C++类和对象-上篇(超详细)
文章目录
- 一、面向过程和面向对象的初步认识
- 二、类的引入
- 三、类的定义
-
- 1. 两种定义类的方式
- 2. 成员变量命名规则
- 四、类的访问限定符及类的封装
-
- 1. 访问限定符
- 2. 类的封装
- 五、类的作用域
- 六、类的实例化
-
- 1. 变量的声明与定义
- 2. 类的实例化
- 七、类对象模型
-
- 1. 成员函数是否重复定义?
- 2. 类对象的存储方式猜测
- 3. 结构体内存对齐规则
- 八、类成员函数的this指针
-
- 1. this指针的引出
- 2. this指针的特性
- 九. c语言与c++实现栈的区别
-
- 1. C语言实现
- 2. C++实现
一、面向过程和面向对象的初步认识
C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。

C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成。

可是面向对象和面向过程它们之间到底有什么区别呢?我们可以举一个生活中的例子来说明。
- 假如公司让你编写一个外卖订餐系统,而你只会C语言和C++。如果你使用C语言编写的话,关注的就是用户下单、商家接单、骑手送单的整个过程如何实现。
- 但如果你使用的是C++这样具有面向对象的语言去编写的话,那么此时你要关注的就是各个对象之间会发生什么关系,对象有用户、商家、骑手三个,此时你要考虑的就是用户下单、商家接单、骑手送单它们之间是谁和谁的关系。
二、类的引入
- 在使用C语言写数据结构的时候,我们在定义一个链表的时候,需要一个数据域和指针域。
struct ListNode
{
int val;
struct ListNode* next;
};
- 在C++中我们可以这样写,那就是定义这个指针域的时候可以不用写这个struct了,当然你写上也对。
struct ListNode
{
int val;
ListNode* next;
};
- 不过C++相比于C语言可不止多了这一点,C语言结构体中只能定义变量,在C++中,结构体内不仅可以定义变量,也可以定义函数。(这在C语言中)
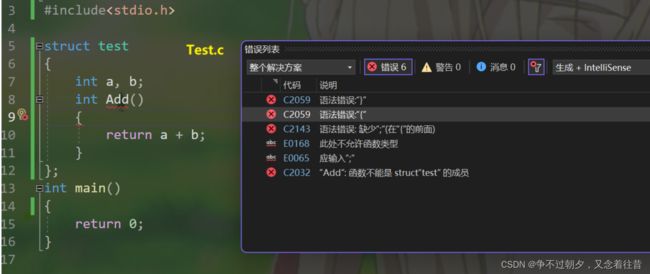

上面结构体的定义,在C++中更喜欢用class来代替。
三、类的定义
1. 两种定义类的方式
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号
【注:】class为定义类的关键字,ClassName为类的名字,{}中为类的主体,注意类定义结束时后面分号不能省略。
类体中内容称为类的成员:类中的变量称为类的属性或成员变量; 类中的函数称为类的方法或者成员函数。
类的两种定义方式:
- 声明和定义全部放在类体中,需注意:成员函数如果在类中定义,编译器可能会将其当成内联函数处理。
class student
{
void Print()
{
cout << _name << _sex << _age << endl;
}
char* _name; //姓名
char* _sex; //性别
int _age; //年龄
};
- 类声明放在.h文件中,成员函数定义放在.cpp文件中,注意:成员函数名前需要加类名::


一般情况下,更期望采用第二种方式。注意:写文章为了方便演示我通常会使用方式一定义类,但是大家后序工作中尽量使用第二种。
2. 成员变量命名规则
对于一些刚学C++的同学可能会在变量起名上显得很随意,要么随便找个字母代替,要么直接拼音当名字,这些都是不规范的。我们取名字尽量让它会意让别人一看到这个名字就知道他是类里面的还是类外面的,可能有什么用途。大家可能注意到我先前的代码中对成员变量的命名格式,在变量名前都加上了
_,可能你看起来会很别扭,但这确实比较规范的一种定义形式。
- 其实翻阅C++标准库,我们会发现这些变量的命名方式很多都是采用这种下划线的方式,原因就在于避免成员变量和形参的命名冲突从而引发争议。

四、类的访问限定符及类的封装
1. 访问限定符
- 在C++中有三类访问限定符分别是:[public]、[protected]、[private]。
- 其中,对于
public来说意思是公有的,表明从public开始到};结束,在这中间的所有成员变量或者成员函数都是公有的。那什么叫做公有呢?公有就是在类内和类外都可以所以访问不受限制。 private指的是私有,和公有是相对的,private和public的主要区别是在类外能不能访问成员变量,这就是公有和私有的区分。公有在类外也可以随便访问成员变量,但是私有的成员变量,在类外是不让访问的,这就是私有的功能。至于类内,无论是private还是public,类内都是可以自由访问的。比如说类内的成员函数访问这些成员变量是没有任何限制的。protected指的是保护,代表它会将类内的东西保护起来,我们暂时可以把它视为private,它的功能与private类似,只有在C++中的多态中才会出现差异。
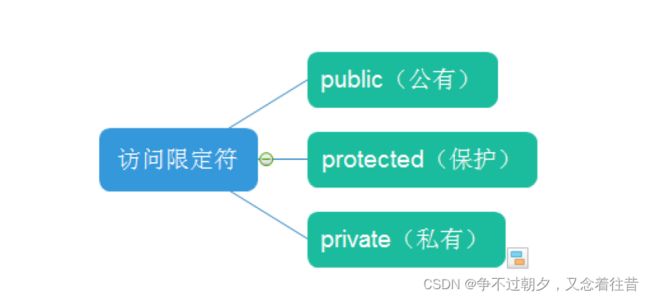
【访问限定符说明】
- public修饰的成员在类外可以直接被访问
- protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)
- 访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
- 如果后面没有访问限定符,作用域就到} 即类结束。
- class的默认访问权限为private,struct为public(因为struct要兼容C)
注意:访问限定符只在编译时有用,当数据映射到内存后,没有任何访问限定符上的区别。
对于第五点来说,可以看到当我在类中什么都不加时,默认就是private,类外不可访问的,还有同学会问,那你全都是私有的,都不能访问,这个类有啥用呢?其实类一般来说成员函数是共有的,成员变量设置为私有的。因为在类内,我们可以使用成员函数对成员变量进行操作,又因为成员函数是共有的,所以我们可以在类外通过调用成员函数(接口)来访问成员变量,这也体现了封装的思想。

【面试题】
问题:C++中struct和class的区别是什么?
解答:C++需要兼容C语言,所以C++中struct可以当成结构体使用。另外C++中struct还可以用来定义类。和class定义类是一样的,区别是struct定义的类默认访问权限是public,class定义的类默认访问权限是private。注意:在继承和模板参数列表位置,struct和class也有区别,后序给大家介绍。
2. 类的封装
【面试题】 面向对象的三大特性:封装、继承、多态。
在类和对象阶段,主要是研究类的封装特性,那什么是封装呢?
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行交互。
封装本质上是一种管理,让用户更方便使用类。比如:对于电脑这样一个复杂的设备,提供给用户的就只有开关机键、通过键盘输入,显示器,USB插孔等,让用户和计算机进行交互,完成日常事务。但实际上电脑真正工作的却是CPU、显卡、内存等一些硬件元件。

对于计算机使用者而言,不用关心内部核心部件,比如主板上线路是如何布局的,CPU内部是如何设计的等,用户只需要知道,怎么开机、怎么通过键盘和鼠标与计算机进行交互即可。因此计算机厂商在出厂时,在外部套上壳子,将内部实现细节隐藏起来,仅仅对外提供开关机、鼠标以及键盘插孔等,让用户可以与计算机进行交互即可。
在C++语言中实现封装,可以通过类将数据以及操作数据的方法进行有机结合,通过访问权限来隐藏对象内部实现细节,控制哪些方法(函数)可以在类外部直接被使用。
五、类的作用域
类定义了一个新的作用域,类的所有成员都在类的作用域中。在类体外定义成员时,需要使用 :: 作用域操作符指明成员属于哪个类域。
class Person
{
public:
void PrintPersonInfo();
private:
char _name[20];
char _gender[3];
int _age;
};
// 这里需要指定PrintPersonInfo是属于Person这个类域
void Person::PrintPersonInfo()
{
cout << _name << " "<< _gender << " " << _age << endl;
}
六、类的实例化
当我们写好一个类之后,就要去把它给定义出来,就好比在C语言中,我们要使用一个变量的话,也是要把它定义出来才行,才可以使用,例如:结构体声明好了之后就要将其定义出来,否则是没用的
1. 变量的声明与定义
- 声明与定义的区别:对于声明来讲就是告诉编译器我这里有这么一个东西,但它不是实际存在于内存的;而对于定义来说,就是实实在在的在内存中把空间开出来。
- 声明就好比你向兄弟借钱,兄弟说最近手头紧,过两个月借给你,这是一种承诺,答应给你,但是钱还没到你手里。定义就好比你和兄弟借钱,你兄弟二话没说直接把钱转你账户里了,这就叫定义,因为钱已经到你手里了。
那我们看看下图中这些变量是声明呢还是定义呢?
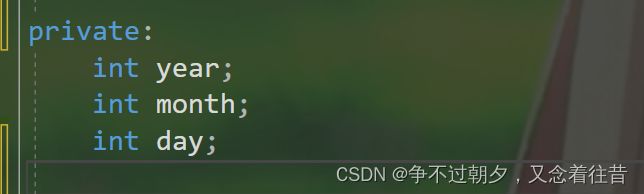
答案肯定是声明啊,因为在这个类中只是声明了类里面就这三个变量,但没给它们开空间。那怎么才能算是定义呢?让我们继续往下看类的实例化。
2. 类的实例化
用类类型创建对象的过程,称为类的实例化
- 类是对对象进行描述的,是一个模型一样的东西,限定了类有哪些成员,定义出一个类并没有分配实际的内存空间来存储它;比如:入学时填写的学生信息表,表格就可以看成是一个类,来描述具体学生信息。
类就像谜语一样,对谜底来进行描述,谜底就是谜语的一个实例。
谜语:“年纪不大,胡子一把,主人来了,就喊妈妈” 谜底:山羊 - 一个类可以实例化出多个对象,实例化出的对象 占用实际的物理空间,存储类成员变量
class Date
{
public:
int _year;
int _month;
int _day;
};
int main()
{
//Date.year = 2024; 这是错误的Date类是没有空间的
Date d; //Date类实例化出了对象d,对象d是有空间的
d._year = 2024; //只有Date类实例化出的对象才有具体的year
return 0;
}
Date类是没有空间的,只有Date类实例化出的对象才有具体的year。
- 做个比方。类实例化出对象就像现实中使用建筑设计图建造出房子,类就像是设计图,只设计出需要什么东西,但是并没有实体的建筑存在,同样类也只是一个设计,实例化出的对象才能实际存储数据,占用物理空间

七、类对象模型
1. 成员函数是否重复定义?
- 上面我们已经说过,对于一个成员变量来说,在类没有实例化之前是不存在具体空间的,但是类里面可不止有成员变量啊,还有成员函数呢,而且我们观察发现,这好像已经把成员函数定义出来了啊,空间是不是已经存在了呢?那我们再去实例化这个类,岂不是又重定义了一次成员函数嘛?可刚才我们进行实例化之后,运行代码是没有问题的,那究竟是为什么呢?难道成员函数和类没关系?成员函数的空间到底算不算类空间的一部分呢?让我们带着疑问继续往下看。

2. 类对象的存储方式猜测
-
1.对象中包含类的各个成员
-
缺陷:每个对象中成员变量是不同的,但是调用同一份函数,如果按照此种方式存储,当一个类创建多
个对象时,每个对象中都会保存一份代码,相同代码保存多次,浪费空间。那么如何解决呢?

-
2.代码只保存一份,在对象中保存存放代码的地址,这种方法看起来不错,你认为可行嘛?

-
3. 最后一种,在对象中只保存成员变量,成员函数存放在公共的代码段。每个对象保存自己的成员变量,调用函数的时候就去公共的代码区去找,这样函数代码就只需要保存一份。
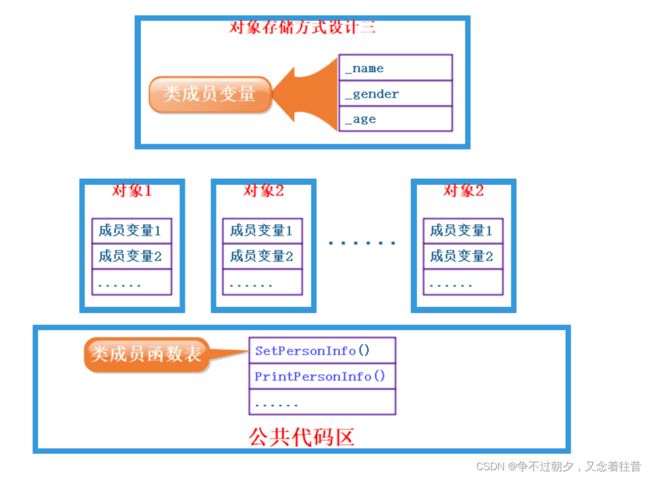
问题:对于上述三种存储方式,那计算机到底是按照那种方式来存储的?
我们再通过对下面的不同对象分别获取大小来分析看下
// 类中既有成员变量,又有成员函数
class A1 {
public:
void f1(){}
private:
int _a;
};
// 类中仅有成员函数
class A2 {
public:
void f2() {}
};
// 类中什么都没有---空类
class A3
{};

sizeof(A1) : 4 sizeof(A2) : 1 sizeof(A3) : 1
我们可以看到第一个类的大小和一个int类型的大小一样都是4,而第二个虽然有成员函数但是和第三个的什么都没有的大小一样都是1。
这里要对空类先进行说明:对于空类的大小却不太一样,空类比较特殊,编译器给了空类一个字节来唯一标识这个类的对象【这1B不存储有效数据,为一个占位符,标识对象被实例化定义出来了】
-
这么看来我们是不是就知道了是第三种存储方式啊,类的大小就是该类中成员变量之和,而成员函数只存储一次,每个类实例化出的对象调用成员函数的时候,就带着独属于本对象的信息去公共代码区调用成员函数。有人又问了,那对象可以有很多个,而成员函数的代码只有一份,那我调用函数的时候,它怎么知道成员函数中使用的数据是对象a的而不是对象b的呢?这就要到下一部分this指针来解释了。
-
为什么要这么设计呢?因为虽然每个对象的成员变量是不同的,但是对于成员函数来说,大家都是一样的,例如这个Init()函数,外界被定义出来的对象只需要调用一下这个函数去初始它自己的成员变量即可,不需要将其放在自己的类内。
-
设想若是每个类中都写一个这样相同函数的话,此时每个对象就会变得非常庞大,也就是我不去调用这个函数,只是将对象定义出来函数的空间就已经会存在了,这样的设计其实是不好的,所以我们应该采取第三种做法。
结论:一个类的大小,实际就是该类中”成员变量”之和,当然要注意内存对齐
注意空类的大小,空类比较特殊,编译器给了空类一个字节来唯一标识这个类的对象。
3. 结构体内存对齐规则
- 在C语言中,我们有去计算过一个结构体的大小,那上面我们在对于结构体和类做对比的时候说到对于struct和class都可以去定义一个类,那么结构体内存对齐的规则也一样适用。
- 具体的计算请观看这篇文章结构体计算,有兴趣的同学可以去研究一下,这里只给出了结构体内存对齐规则。
- 第一个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。注意:对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。VS中默认的对齐数为8
- 结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
【面试题】
- 结构体怎么对齐? 为什么要进行内存对齐?
- 如何让结构体按照指定的对齐参数进行对齐?能否按照3、4、5即任意字节对齐?
- 什么是大小端?如何测试某台机器是大端还是小端,有没有遇到过要考虑大小端的场景
八、类成员函数的this指针
1. this指针的引出
我们先来定义一个日期类Date
class Date {
public:
void Init(int year, int month, int day) {
_year = year;
_month = month;
_day = day;
}
void Print() { cout << _year << "-" << _month << "-" << _day << endl; }
private:
int _year; // 年
int _month; // 月
int _day; // 日
int a;
};
int main() {
Date d1, d2;
d1.Init(2022, 1, 11);
d2.Init(2022, 1, 12);
d1.Print();
d2.Print();
return 0;
}
对于上述类,有这样的一个问题:
Date类中有 Init 与 Print 两个成员函数,函数体中没有关于不同对象的区分,那当d1调用 Init 函数时,该函数是如何知道应该设置d1对象,而不是设置d2对象呢?
C++中通过引入this指针解决该问题,即:C++编译器给每个“非静态的成员函数“增加了一个隐藏的指针参数,让该指针指向当前对象(函数运行时调用该函数的对象),在函数体中所有“成员变量”的操作,都是通过该指针去访问。只不过所有的操作对用户是透明的,即用户不需要来传递,编译器自动完成。
也就是说本来我们定义的成员函数参数列表是第一行这种,但编译器会默认将this指针充当第一个参数即第二行这种,但第一个参数我们是看不见的,是编译器自动完成的。
void Init(int year, int month, int day)
void Init(Date* this, int year, int month, int day)
既然函数的形参列表变了,我们在调用的时候自然也要多传一个参数。
d1.Init(2022, 1, 11);
d1.Init(&d1, 2022, 1, 11);
当我们写出左图的代码在运行时,编译器就会自动变成右图这种形式,this指的是当前对象的地址,也就是说哪个对象调用这个成员函数,那么this指针就指向哪个对象。以下图为例,对象t1调用的Init函数,那么this指针就是t1的地址(这一点我们可以稍后验证一下),为_year、_month、_day初始化,就是对t1这个对象里的_year、_month、_day初始化,而不是其他对象的。随着每次的传入的对象地址不同,this指针就会通过不同的地址去找到内存中对应的那块地址中的成员变量,进行精准赋值。

注意,虽然编译器会帮我们把代码优化成右图这样,但我们写的时候这个Date* this是不写的,&t1也是不写的,这些编译器会帮我们写好,你要自己写的话就会报错导致无法运行。
另外虽然这个Date* this不写,但由于编译器会自动写,所以我们在函数体中是可以直接使用的,例如我们来验证一下this指针就是调用该成员函数对象的地址。
我们可以看到地址是一样的,这也验证了我们上面的说法
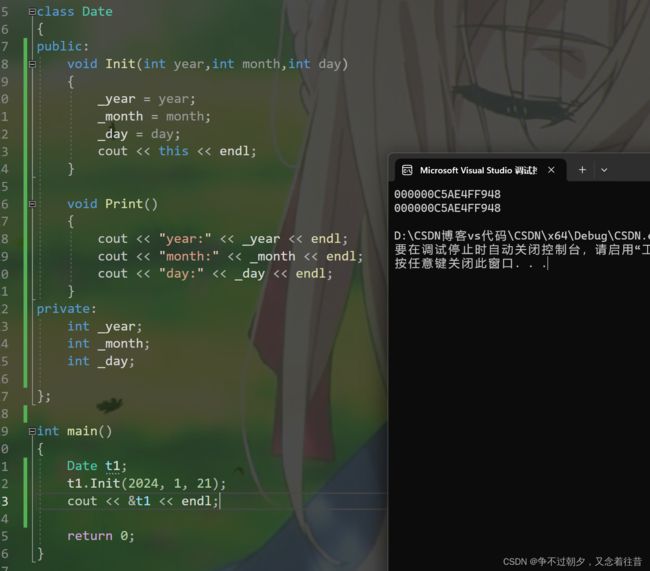
#include 2. this指针的特性
- this指针的类型:类类型* const(
Date* const),即成员函数中,不能给this指针赋值。
- 对于this指针来说,是被const常所修饰的,为【指针常量】,对于指针本身的指向是不可修改的,但是指针所指向的内容可以通过解引用的方式来修改。对于这块不清楚的可以去搜一下指针常量,和常量指针的区别。
- 只能在“成员函数”的内部使用
- 对于this指针来说,只能在类的成员函数内部进行使用,是不可以在外部进行使用的,它作为一个成员函数的形参,若没有传递给当前对象地址的话,那么它的指向是不确定的,就成了野指针了。
- this指针本质上是“成员函数”的形参,当对象调用成员函数时,将对象地址作为实参传递给this形参。所以对象中不存储this指针。
- 在上面计算内存大小中我们可以看出对象中并没有存储this指针。
- this指针是“成员函数”第一个隐含的指针形参,一般情况由编译器通过ecx寄存器自动传递,不需要用户传递

九. c语言与c++实现栈的区别
1. C语言实现
typedef int DataType;
typedef struct Stack {
DataType* array;
int capacity;
int size;
} Stack;
void StackInit(Stack* ps) {
assert(ps);
ps->array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == ps->array) {
assert(0);
return;
}
ps->capacity = 3;
ps->size = 0;
}
void StackDestroy(Stack* ps) {
assert(ps);
if (ps->array) {
free(ps->array);
ps->array = NULL;
ps->capacity = 0;
ps->size = 0;
}
}
void CheckCapacity(Stack* ps) {
if (ps->size == ps->capacity) {
int newcapacity = ps->capacity * 2;
DataType* temp =
(DataType*)realloc(ps->array, newcapacity * sizeof(DataType));
if (temp == NULL) {
perror("realloc申请空间失败!!!");
return;
}
ps->array = temp;
ps->capacity = newcapacity;
}
}
void StackPush(Stack* ps, DataType data) {
assert(ps);
CheckCapacity(ps);
ps->array[ps->size] = data;
ps->size++;
}
int StackEmpty(Stack* ps) {
assert(ps);
return 0 == ps->size;
}
void StackPop(Stack* ps) {
if (StackEmpty(ps))
return;
ps->size--;
}
DataType StackTop(Stack* ps) {
assert(!StackEmpty(ps));
return ps->array[ps->size - 1];
}
int StackSize(Stack* ps) {
assert(ps);
return ps->size;
}
int main() {
Stack s;
StackInit(&s);
StackPush(&s, 1);
StackPush(&s, 2);
StackPush(&s, 3);
StackPush(&s, 4);
printf("%d\n", StackTop(&s));
printf("%d\n", StackSize(&s));
StackPop(&s);
StackPop(&s);
printf("%d\n", StackTop(&s));
printf("%d\n", StackSize(&s));
StackDestroy(&s);
return 0;
}
可以看到,在用C语言实现时,Stack相关操作函数有以下共性:
每个函数的第一个参数都是Stack*
函数中必须要对第一个参数检测,因为该参数可能会为NULL
函数中都是通过Stack*参数操作栈的
调用时必须传递Stack结构体变量的地址
结构体中只能定义存放数据的结构,操作数据的方法不能放在结构体中,即数据和操作数据的方式是分离开的,而且实现上相当复杂一点,涉及到大量指针操作,稍不注意可能就会出错。
2. C++实现
typedef int DataType;
class Stack {
public:
void Init() {
_array = (DataType*)malloc(sizeof(DataType) * 3);
if (NULL == _array) {
perror("malloc申请空间失败!!!");
return;
}
_capacity = 3;
_size = 0;
}
void Push(DataType data) {
CheckCapacity();
_array[_size] = data;
_size++;
}
void Pop() {
if (Empty())
return;
_size--;
}
DataType Top() { return _array[_size - 1]; }
int Empty() { return 0 == _size; }
int Size() { return _size; }
void Destroy() {
if (_array) {
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private:
void CheckCapacity() {
if (_size == _capacity) {
int newcapacity = _capacity * 2;
DataType* temp =
(DataType*)realloc(_array, newcapacity * sizeof(DataType));
if (temp == NULL) {
perror("realloc申请空间失败!!!");
return;
}
_array = temp;
_capacity = newcapacity;
}
}
private:
DataType* _array;
int _capacity;
int _size;
};
int main() {
Stack s;
s.Init();
s.Push(1);
s.Push(2);
s.Push(3);
s.Push(4);
printf("%d\n", s.Top());
printf("%d\n", s.Size());
s.Pop();
s.Pop();
printf("%d\n", s.Top());
printf("%d\n", s.Size());
s.Destroy();
return 0;
}
C++中通过类可以将数据 以及 操作数据的方法进行完美结合,通过访问权限可以控制那些方法在类外可以被调用,即封装,在使用时就像使用自己的成员一样,更符合人类对一件事物的认知。而且每个方法不需要传递Stack*的参数了,编译器编译之后该参数会自动还原,即C++中 Stack * 参数是编译器维护的,C语言中需用用户自己维护。