基于kubernetes构建spark-thriftserver集群(Deployment模式)
继续上一篇《基于kubernetes构建spark集群(RC模式)》,沿用上一篇rbac配置,以及PV、PVC配置,本篇将采用Deployment方式进行部署spark集群,以及增加thriftserver应用服务配置。
1、构建镜像
这里采用spark-2.4.4-bin-hadoop2.7.tar.gz包部署,先解压文件到/opt/spark目录。
(1)将需要第三方扩展包导入/opt/spark/spark-2.4.4 -bin-hadoop2.7/jars目录
#可根据自己实际需要进行导入
elasticsearch-rest-high-level-client-6.7.2.jar
hive-hcatalog-core-1.2.2.jar
kudu-spark2_2.11-1.12.0.jar
mysql-connector-java-5.1.49.jar
spark-cassandra-connector_2.11-2.3.2.jar
alluxio-client-2.3.0.jar
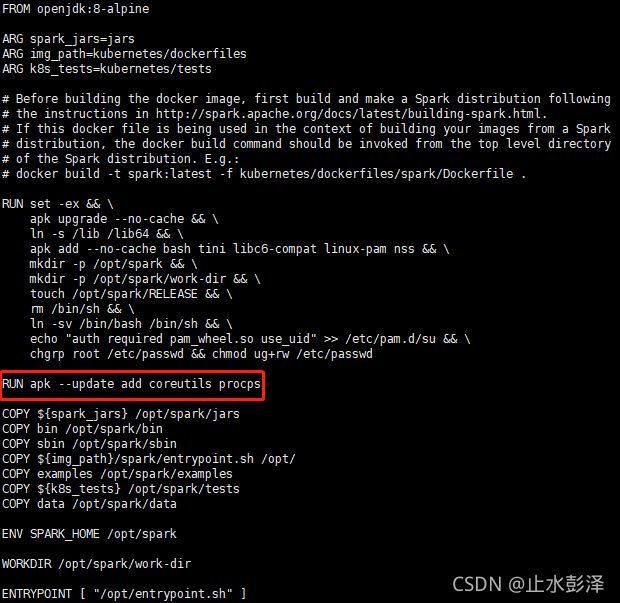
(2)增加nohup命令版本支持
带有alpine的nohup版本不支持’ - ',需要安装coreutils和procps软件包,以获取所需的nohup和ps版本,在/opt/spark/spark-2.4.4-bin-hadoop2.7/kubernetes/dockerfiles/spark/Dockerfile文件增加如下配置并保存:
RUN apk --update add coreutils procps
(3)执行构建spark镜像
进入cd /opt/spark/spark-2.4.4-bin-hadoop2.7目录,执行构建如下。
#加入项目名称:eccp
docker build -t acpimgehub.com.cn/eccp_dev/spark:202107_YD_0714_v3.21 -f kubernetes/dockerfiles/spark/Dockerfile .
2、spark master创建
spark master分为两个部分,一个是类型为ReplicationController的主体,命名为ecc-spark-master.yaml,另一部分为一个service,暴露master的7077端口给slave使用。
#如下是把thriftserver部署在master节点,则需要暴露thriftserver端口、driver端口、
#blockmanager端口服务,以提供worker节点executor与driver交互.
cat >ecc-spark-master.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:
name: ecc-spark-master
namespace: ecc-spark-cluster
labels:
app: ecc-spark-master
spec:
replicas: 1
selector:
matchLabels:
app: ecc-spark-master
template:
metadata:
labels:
app: ecc-spark-master
spec:
serviceAccountName: spark-cdp
securityContext: {}
dnsPolicy: ClusterFirst
hostname: ecc-spark-master
containers:
- name: ecc-spark-master
image: acpimgehub.com.cn/eccp_dev/spark:202107_YD_0714_v3.2
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c","sh /opt/spark/sbin/start-master.sh && tail -f /opt/spark/logs/spark--org.apache.spark.deploy.master.Master-1-*"]
ports:
- containerPort: 7077
- containerPort: 8080
volumeMounts:
- mountPath: /opt/usrjars/
name: ecc-spark-pvc
livenessProbe:
failureThreshold: 9
initialDelaySeconds: 2
periodSeconds: 15
successThreshold: 1
tcpSocket:
port: 8080
timeoutSeconds: 10
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "2"
memory: "2Gi"
volumes:
- name: ecc-spark-pvc
persistentVolumeClaim:
claimName: ecc-spark-pvc-static
---
kind: Service
apiVersion: v1
metadata:
name: ecc-spark-master
namespace: ecc-spark-cluster
spec:
ports:
- port: 7077
protocol: TCP
targetPort: 7077
name: spark
- port: 10000
protocol: TCP
targetPort: 10000
name: thrift-server-tcp
- port: 8080
targetPort: 8080
name: http
- port: 45970
protocol: TCP
targetPort: 45970
name: thrift-server-driver-tcp
- port: 45980
protocol: TCP
targetPort: 45980
name: thrift-server-blockmanager-tcp
- port: 4040
protocol: TCP
targetPort: 4040
name: thrift-server-tasks-tcp
selector:
app: ecc-spark-master
EOF
3、spark worker 创建
在启动spark worker脚本中需要传入master的地址,因为有kubernetes dns且设置了service的缘故,可以通过ecc-spark-master.ecc-spark-cluster.svc.cluster.local:7077访问。
cat >ecc-spark-worker.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:
name: ecc-spark-worker
namespace: ecc-spark-cluster
labels:
app: ecc-spark-worker
spec:
replicas: 1
selector:
matchLabels:
app: ecc-spark-worker
template:
metadata:
labels:
app: ecc-spark-worker
spec:
serviceAccountName: spark-cdp
securityContext: {}
dnsPolicy: ClusterFirst
hostname: ecc-spark-worker
containers:
- name: ecc-spark-worker
image: acpimgehub.com.cn/eccp_dev/spark:202107_YD_0714_v3.2
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c","sh /opt/spark/sbin/start-slave.sh spark://ecc-spark-master.ecc-spark-cluster.svc.cluster.local:7077;tail -f /opt/spark/logs/spark--org.apache.spark.deploy.worker.Worker*"]
ports:
- containerPort: 8081
volumeMounts:
- mountPath: /opt/usrjars/
name: ecc-spark-pvc
resources:
requests:
cpu: "2"
memory: "2Gi"
limits:
cpu: "2"
memory: "4Gi"
volumes:
- name: ecc-spark-pvc
persistentVolumeClaim:
claimName: ecc-spark-pvc-static
EOF
4、spark-ui proxy
spark ui代理服务,image为elsonrodriguez/spark-ui-proxy:1.0在k8s集群里是不可或缺。它提供查看master的管理页面,并可以从master访问woker的ui页面(因每个worker都有自己的ui地址,ip分配很随机,这些ip只能在集群内部访问)。因此需要一个代理服务,从内部访问完需要的master ui页面后,返回给我们,这样我们只需要暴露一个代理的地址即可。
cat >ecc-spark-ui-proxy.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:
name: ecc-spark-ui-proxy
namespace: ecc-spark-cluster
labels:
app: ecc-spark-ui-proxy
spec:
replicas: 1
selector:
matchLabels:
app: ecc-spark-ui-proxy
template:
metadata:
labels:
app: ecc-spark-ui-proxy
spec:
containers:
- name: ecc-spark-ui-proxy
image: elsonrodriguez/spark-ui-proxy:1.0
ports:
- containerPort: 80
resources:
requests:
cpu: "50m"
memory: "100Mi"
limits:
cpu: "100m"
memory: "150Mi"
args:
- ecc-spark-master.ecc-spark-cluster.svc.cluster.local:8080
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 120
timeoutSeconds: 5
---
kind: Service
apiVersion: v1
metadata:
name: ecc-spark-ui-proxy
namespace: ecc-spark-cluster
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 32180
selector:
app: ecc-spark-ui-proxy
EOF
至此,基于Deployment部署spark整个集群搭建完毕。即可通过集群暴露的32180端口访问管理页面,生产环境建议使用ingress暴露32180端口访问。

5、分布式 SQL 引擎服务
要使用spark thriftserver应用服务,需要连接Hive元数据,可以从链接地址下载,下载并创建好元数据库后,可以在spark master节点,执行如下脚本,启动thriftserver应用服务,如下是thriftserver集成cassandra启动示例:
#total-executor-cores: 参数决定了executor个数,spark.executor.cores:每个executor的cpu数
sh /opt/spark/sbin/start-thriftserver.sh \
--master spark://ecc-spark-master.ecc-spark-cluster.svc.cluster.local:7077 \
--name spark-thriftserver \
--total-executor-cores 3 \
--conf spark.executor.cores=1 \
--conf spark.executor.memory=512m \
--conf spark.driver.cores=1 \
--conf spark.driver.memory=512m \
--conf spark.default.parallelism=120 \
--conf spark.sql.crossJoin.enabled=true \
--conf spark.sql.autoBroadcastJoinThreshold=-1 \
--conf spark.driver.bindAddress=0.0.0.0 \
--conf spark.driver.host=ecc-spark-master.ecc-spark-cluster.svc.cluster.local \
--conf spark.driver.port=45970 \
--conf spark.blockManager.port=45980 \
--conf spark.driver.extraJavaOptions='-Duser.timezone=GMT+08:00' \
--conf spark.executor.extraJavaOptions='-Duser.timezone=GMT+08:00' \
--driver-class-path /opt/spark/jars/mysql-connector-java-5.1.49.jar \
--jars /opt/usrjars/mysql-connector-java-5.1.49.jar,/opt/usrjars/spark-cassandra-connector_2.11-2.3.4.jar \
--conf spark.cassandra.connection.host=192.168.0.1,192.168.0.2,192.168.0.3 \
--conf spark.cassandra.connection.port=9042 \
--conf spark.cassandra.auth.username=eccuser \
--conf spark.cassandra.auth.password=ecc123! \
--conf.spark.cassandra.input.consistency.level=ONE \
--conf.spark.cassandra.output.consistency.level=ONE \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf javax.jdo.option.ConnectionUserName=eccuser \
--hiveconf javax.jdo.option.ConnectionPassword='eccpassword' \
--hiveconf javax.jdo.option.ConnectionDriverName=com.mysql.jdbc.Driver \
--hiveconf javax.jdo.option.ConnectionURL='jdbc:mysql://192.168.0.1:3306/hive_meta?createDatabaseIfNotExist=true&useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai' \
--hiveconf hive.server2.authentication=NOSASL \
--hiveconf hive.metastore.sasl.enabled=false

(1)登录spark thriftserver
我们都知道kubernetes每个pod有唯一主机名,唯一域名,访问格式:service名称.namespace名称空间.svc.cluster.local,登录spark master节点执行如下命令。
#service名称.名称空间.svc.cluster.local:10000
/opt/spark/bin/beeline -u "jdbc:hive2://ecc-spark-master.ecc-spark-cluster.svc.cluster.local:10000/;auth=noSasl" -n root -p root
