8 分钟看完这 7000+ 字,Flink 时间窗口和时间语义这对好朋友你一定搞得懂!外送窗口计算和水印一并搞懂!!!
目录
一、时间语义 & 时间窗口
1. 前摘:
1.1 Flink的时间和窗口
1.2 什么是时间窗口和时间语义呢?
2. 时间窗口
2.1 举个例子:
2.2 3个实时数据计算场景
3. 时间语义
二、Flink上进行窗口计算:
1. 一个Flink窗口应用的大致骨架结构
2. Flink窗口的骨架结构中有两个必须的两个操作:
三、Flink Watermark水印:
1. 举个小例子:
2. 水印的概念:
3. 水印如何计算:
4. 允许延迟和侧道输出:
5. 水印生成策略:
水印策略分为内置水印策略和自定义水印策略:
四、案例以及代码
一、时间语义 & 时间窗口
1. 前摘:
1.1 Flink的时间和窗口
-
时间对应 时间语义
-
窗口对应 时间窗口
-
时间窗口和时间语义密不可分
1.2 什么是时间窗口和时间语义呢?
-
场景1:电商场景中计算每种商品每1min的累计销售额。
-
场景2:我们在观看直播时,直播间的右上角会展示最近1min的在线人数,并且每隔1min会更新一次。
-
场景3:一件商品被推荐给我们时,展示着这个商品累计的销量,并且销量还会不断地更新(假设10s更新一次)。
当我们仔细分析这3个场景中计算的实时指标时,会发现它们都可以被一个统一的计算模型所描述出来,
即:每隔一段时间计算并输出过去一段时间内的数据统计结果。这个统一的计算模型就是时间窗口,
其中的“每隔一段时间计算并输出”、“过去一段时间内的数据”、“统计结果”分别代表了时间窗口的3个重要属性。
时间窗口的计算频次
时间窗口的大小
时间窗口内的数据的处理逻辑
2. 时间窗口
2.1 举个例子:
我们以每1min计算并输出过去1min内所有商品的累计销售额的案例来说明时间窗口计算模型的处理机制。如图1-1所示,输入数据流中的每一个圆圈代表商品的一条销售记录,圆圈内的数字代表商品销售额。那么按照时间窗口的计算模型的3个属性来剖析这个需求就得到时间窗口的计算频次为1min,时间窗口的大小为1min,时间窗口内的数据的处理逻辑是将商品销售额求和。接下来,按照时间窗口计算模型的计算的话,步骤总共分为以下3步。
-
第一步,按照1min的时间窗口大小来划分窗口,将输入数据流按照1min的粒度划分为一个一个的大小为1min的窗口。如图5-1中阴影部分所示,假设销售额为3和4的数据的时间分别为9:01:03和9:02:56,那么这两条数据会分别被划分到[9:01:00, 9:02:00)和[9:02:00, 9:03:00)两个窗口中。
-
第二步,按照1min的时间窗口计算频次来触发窗口内数据的计算,每过1min,会计算过去1min的窗口内的数据。举例来说,当时间到达9:02:00时,会触发[9:01:00, 9:02:00)窗口内的数据的计算。
-
第三步,当窗口触发计算后,对窗口内所有数据的销售额进行求和。举例来说,当[9:02:00, 9:03:00)的窗口触发计算时,对所有数据销售额求和会得到9,最后将结果输出,输出数据流中每一条数据都是当前这1min内商品的总销售额。
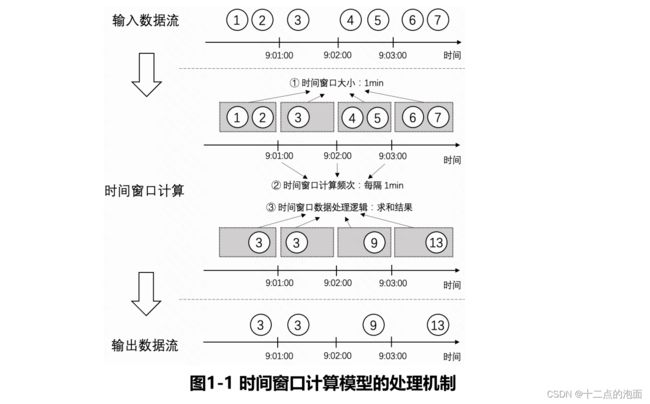
注意: 左开右闭的区间[9:01:00,9:02:00)用于描述时间范围为大于等于9:01:00和小于9:02:00的时间窗口。
2.2 3个实时数据计算场景
在看完了上述案例之后,相信大家对时间窗口计算模型已经有了初步的了解。接下来,我们再使用时间窗口计算模型重新描述一下开头提到的3个实时数据计算场景,会得到表1-2。
表1-2 使用时间窗口计算模型描述实时数据计算场景
通过表1-2可以发现,使用时间窗口计算模型来描述这些指标的口径后,这3种实时计算场景中指标的计算逻辑会变的清晰且标准。值得一提的是,当我们将场景范围进一步扩大时,会发现大部分的实时指标,包括离线指标的计算过程都符合时间窗口计算模型。比如每天计算一次过去一天的商品GMV(商品交易总额),每小计算一次过去24小时GMV,这些离线指标的计算过程都可以用时间窗口计算模型来描述。
在明确了时间窗口计算模型的计算过程之后,接下来我们就要实际上手开发一个时间窗口的应用了,当我们想使用Flink大干一场时,却发现只用时间窗口来定义和描述指标口径还存在一个问题,这个问题就和本章的另一个重点——时间语义息息相关了。先总结一下这个问题:当我们按照时间窗口计算模型处理数据时,是使用数据真实发生的时间来计算,还是使用数据到达Flink时间窗口算子SubTask时的本地机器时间来计算呢?
其中以哪种时间用作时间窗口的计算就是时间语义要讨论的问题。
3. 时间语义
-
事件时间:事件发生时(数据产生时)的时间
-
处理时间:数据到达SubTask的本地机器时间
我们以上述场景2中的直播间同时在线人数为例,如图2-1所示,A、B两名用户分别在9:01:50和9:02:00观看了一场直播,并上报了两条观看直播的数据,但是由于网络传输存在延迟,这两条数据分别在9:03:00和9:03:01才到达Flink的SubTask中。
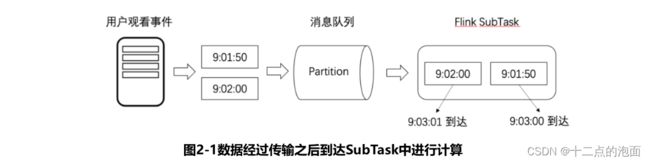
在上面这个场景中,一条数据出现了两个不同的时间,第一个是事件发生时(数据产生时)的时间,第二个是数据到达SubTask的本地机器时间,如果使用第一个时间来进行时间窗口计算,那我们就称这个时间窗口的时间语义是**事件时间**,如果使用第二个时间来进行时间窗口计算,那我们就称这个时间窗口的时间语义是**处理时间**。而如果要执行时间窗口的计算,就需要我们选择其中一种时间语义,而核心问题就在于不同的时间语义计算得到的结果是不同的!
如图2-2所示,假设我们选择处理时间语义用作时间窗口的计算,那么这两条数据的时间戳就是9:03:00和9:03:01,在进行计算时,这两条数据会被划分到[9:03:00,9:04:00)这个时间窗口中,并在SubTask本地时间到达9:04:00时触发[9:03:00,9:04:00)窗口的计算,计算得到的结果是在9:03:00到9:04:00这1min内有两名用户观看了直播。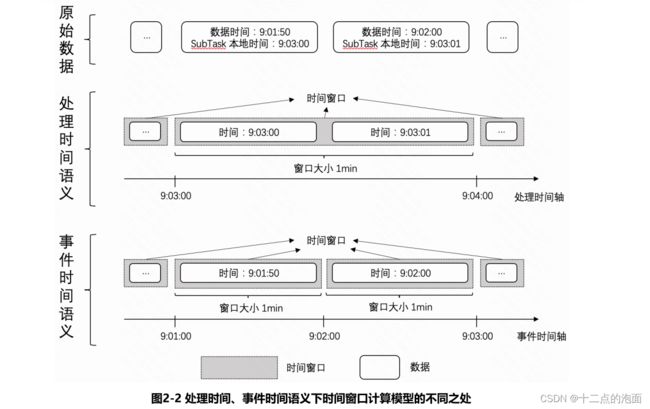
如图2-2所示,假设我们选择事件时间语义用作时间窗口的计算,那么这两条数据的时间戳就是9:01:50、9:02:00。接下来进行计算时,这两条数据会被分别分配到[9:01:00,9:02:00)、[9:02:00,9:03:00)这两个时间窗口中进行计算,并在数据的时间到达9:02:00时计算一次[9:01:00,9:02:00)窗口内数据,在数据的时间到达9:03:00时计算一次[9:02:00,9:03:00)窗口内的数据。最终算得到的结果是这个直播间在9:01:00到9:02:00这1min有一名用户观看了直播,在9:02:00到9:03:00这1min也有一名用户观看了直播。
总结:对比上述两种时间语义可以发现,以不同的时间语义去执行时间窗口计算,得到的结果将会完全不同,因此要想把时间窗口计算模型的计算逻辑完完全全的定义清楚,时间语义也是必不可少的
我们知道了时间窗口和时间语义的大致概念和它们的处理过程之后,那我们怎么使用它们做计算呢?
二、Flink上进行窗口计算:
1. 一个Flink窗口应用的大致骨架结构
如下所示:
// Keyed Window
stream
.keyBy(...) <- 按照一个Key进行分组
.window(...) <- 将数据流中的元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
// Non-Keyed Window
stream
.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function首先,我们要决定是否对一个DataStream按照Key进行分组,这一步必须在窗口计算之前进行。经过keyBy的数据流将形成多组数据,下游算子的多个实例可以并行计算。windowAll不对数据流进行分组,所有数据将发送到下游算子单个实例上。决定是否分组之后,窗口的后续操作基本相同,下文所涉及内容主要针对经过keyBy的窗口(Keyed Window),经过windowAll的算子是不分组的窗口(Non-Keyed Window),它们的原理和操作与Keyed Window类似,唯一的区别在于所有数据将发送给下游的单个实例,或者说下游算子的并行度为1。
2. Flink窗口的骨架结构中有两个必须的两个操作:
-
使用窗口分配器(WindowAssigner)将数据流中的元素分配到对应的窗口。
-
窗口分配器是Apache Flink 中的一种组件,用于定义窗口的数据方式。窗口分配器决定了如何数据分配给窗口,以及如何处理窗口内的数据
-
窗口分配器的主要职责是根据时间戳或计数器等规则将数据分配到不同的窗口中。不同的窗口分配器可以实现不同的窗口策略。例如滚动窗口、滑动窗口、会话窗口等。
-
通过使用不同的窗口分配器,用户可以灵活地处理不同类型的数据流,以满足各种实际需求。例如,在实时分析、实时计算、实时流数据挖掘等场景中,用户可以使用窗口分配器来定义时间窗口或计数器窗口,以便对流数据进行聚合、过滤、排序等操作。
-
-
-
当满足窗口触发条件后,对窗口内的数据使用窗口处理函数(Window Function)进行处理,常用的Window Function有
reduce、aggregate、process。
三、Flink Watermark水印:
1. 举个小例子:
比如工厂的生产线有一批货物要发出,每个货物上都有一个生产时间的标记,司机在门口等待货物,他每天9:00出发,只要他看到最新过来的货物上的时间是9:00,那他立马就出发。
但是久而久之他发现,有些货物会延迟到达,比如9:00的货物已经到达,忽然他又看到一个8:59的货物到达了,为了能够一次性运送更多的货物,他决定继续多等5分钟,即:如果9:05的货物到达后,他就立马出发,不再等待了。
这样的话,即使有延迟到达的货物,只要它们能在9:05分之前到达,那这部分货物也会被发出。
2. 水印的概念:
我们来思考一个场景,比如,对于窗口[12:00-12:10),事件时间为12:04的数据,由于网络原因,到达Flink的时间是12:11。此时窗口已经关闭了,该数据将不属于任何窗口,最终这个数据会丢失。
所以,为了保证计算结果的正确性,需要让窗口等待延迟数据到达后再进行计算,但是也不能无限期地等待下去,必须有一种机制来确定何时触发窗口计算,这种机制就是水印(Watermark)。
-
水印是一种用于衡量事件时间进度的机制,其表示某个时刻(事件时间)以前的数据将不再产生,因此水印指的是一个时间点。水印作为数据流的一部分流动,并带有时间戳t。t表示该流中不应再有时间戳小于等于t的元素(即时间戳早于或等于水印的事件)。
如下图,显示了带有时间戳和嵌入式水印的事件流,事件是按顺序排列的,这意味着水印只是流中的周期性标记。
水印对于乱序流至关重要,如下图,其中事件不是按其时间戳排序的。通常,水印是数据流中一个点的声明,表示水印之前的所有事件都应该到达。一旦水印到达,算子则认为某个时间周期内的所有事件已经被收到,不会再有更多符合条件的事件了。
3. 水印如何计算:
-
计算水印需要提前指定一个允许最大延迟时间的参数。
-
水印 = 进入Flink的当前最大事件时间(比如上面例子中的9:05分到达的货物) ‒ 允许最大延迟时间(比如上面例子中的司机多等待的5分钟)。
-
当水印 >= 窗口结束时间时,立即触发窗口计算,计算完毕后发射出计算结果并销毁窗口,否则窗口将一直等待。
-
所以,窗口触发计算的规则是:进入Flink的当前最大事件时间 >= 窗口结束时间+允许最大延迟时间。可见,设置水印后会改变窗口的触发计算规则。
-
进入Flink的当前最大事件时间 --> 9:05 窗口结束时间 --> 9:00 允许最大延迟时间 --> 5分钟
-
-
例子:
-
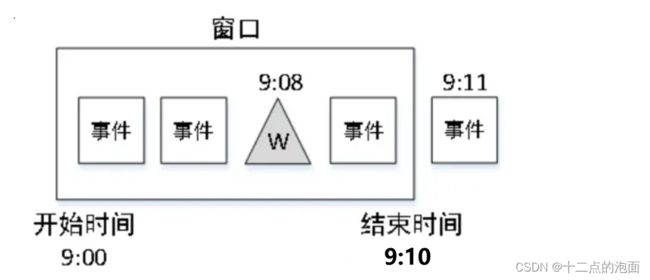
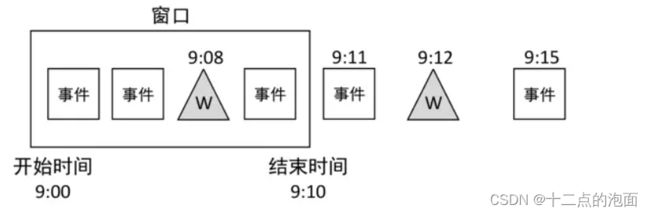
假设有一个[9:00~9:10)的窗口,设置的允许最大延迟时间为3分钟,当事件时间戳为9:11的事件到达时(说明有些数据可能已经延迟了,我在多等一会儿),由于该事件时间是进入Flink的当前最大事件时间,因此Watermark = 9:11‒3(分钟)= 9:08。此时水印在窗口内部不会触发窗口计算,窗口继续等待延迟数据。如下图:
.
-
接下来当事件时间戳为9:15的事件到达时,由于该事件时间是进入Flink的当前最大事件时间,因此Watermark = 9:15‒3(分钟)= 9:12。此时水印在窗口外部,满足窗口触发计算的规则:Watermark >= 窗口结束时间,因此窗口会立即触发计算,计算完毕后发射出计算结果并销毁窗口。
.
-
4. 允许延迟和侧道输出:
-
允许延迟机制与水印不同,允许延迟并不会延迟触发窗口计算,而是触发窗口计算之后不会立马销毁窗口,会在一段时间内继续保留计算状态
-
超过允许延迟时间的数据,Flink会将其放入侧道输出。侧道输出可以将数据收集起来,根据系统自身业务单独处理或存放于指定位置。
allowedLateness(lateness: Time):设置允许的延迟时间。 sideOutputLateData(outputTag: OutputTag[T]):将延迟到达的数据保存到outputTag对象中。
5. 水印生成策略:
我们可以针对每个事件生成水印,但是由于每个水印都会在下游做一些计算,因此过多的水印会降低程序性能。这就需要一种策略来规定
Flink程序什么时候可以开始生成水印。在
Flink DataStream中使用assignTimestampsAndWatermarks方法用于生成水印。其作用是给数据流中的元素分配时间戳(Flink需要知道每个元素的事件时间),并生成水印以标记事件时间进度。
水印策略分为内置水印策略和自定义水印策略:
-
周期性水印策略
-
周期性地产生水印,默认周期时间是200毫秒。意思是,每隔200毫秒系统开始生成水印,其生成的规则为:水印 = 进入Flink的当前最大事件时间 ‒ 允许的最大延迟时间。
-
-
单调递增水印策略
-
水印是周期产生的,紧紧跟随数据中的最新时间戳。该策略实际上使用的就是周期性水印策略,只是将允许的最大延迟时间设置为0,即在周期性水印策略的基础上去掉了允许的最大延迟时间。WatermarkStrategy接口中已经内置了用于创建单调递增水印策略的静态方法forMonotonousTimestamps()。
-
-
无水印水印策略
-
该策略创建不生成任何水印的水印策略。该策略在纯基于处理时间的流处理的场景中可能很有用。WatermarkStrategy.noWatermarks()。
-
-
自定义水印策略
-
Flink内置的水印策略可以满足大部分应用场景,如果自定义水印策略需要实现
WatermarkStrategy接口。
-
四、案例以及代码:
1、水印例子
比如,在控制台输入数据的事件时间和数据,通过自定义的水印策略,允许延迟2S的数据进入窗口计算。
代码如下:
// 比如输入:1000,a 2000,a 3000,b
DataStream> windowCountStream = textStream
// 水印策略,对于过来的事件时间上,可以延迟2秒
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((event, timestamp) ->
Long.parseLong(event.split(",")[0])))
.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
String[] splits = value.split(",");
return Tuple2.of(splits[1], 1);
}
})
.keyBy(value -> value.f0)
// 滚动5分钟的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1); 2、延迟数据和侧道输出
代码如下:
private static final OutputTag> lateEventsTag =
new OutputTag>("late-events") {
};
// 比如输入:1000,a 2000,a 3000,b
SingleOutputStreamOperator> windowCountStream = textStream
// 水印策略,对于过来的事件时间上,可以延迟2秒
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((event, timestamp) ->
Long.parseLong(event.split(",")[0])))
.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
String[] splits = value.split(",");
return Tuple2.of(splits[1], 1);
}
})
.keyBy(value -> value.f0)
// 滚动5分钟的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(lateEventsTag)
.apply(new WindowFunction, Tuple2, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable> input, Collector> out) throws Exception {
out.collect(input.iterator().next());
}
});