要把要搜索的内容传给 search() 方法即可;
/routes/web.php
use App\Models\Article;
Route::get('search', function () {
// 为查看方便都转成数组
dump(Article::all()->toArray());
dump(Article::search('功能齐全的搜索引擎')->get()->toArray());
});
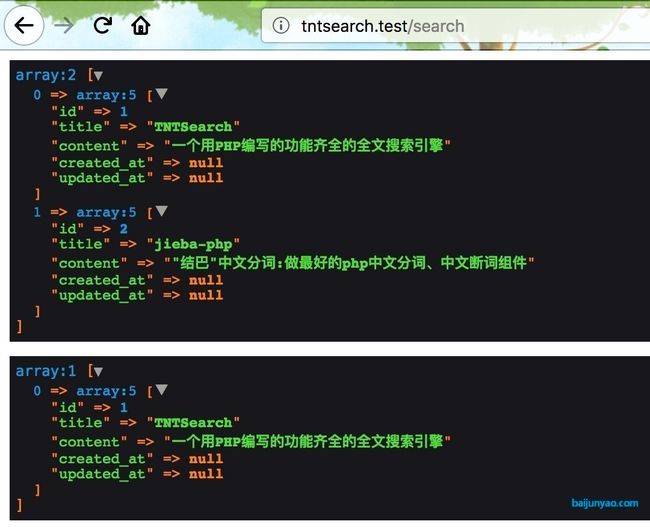
成功的查出了数据;
最后我们再测下修改数据后的同步索引;
/routes/web.php
use App\Models\Article;
Route::get('search', function () {
// 为查看方便都转成数组
dump(Article::all()->toArray());
dump('下面搜索的是:功能齐全的搜索引擎');
dump(Article::search('功能齐全的搜索引擎')->get()->toArray());
dump('此处把content改为:让全文检索变的简单而强大');
// 修改 content 测试索引是否会自动同步
$first = Article::find(1);
$first->content = '让全文检索变的简单而强大';
$first->save();
dump('下面搜索的是:功能齐全的搜索引擎');
dump(Article::search('功能齐全的搜索引擎')->get()->toArray());
dump('下面搜索的是:简单的检索');
dump(Article::search('简单的检索')->get()->toArray());
});
