MPI并行计算第一课(2小时入门)
1. 简介
MPI 全名叫 Message Passing Interface,即信息传递接口,作用是可以通过 MPI 可以在不同进程间传递消息,从而可以并行地处理任务,即进行并行计算。
2. 第一个MPI程序“Hello Word”

运行结果:

程序的执行流程:

从上面的简单例子可以看出,一个MPI程序的框架结构可以用下图表示:
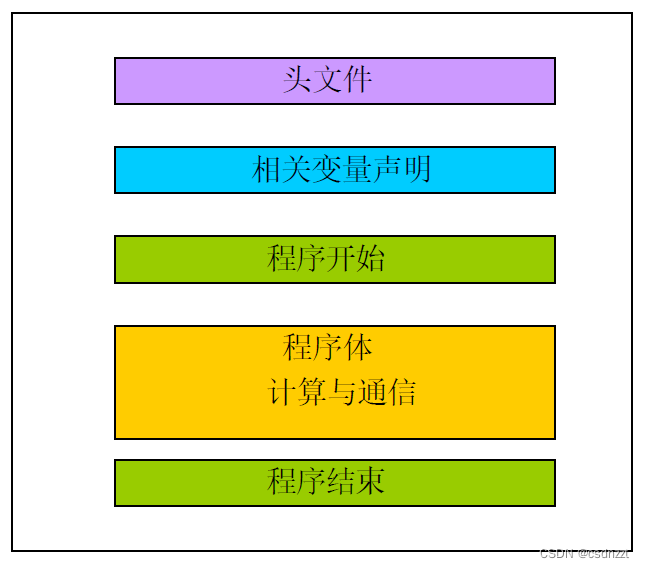
3. 六个MPI基本函数
(1)MPI初始化

(2)MPI结束
 (3)当前进程标识
(3)当前进程标识
 (4)通信域包含的进程数
(4)通信域包含的进程数
 (5)消息发送
(5)消息发送

(6)消息接收

4. MPI并行程序的两种基本模式
(1) 对等模式(以Jacobi迭代为例)
对于MPI的SPMD(Single Program Multiple Data)程序,实现对等模式的问题是比较容易理解和接受的,因为各个部分地位相同功能和代码基本一致,只不过是处理的数据或对象不同,也容易用同样的程序来实现。
Jacobi迭代就是用上下左右周围的四个点取平均值来得到新的点。
while (not converged) {
for (i,j)
xnew[i][j] = (x[i+1][j] + x[i-1][j] + x[i][j+1] + x[i][j-1])/4;
for (i,j)
x[i][j] = xnew[i][j];
}收敛性测试如下:
diffnorm = 0;
for (i,j)
diffnorm += (xnew[i][j] - x[i][j]) * (xnew[i][j] - x[i][j]);
diffnorm = sqrt(diffnorm);Jacobi迭代的局部性很好可以取得很高的并行性,是并行计算中常见的一个例子。将参加迭代的数据按块分割后,各块之间除了相邻的元素需要通信外,在各块的内部可以完全独立地并行计算,随着计算规模的扩大,通信的开销相对于计算来说比例会降低,这将更有利于提高并行效果。
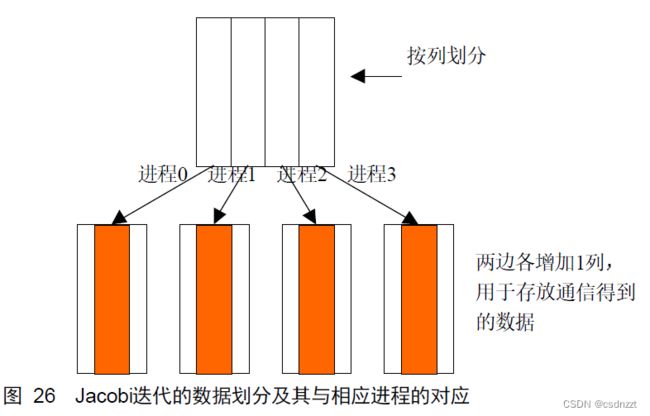
由于在迭代过程中边界点新值的计算需要相邻边界其它块的数据,因此在每一个数据块的两侧又各增加1列的数据空间(注意FORTRAN数组在内存中是按列优先排列的),用于存放从相邻数据块通信得到的数据。
在迭代之前,每个进程都需要从相邻的进程得到数据块,同时每一个进程也都需要向相邻的进程提供数据块,由于每一个新迭代点的值是由相邻点的旧值得到,所以这里引入一个中间数组用来记录临时得到的新值,一次迭代完成后再统一进行更新操作。
Fortran程序(列主序)的分割及通讯:
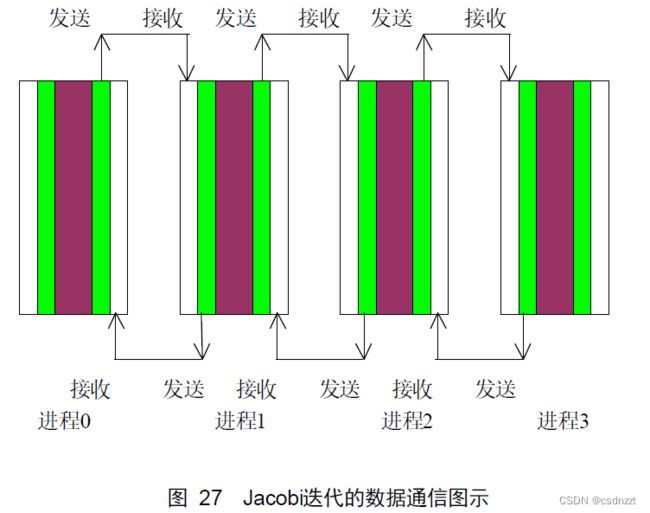
C程序(行主序)的分割及通讯:

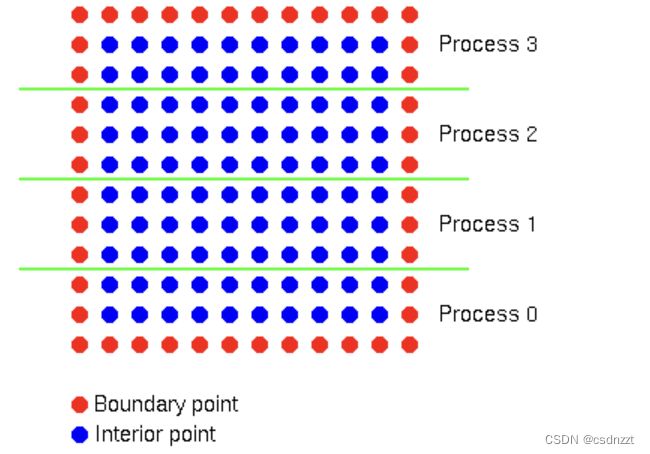
在边界上的点不用更新,初始值定义如下(上下两边都是-1,中间的数值取为进程编号):

#include
#include
#include "mpi.h"
/* This example handles a 12 x 12 mesh, on 4 processors only. */
#define maxn 12
int main( argc, argv )
int argc;
char **argv;
{
int rank, value, size, errcnt, toterr, i, j, itcnt;
int i_first, i_last;
MPI_Status status;
double diffnorm, gdiffnorm;
double xlocal[(12/4)+2][12];
double xnew[(12/3)+2][12];
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
if (size != 4) MPI_Abort( MPI_COMM_WORLD, 1 );
/* xlocal[][0] is lower ghostpoints, xlocal[][maxn+2] is upper */
/* Note that top and bottom processes have one less row of interior
points */
i_first = 1;
i_last = maxn/size;
if (rank == 0) i_first++;
if (rank == size - 1) i_last--;
/* Fill the data as specified */
for (i=1; i<=maxn/size; i++)
for (j=0; j 0)
MPI_Recv( xlocal[0], maxn, MPI_DOUBLE, rank - 1, 0,
MPI_COMM_WORLD, &status );
/* Send down unless I'm at the bottom */
if (rank > 0)
MPI_Send( xlocal[1], maxn, MPI_DOUBLE, rank - 1, 1,
MPI_COMM_WORLD );
if (rank < size - 1)
MPI_Recv( xlocal[maxn/size+1], maxn, MPI_DOUBLE, rank + 1, 1,
MPI_COMM_WORLD, &status );
/* Compute new values (but not on boundary) */
itcnt ++;
diffnorm = 0.0;
for (i=i_first; i<=i_last; i++)
for (j=1; j 1.0e-2 && itcnt < 100);
MPI_Finalize( );
return 0;
} 编译命令:
mpicc -o jacobi jacobi.c -lm
-lm 是一个链接选项,它指示编译器链接标准数学库(libm)。在 C 和 C++ 程序中,如果你使用了数学函数(如 sin, cos, sqrt 等),通常需要链接这个库。
运行命令:
mpirun -np 4 ./jacobi
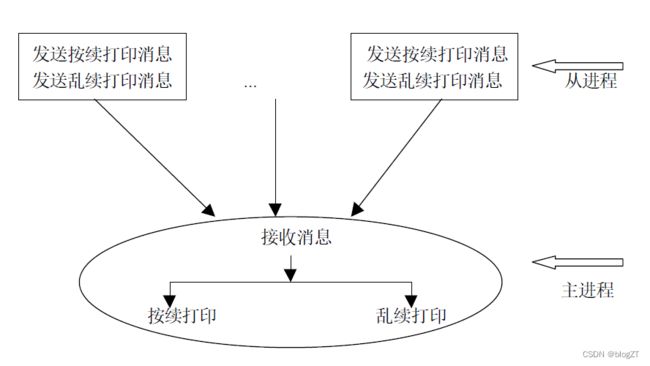
(2) 主从模式
现介绍另一种并行程序的设计模式——主从模式:我们可以在逻辑上规定一个主进程,用于将数据发送给各个进程,再收集各个进程所计算的结果。
例子1:A simple output server
实现三个功能:
- Ordered output
- Unordered output
- Exit notification
The master continues to receive messages until it has received an exit message from each slave. For simplicity in programming, have each slave send the messages
"Hello from slave %d, ordered print\n", rank
"Goodbye from slave %d, ordered print\n", rank
with the ordered output mode, and
"I'm existing (%d), unordered print\n", rankwith the unordered output mode.
#include
#include
#include "mpi.h"
#define MSG_EXIT 1
#define MSG_PRINT_ORDERED 2
#define MSG_PRINT_UNORDERED 3
void master_io()
{
int size; // 总进程数
int nslave; // 从进程数
int firstmsg;
char buf[256], buf2[256];
MPI_Status status;
MPI_Comm_size(MPI_COMM_WORLD, &size); // 得到总的进程数
nslave = size - 1;
while (nslave > 0)
{ // 只要还有从进程则执行下面的接收与打印
MPI_Recv(buf, 256, MPI_CHAR, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); // 从任意从进程接收任意标识的消息
switch (status.MPI_TAG)
{
// 若该从进程要求退出,则将总的从进程个数减1
case MSG_EXIT:
nslave--;
break;
// 若该从进程要求乱序打印,则直接将该消息打印
case MSG_PRINT_UNORDERED:
fputs(buf, stdout);
break;
// 按顺序打印
// 首先需要对收到的消息进行排序,若有些消息还没有收到则,需要调用接收语句接收相应的有序消息
case MSG_PRINT_ORDERED:
firstmsg = status.MPI_SOURCE; // the rank of the process that sent the message.
for (int i = 1; i < size; ++i)
{
// 若接收到的消息恰巧是需要打印的消息则直接打印
if (i == firstmsg)
{
fputs(buf, stdout);
}
else
{ // 否则,先接收需要打印的消息然后再打印
MPI_Recv(buf2, 256, MPI_CHAR, i, MSG_PRINT_ORDERED, MPI_COMM_WORLD, &status);
fputs(buf2, stdout);
}
}
break;
}
}
}
void slave_io()
{
char buf[256];
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 向主进程发送一个有序打印消息
sprintf(buf, "Hello from slave %d, ordered print\n", rank);
MPI_Send(buf, strlen(buf) + 1, MPI_CHAR, 0, MSG_PRINT_ORDERED, MPI_COMM_WORLD);
// 再向主进程发送一个有序打印消息
sprintf(buf, "Goodbye from slave %d, ordered print\n", rank);
MPI_Send(buf, strlen(buf) + 1, MPI_CHAR, 0, MSG_PRINT_ORDERED, MPI_COMM_WORLD);
// 向主进程发送一个乱序打印的消息
sprintf(buf, "I'm existing (%d), unordered print\n", rank);
MPI_Send(buf, strlen(buf) + 1, MPI_CHAR, 0, MSG_PRINT_UNORDERED, MPI_COMM_WORLD);
// 最后,向主进程发送退出执行的消息
MPI_Send(buf, 0, MPI_CHAR, 0, MSG_EXIT, MPI_COMM_WORLD);
}
int main(int argc, char **argv)
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0)
{
master_io(); // process 0 is the master process
}
else
{
slave_io(); // other prcess is the slave processes
}
MPI_Finalize();
}
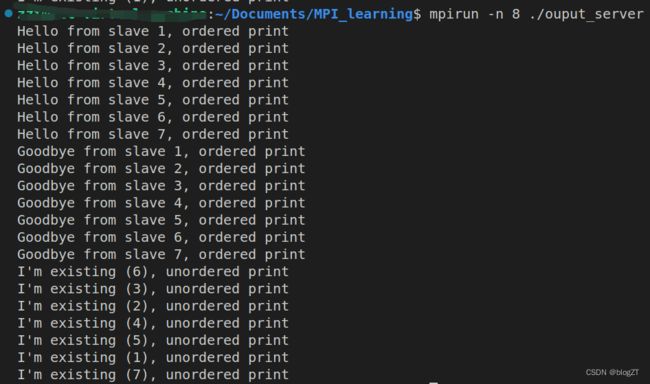
输出结果:
例子2:矩阵向量乘
下面以矩阵向量乘(c = A b)为例,看看主从模式到底是如何进行的。
具体的实现方法是:
- 主进程将向量b广播给所有的从进程,然后将矩阵A的各行依次发送给从进程。
- 从进程计算一行和b相乘的结果,然后将结果发送给主进程。
- 主进程循环向各个从进程发送一行的数据,直到将A各行的数据发送完毕。
- 一旦主进程将A的各行发送完毕,则每收到一个结果就向相应的从进程发送结束标志,从
- 进程接收到结束标志后退出执行,主进程收集完所有的结果后也结束。

#include
#include
#include
#include
// 全局变量初始化
const int rows = 10;
const int cols = 10;
double a[rows][cols] = {0}; // 矩阵 [rows,cols]
double b[cols] = {0}; // 列矩阵
double c[rows] = {0}; // 存储结果矩阵
double buffer[cols] = {0}; // 缓冲变量
int numsent = 0; // 已发送行数
int numprocs = 0; // 设置进程数
const int m_id = 0; // 主进程 id
const int end_tag = 0; // 标志发送完成的 tag
MPI_Status status; // MPI 状态
// 主进程主要干三件事: 定义数据, 发送数据和接收计算结果
void master()
{
// 1准备数据
for (int i = 0; i < cols; i++)
{
b[i] = 1;
for (int j = 0; j < rows; j++)
{
a[i][j] = i;
}
};
// 2 每个从进程都接收相同的矩阵b,
// 考虑使用广播操作, 即主进程将矩阵b向通信域内所有进程广播一下矩阵b,
// 然后从进程就可以都接收到矩阵b这一变量了.
MPI_Bcast(
b, // void* buffer
cols, // int count
MPI_DOUBLE, // MPI_Datatype datatype
m_id, // int root,
MPI_COMM_WORLD // MPI_Comm comm
);
// 矩阵A采用了之前提到过的 MPI_SEND, 发送每行的数据
// 实际的子进程数是 numprocs - 1 个
for (int i = 0; i < std::min(numprocs - 1, rows); i++)
{
for (int j = 0; j < cols; j++)
{
buffer[j] = a[i][j];
}
// 发送矩阵A 的行数据, 使用矩阵行数作为 tag MPI_DOUBLE,
MPI_Send(
buffer, // const void* buf,
cols, // int count,
MPI_DOUBLE, // MPI_Datatype datatype,
i + 1, // int dest, 0 列发给 rank 1, 以此类推
i + 1, // int tag, row number +1
MPI_COMM_WORLD // MPI_Comm comm
);
numsent = numsent + 1; // 记录已发送的行数
};
// 3 在执行完发送步骤后, 需要将计算结果收回
double ans = 0.0; // 存储结果的元素
for (int i = 0; i < rows; i++)
{
MPI_Recv(
&ans, // void* buf,
1, // int count,
MPI_DOUBLE, // MPI_Datatype datatype,
MPI_ANY_SOURCE, // int source,
MPI_ANY_TAG, // int tag,
MPI_COMM_WORLD, // MPI_Comm comm,
&status // MPI_Status * status
);
// sender 用于记录已经将结果发送回主进程的从进程号
int sender = status.MPI_SOURCE;
// 在发送时, 所标注的 tag = 矩阵的行号+1,
int rtag = status.MPI_TAG - 1;
c[rtag] = ans; // 用 c(rtag)=ans来在对应位置存储结果
// numsent 是已发送行, 用于判断是否发送完所有行
// 因其已经发送回主进程, 即可代表该从进程已经处于空闲状态
// 在之后的发送中, 就向空闲的进程继续发送计算任务
if (numsent < rows)
{
// 获取下一列
for (int j = 0; j < cols; j++)
{
buffer[j] = a[numsent][j];
}
MPI_Send(
buffer, cols, MPI_DOUBLE,
sender, numsent + 1, MPI_COMM_WORLD);
numsent = numsent + 1;
}
// 当都发送完之后, 向从进程发送一个空信息,
// 从进程接收到空信息时, 即执行MPI_FINALIZE来结束.
else
{
int tmp = 1.0;
MPI_Send(
&tmp, 0, MPI_DOUBLE,
sender, end_tag, MPI_COMM_WORLD);
}
};
}
// 子进程
void slave()
{
// 从进程首先需要接收主进程广播的矩阵b
MPI_Bcast(b, cols, MPI_DOUBLE, m_id, MPI_COMM_WORLD);
while (1)
{
MPI_Recv(
buffer, cols, MPI_DOUBLE,
m_id, MPI_ANY_TAG, MPI_COMM_WORLD,
&status);
// 直到矩阵A的所有行都计算完成后, 主进程会发送 tag 为 end_tag 的空消息,
if (status.MPI_TAG != end_tag)
{
int row = status.MPI_TAG;
double ans = 0.0;
for (int i = 0; i < cols; i++)
{
ans = ans + buffer[i] * b[i];
}
MPI_Send(
&ans, 1, MPI_DOUBLE,
m_id, row, MPI_COMM_WORLD);
}
else
{
break;
}
}
}
int main(int argc, char *argv[])
{
//----------------------------------
// MPI 初始化
MPI_Init(&argc, &argv);
// 获取进程总数
MPI_Comm_size(
MPI_COMM_WORLD, // MPI_Comm comm
&numprocs // int* size
);
// 获取rank
int myid = 0; // rank number
MPI_Comm_rank(
MPI_COMM_WORLD, // MPI_Comm comm,
&myid // int* size
);
// 打印进程信息
std::cout << "Process " << myid << " of " << numprocs << " is alive!" << std::endl;
//----------------------------------
if (myid == m_id)
{
master(); // 主进程的程序代码
}
else
{
slave(); // 从进程的程序代码
}
// 打印结果
if (myid == m_id)
{
std::cout << "A: " << std::endl;
for (int i = 0; i < cols; i++)
{
for (int j = 0; j < rows; j++)
{
std::cout << a[i][j] << " ";
}
std::cout << std::endl;
};
std::cout << "b: " << std::endl;
for (int i = 0; i < cols; i++)
{
std::cout << b[i] << std::endl;
};
std::cout << "c: " << std::endl;
for (int i = 0; i < rows; i++)
{
std::cout << "the ele (" << i << "): "
<< std::setiosflags(std::ios_base::right)
<< std::setw(15) << c[i]
<< std::resetiosflags(std::ios_base::right)
<< std::endl;
}
}
// MPI 收尾
MPI_Finalize();
}
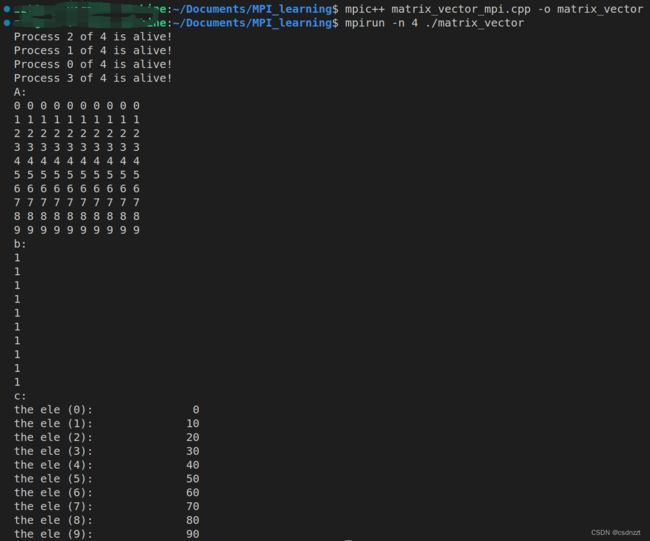
运行结果:
参考资料:
1. 都志辉. 高性能计算并行编程技术:MPI并行程序设计[M]. 清华大学出版社, 2001.
2. A simple Jacobi iteration
3. 主从模式(实现矩阵乘法) - 简书