Recommender Systems with Generative Retrieval
TLDR: 本文提出一种新的生成式检索推荐系统范式TIGER。当前基于大规模检索模型的现代推荐系统,一般由两个阶段的流程实现:训练双编码器模型得到在同一空间中query和候选item的embedding,然后通过近似最近邻搜索来检索出给定query的embedding的最优候选集。与上述不同的是,本文提出了一种新的单阶段范式,即一种生成式检索模型。

论文:arxiv.org/abs/2305.05065
这种范式下,只需要在一个阶段内自回归地解码目标候选项的ID。为了做到这一点,文中不是为每个item分配随机生成的原子ID,而是生成语义ID:每个item的具有语义意义的编码元组,作为它的唯一标识符token。作者采用一种名为RQ-VAE的分层方法来生成这些编码,当所有item都有了语义ID,就会使用基于Transformer的序列到序列模型来预测下一个item的语义ID。由于这个模型以自回归方式直接预测标识下一个item的编码词组,因此它可以被视为生成式检索模型。我们展示了在这种新范式下训练的推荐系统比当前Amazon数据集上的SOTA模型表现有所改进。此外,我们证明了序列到序列模型与分层语义ID相结合提供更好的泛化能力,从而提高了推荐系统的冷启动效果。
1 介绍
推荐系统帮助用户发现感兴趣的内容,并在各种推荐领域中变得普遍,如视频,应用,产品,音乐。现代推荐系统采用召回和排序策略,在召回阶段选择一组可行的候选集,然后使用排序模型对它们进行排序。由于排序模型仅在召回的候选集上作用,因此期望召回阶段得到高度相关的候选集。
建立召回模型有标准和成熟的方法,例如通过矩阵分解将query和候选映射到同一个空间。为了更好地捕捉数据中的非线性,双编码器体系结构(即一个用于查询,另一个用于候选集的塔)采用内积将查询和候选集映射到同一空间,近年来越来越受到欢迎。为了在推理时使用这些模型,使用候选塔创建存储所有item的embedding的索引。对于给定的查询,使用查询塔计算其embedding,然后使用近似最近邻(ANN)算法选择最优的候选集。另一方面,序列推荐器,它们明确考虑了用户-item交互的顺序,最近也很流行。当训练时,它们还通常在输出层中使用softmax,并在推理时转向使用ANN。
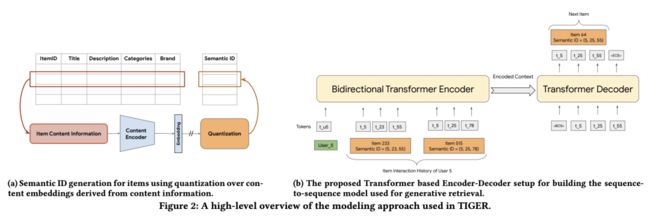
作者提出一种序列推荐器的生成检索模型的新范式。与传统的查询候选匹配方法不同,作者的方法使用端到端生成模型直接预测候选ID,避免了任何离散的、不可微分的内积搜索或索引。使用自回归解码和beam搜索,可以检索多个可行的候选集。在这种情况下,可以将Transformer 参数解释为端到端推荐索引。作者将他们提出的方法命名为TIGER,即Transformer Index for Generative Recommenders。TIGER的高层次概述如图1所示。

TIGER被赋予了一个新的特点:“语义ID”,该语义ID是基于该item的内容信息(例如其文本描述)构成的token序列。具体而言,给定一个item的文本描述,使用预训练的文本编码器生成dense的embedding。然后应用量化方法对embedding进行处理,以形成tokens的集合。作者称这个有序codewords元组为项目的语义ID。文中从人类语言中汲取灵感,人类使用单词来表达概念并将单词串联起来来表达复杂的思想。同样,作者想要开发一种用于表示item的ID语言。通过这种方式,我们可以使用有限的词汇集的序列来表示数十亿个item,而不是需要为每个项目生成随机生成的原子ID。
在从文本生成图像时,也采用了类似的思想,其中使用ViT-VQGAN将图像表示为token。一个重要的区别是,在生成图像时,少数不正确的标记会导致图像中的小的错误或噪声。相比之下,本方法中一个错误的token将意味着推荐系统预测一个不同的或不存在的item。
使用这些语义ID有很多好处。现代推荐系统中的用户和item数量可能达到数十亿级别。因此,在使用原子ID和embedding vectors之间一一映射时,基于ANN的模型的嵌入表可能会变得过于庞大。这不仅需要巨大的内存和存储空间,还会导致item embedding在训练时存在不平衡性,其中热门item将被过度采样,而长尾item将被低采样。因此,通常会为更受欢迎的item维护专用词汇表,并在一组固定的桶中随机哈希剩余item。然而,哈希方案会导致随机冲突。随着新项目在现实世界推荐产品中的引入,随机冲突可能会加剧冷启动问题。相比之下,本文的方法仅需要维护一个小的tokens集合的嵌入表。此外,在本文的情况下,碰撞具有语义上的意义,这有助于缓解冷启动问题。
本文的主要贡献有:
(1)提出了TIGER,一种新颖的生成式检索推荐模型,首先为每个项目分配唯一的语义ID,然后训练一个检索模型来预测用户感兴趣的下一个item的语义ID。这提供了一种替代高维度最近邻搜索或softmax推荐系统的方法。
(2)展示了TIGER在多个数据集上优于现有SOTA推荐系统的召回率和NDCG度量。
(3)生成式检索的这种新范式在序列推荐系统中具有两个额外的功能:1.能够推荐新的和长尾的item,从而改善冷启动问题,2.能够使用可调参数生成多样的推荐结果。
2 相关工作
2.1 序列推荐:在推荐系统中使用深度序列模型已经有很多的研究
1、GRU4REC是第一个使用基于GRU的RNN进行序列推荐的模型。
2、NARM(基于神经注意力的会话推荐)使用注意力机制以及GRU层来跟踪用户的长期和当前意图。
3、AttRec使用自注意机制来模拟用户在当前会话中的兴趣,并通过使用度量学习单独地建模用户和item关系来增加个性化。
4、SASRec 使用了与解码器模型类似的自我注意机制。
5、BERT4Rec 和 Transformers4Rec,受语言任务中掩码语言建模的成功启发,使用具有掩码策略的转换器模型来进行序列推荐任务。
6、S3-Rec 在此基础上,不仅仅依赖于掩码,还预训练了四个自监督任务来改进数据表示。
7、 VQ-Rec ,使用内容信息生成“codes”(类似于本文使用的语义 ID)来表示item。这种方法的重点是建立可迁移的推荐系统,并不使用代码以生成方式进行检索。尽管使用乘积量化生成codes,但本文使用 RQ-VAE 生成语义ID。
8、P5和 M6 微调预训练的大型语言模型,以获得输出令牌的多任务推荐系统。对于 P5,模型依赖于 LLM 使用的标记器(Sentence Piece 标记器)来生成非语义的项目 ID 令牌。另一方面,M6 直接标记输出推荐item的名称。
9、Transrec,使用从多模式辅助信息生成的多模式item表示,从而使其能够将模型迁移到基于文本和基于图像的推荐领域。该框架中预测的item也使用最大内积搜索作为最后一步计算。
上述所有模型都学习独立的高维嵌入以表示每个item,然后执行 ANN 或最大内积搜索(MIPS)来预测下一个item。相比之下,作者提出的技术 TIGER 使用生成检索直接预测下一个项目的语义ID。我们使用基于内容信息更具原则性的方式生成语义 ID,该方式与大多数现有的序列到序列模型兼容,并且在表 3 中表明,我们提出的方法比使用随机codes元组要好得多。
2.2 生成检索
生成检索是自然语言处理社区中最近研究的一种文档检索方法,其任务是从数据库返回一组相关文档。文档检索传统上训练一个双塔模型,该模型将query和文档映射到相同的高维向量空间,然后在所有文档上执行ANN或MIPS以返回最接近的文档。这种技术存在一些缺点,例如具有大型嵌入表。生成检索是一种最近提出的技术,旨在通过逐标记产生文档的标题、名称或文档 ID 字符串来修复传统方法的一些问题。1、用于实体检索的 GENRE,它使用基于转换器的体系结构来逐标记返回给定查询中引用的实体的名称。
2、用于文档检索的DSI,它是第一个为每个文档分配结构化语义 DocID 的系统。然后,给定查询,该模型会自回归逐标记返回文档的 DocID。DSI 工作标志着信息检索向生成检索方法的范式转变,是将端到端转换器成功应用于检索应用的第一个工作。
3、Generative retrieval forlong sequences表明,即使在多跳设置中,即复杂查询无法直接由单个文档回答的情况下,生成文档检索也是有用的,因此他们的模型逐渐自动生成中间查询,以链式思考的方式最终生成复杂查询的输出。
4、A neural corpusindexer for document retrieval提出了一种新的解码器架构,其中考虑了语义 DocID 中的前缀,以增强基于分层 -means 聚类的方法。
5、在 CGR中,作者提出了一种同时利用双编码技术和生成检索技术的方法,通过允许编码器解码器倍增地学习单独的上下文embedding,存储有关文档的信息。
作者介绍他们是首次使用自动编码器(RQ-VAE)创建生成语义 ID 用于检索模型的研究组织。
2.3 向量量化
向量量化是将高维向量转换为低维元组的过程。最直接的技术之一是使用分层聚类,例如 Transformer memory as a differentiable search index中使用的聚类,其中在特定迭代中创建的聚类在下一迭代中被进一步分区。替代流行的方法是向量量化变分自动编码器(VQ-VAE),它在 Neural discrete representation learning.Advances in neural information processing systems中作为将自然图像编码为代码序列的一种方式。该技术的工作原理是首先将输入向量(或图像)通过编码器降低维数。较小的维度向量被分为子集,然后每个子集分别进行量化,因此产生一个代码序列:每个分区一个代码。这些代码然后由解码器用于重新创建原始向量(或图像)。RQ-VAE对 VQ-VAE 的编码器输出使用残差量化来实现更低的重建误差。局部敏感哈希(LSH) 是用于聚类和近似最近邻搜索的流行技术。在本文中用于聚类的特定版本是 SimHash,它使用随机超平面创建二进制向量,这些向量用作项目的散列。由于它具有低计算复杂度和可伸缩性,作者将其用作向量量化的基线技术。
3 提出的框架
我们提出的技术包括两个组成部分:(1)使用内容特征生成语义标识。这包括将项目内容特征映射到embedding vectors,进一步量化为一组语义编码词的元组。我们将此元组称为item的语义ID。(2)在语义ID上训练生成式推荐系统。在用户交互历史记录中对应于item的语义ID序列上训练基于Transformer的序列到序列模型,以预测序列中下一个item的语义ID。
3.1 语义ID生成
本节描述了语料库中item的语义ID生成过程。假设每个item都有相应的内容特征,可以捕捉有用的语义信息(例如标题或描述或图片)。此外,假设能够访问预训练的内容编码器以生成语义embedding。例如,通用预训练文本编码器,如句子-T5 和BERT,可用于将项目的文本描述转换为embedding。在这项工作中,作者使用项目的文本描述作为内容特征,并使用Sentence-T5编码器对此文本描述进行编码处理。然后将语义embedding进行量化以生成每个item的语义ID。图2a提供了这一过程的高层次概述。此方法类似于使用BERT编码器生成embedding,但是他们量化embedding的方式与本文不同。
文中将语义标识定义为长度为的码字元组。元组的每个codeword,可以来自不同的codebook。因此,语义ID能够唯一表示的items数量等于codebook大小的乘积。虽然使用不同的技术生成语义ID会导致代码具有不同的语义属性,但我们希望它们通常具有以下特性:相似的item(具有相似的内容特征或其语义embedding接近)应具有重叠的codeword。例如,具有语义ID(10,21,35)的item应与具有语义ID(10,21,40)的项目更相似,而不是表示为(10,23,32)的item。
3.1.1 RQ-VAE用于语义标识
残差量化变分自编码器(RQ-VAE)是一个多级矢量量化器,它在多个级别上对残差应用量化以生成codeword(也称为语义ID)。自编码器联合训练codebook和编码器-解码器,仅使用语义ID重建输入。
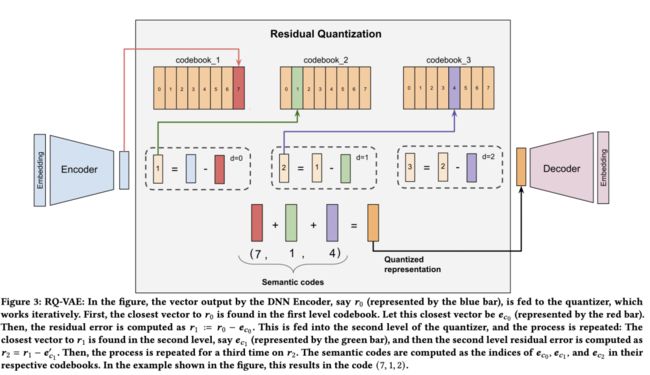
图3说明了通过残差量化生成语义标识的过程。RQ-VAE首先通过编码器E将输入编码成学习到的潜在表示形式在零级( = 0)处,在每个级别处,我们有一个码书。然后,通过映射到该级别的最近嵌入来进行量化。最接近的嵌入时的索引表示零级码字。对于下一级 = 1,然后,类似于零级,使用第一级的码书计算第一级的代码。这个过程迭代次,以获得表示语义标识的个码字元组。这种递归方法近似于从粗到细的粒度对输入进行估计。
为了防止RQ-VAE发生codebook坍塌,即将大部分输入映射到仅几个codebook向量中,我们使用基于k均值聚类的初始codebook初始化。具体而言,在第一个训练批次上应用k均值算法,并使用聚类中心作为初始化。
3.1.2 量化的其他选项
生成语义ID的简单替代方法是使用局部敏感哈希(LSH)。文中后面进行了消融研究,发现RQ-VAE确实比LSH更好。另一种选择是分层使用k均值聚类,但它失去了不同集群之间的语义含义。作者也尝试了VQ-VAE,尽管它在生成检索候选集方面表现与RQ-VAE类似,但它失去了ID的分层性质。
3.1.3 处理冲突
对于检索,我们希望避免冲突并为每个item分配唯一的ID。根据语义embedding的分布,codebook大小的选择以及codeword的长度,仍可能出现冲突。对于使用的超参数,观察到数据集中有一些具有非常相似语义embedding的item分配给它们的相同语义ID。为了消除冲突,文中在语义ID的末尾附加一个额外的标记,使它们成为唯一的。例如,如果两个item共享语义ID(12,24,52),则附加额外的标记以区分它们,因此它们分别表示为(12,24,52,0)和(12,24,52,1)。
3.2 使用语义ID的生成检索
通过按照用户与之交互的item的时间顺序对每个用户构建item序列。然后,给定形式为(item1,...,item)的序列,推荐系统的任务是预测下一个项目item+1。为此,作者提出了一种生成方法,直接预测项目的语义ID。因此,这种形式不需要对现有的序列模型架构进行任何重大修改,以便对它们进行生成式推荐的训练。一旦有了预测的codeword元组,只需查找对应于这个语义ID的item即可。生成的语义ID未能与数据集中的任何item匹配是有可能的。但是,正如在图6中观察到的那样,这种情况发生的概率非常低。
4 实验
作者进行了详尽的实验,回答以下研究问题:
研究问题1:本文提出的框架(TIGER)在序列推荐任务上的表现如何,与基线方法相比如何?
研究问题2:使用语义ID的item表示选择是否有意义?
研究问题3:有了这种新的范式,会出现什么新的推荐能力?
4.1 实验设置
在本节中,描述了TIGER框架的数据集,评估指标和实现细节。
4.1.1 数据集
在三个公共基准上评估所提出的框架,这些基准来自于Amazon Product Reviews数据集,该数据集包含从1996年5月至2014年7月的用户评论和item元数据。具体而言,使用“美容”、“运动和户外”和“玩具和游戏”三个类别的亚马逊产品评论数据集进行序列推荐任务。
表2总结了数据集的统计信息
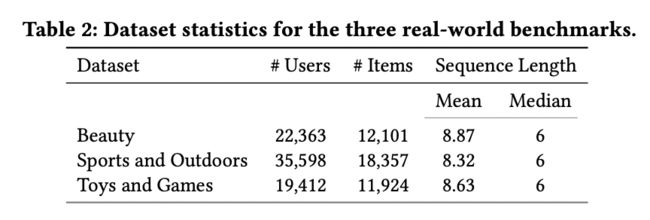
文中使用用户的评论历史记录创建按时间戳排序的item序列,并过滤掉评论少于5篇的用户。遵循标准的评估协议,使用留一策略进行评估。对于每个item序列,最后一个item用于测试,倒数第二个item用于验证,其余的用于训练。在训练期间,将用户历史中的item数量限制为20个。
4.1.2 评估指标
我们使用 top-k Recall (Recall@K) 和 Normalized Discounted Cumulative Gain (NDCG@K) 与 = 5, 10 来评估推荐性能。
4.1.3 实现细节
RQ-VAE 模型
RQ-VAE 用于量化item的语义embedding。作者使用预训练的 Sentence-T5 模型来获取数据集中每个item的语义embedding。具体而言,使用item的内容特征,如标题、价格、品牌和类别来构建一个句子,然后将其传递给预训练的 Sentence-T5 模型,以获取项目的 768 维语义embedding。
RQ-VAE 模型包括三个组件:DNN 编码器将输入语义嵌入编码为潜在表示、残差量化器输出量化表示和 DNN 解码器将量化表示解码回语义输入嵌入空间。编码器有三个大小分别为 512、256 和 128 的中间层,采用 ReLU 激活函数,最终潜在表示的维度为 32。为了量化这个表示,进行了三个级别的残差量化。对于每个量化的阶段,都维护一个基数为 256 的码簿,其中码簿中的每个向量的维度为 32。在计算总损失时,使用 = 0.25。RQ-VAE 模型经过 20k 次训练,以确保高代码簿使用率(≥ 80%)。使用 Adagrad 优化器,学习率为 0.4,批量大小为 1024。在训练完成后,使用学习的编码器和量化模块为每个item生成 3 元组的语义 ID。为了避免将多个项目映射到同一个语义 ID,为共享相同前三个码字的item添加一个唯一的代码。例如,与元组 (7, 1, 4) 相关联的两个项目分别分配为 (7, 1, 4, 0) 和 (7, 1, 4, 1)(如果没有冲突,将 0 作为第四个码字进行分配)。这样,推荐语料库中每个项目都具有长度为 4 的唯一语义 ID。这是在 TIGER 中使用的语义 ID 生成算法。值得注意的是,作者观察到小于 40 个item共享相同的前三个码字,因此 4码字的基数最多为 40。
序列到序列模型
我们使用开源的 T5X 框架实现基于 Transformer 的编码器-解码器架构。为了让模型能够处理序列推荐任务的输入,我们将语义码字添加到序列到序列模型的词汇表中。具体而言,我们添加了 1024(256×4)个tokens到词汇表中。除了语义码字,我们还向词汇表中添加了用户特定的token。为了保持词汇表大小有限,我们仅为用户 ID 添加了 2000 个tokens。我们使用散列技巧将原始用户 ID 映射到其中一个 2000 个用户 ID个tokens。我们将输入序列构造为用户 ID token,然后跟与给定用户的item交互历史相对应的语义 ID token序列。我们发现,将用户 ID 添加到输入中,可以使模型个性化推荐item。
编码器和解码器模型分别使用了 4 层,每一层有 6 个维度为 64 的自注意力头。我们对所有层使用了 ReLU 激活函数,并分别将 MLP 和输入维度设置为 1024 和 128。我们使用了 0.1 的 dropout。总的来说,该模型约有 1300 万个参数。我们为“Beauty”和“Sports and Outdoors”数据集对该模型进行了 200k 步的训练。由于“Toys and Games”数据集的规模较小,我们仅训练了 100k 步。我们使用批量大小为 256,学习率为 0.01 的逆平方根衰减。
4.2 序列推荐的性能
首先在序列推荐任务上评估模型,并将 TIGER 的性能与现有最先进的序列推荐模型进行比较。接下来,简要描述最近针对序列推荐任务提出的基线,并讨论所有模型的性能。
4.2.1 基线
将我们提出的生成检索框架与其他几种序列推荐方法进行比较。
• GRU4Rec是第一个使用自定义 GRU 进行序列推荐任务的基于 RNN 的方法。
• Caser使用 CNN 结构通过应用水平和垂直卷积运算来捕获高阶马尔科夫链进行序列推荐。
• HGN:分层门控网络(HGN)通过新的门控体系结构捕获长期和短期用户兴趣。
• SASRec:Self-Attentive Sequential Recommendation(SASRec)使用因果掩码 Transformer 来模拟用户的序列交互。
• BERT4Rec:BERT4Rec 通过使用双向自注意 Transformer 来解决单向体系结构的局限性,用于推荐任务。
• FDSA:特征层深度自注意力网络(FDSA)在Transformer中将商品特征和商品嵌入一起作为输入序列的一部分。
• S3-Rec:自监督序列推荐学习(S3-Rec)建议在自我监督任务上对双向Transformer进行预训练,以改进序列推荐。
• P5:P5是一种最近的方法,使用预训练的大型语言模型(LLM)将不同的推荐任务统一在单个模型中。
值得注意的是,除了P5以外的所有基准模型都使用双编码器学习高维向量空间,其中用户的过去商品交互和候选商品被编码为高维表示,并使用最大内积搜索(MIPS)检索用户可能与之交互的下一个商品候选项。相比之下,本文的新型生成式检索框架直接使用序列到序列模型逐标记预测商品的语义ID。
4.2.2 推荐性能
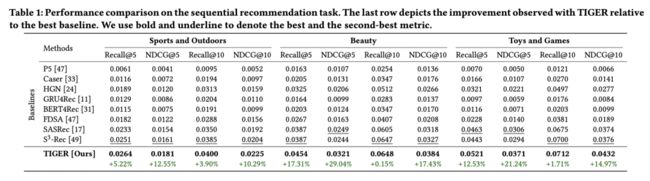
作者对提出的TIGER在序列推荐任务上进行了广泛的分析,并与几个最近的基准模型进行了比较。结果如表1所示。TIGER始终优于现有的基线。所有三个基准测试中,都有显着的提高。特别是在美容基准测试上,TIGER比第二好的基线表现明显更好,在NDCG@5方面提高了高达29%,比SASRec和在Recall@5方面提高了17.3%比S3-Rec。同样,在玩具和游戏数据集上,TIGER在NDCG@5和NDCG@10方面分别比其他模型提高了21%和15%。
4.3商品表示
在这一部分中,分析RQ-VAE语义ID的一些重要特征。特别地,首先进行定性分析,观察语义ID的分层性质。接下来,通过与另一种基于哈希的量化方法进行对比来评估使用RQ-VAE进行量化的设计选择的重要性。最后,进行消融实验,通过将TIGER与使用随机ID进行商品表示的序列到序列模型进行比较,研究使用语义ID的重要性。
4.3.1 定性分析
分析了RQ-VAE语义ID在亚马逊美容数据集中的学习结果,如图4所示。
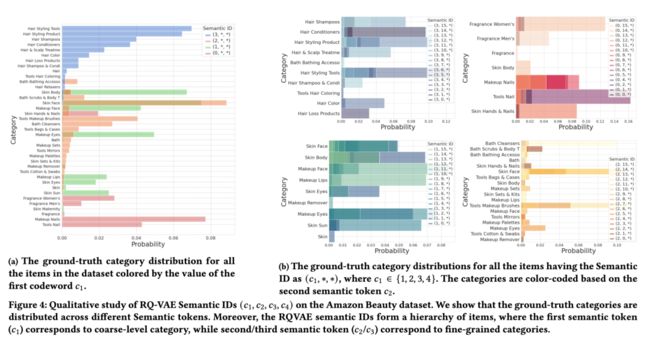
4.3.2 Hashing和RQ-VAE语义ID生成的比较
通过使用局部敏感哈希(LSH)来比较RQ-VAE和LSH语义ID的生成的方法,来研究RQ-VAE在我们的框架中的重要性。结果表明,RQ-VAE始终优于LSH。这表明,通过非线性的深度神经网络(DNN)架构学习语义ID会比使用随机映射更好地量化,给定相同的基于内容的语义嵌入。
4.3.3 随机ID与语义ID的比较
语义ID始终优于随机ID基线,突显了利用基于内容的语义信息的重要性。
4.4 新功能
生成型检索框架中产生的新功能,即冷启动推荐和推荐多样性。作者将这些功能称为“新”,因为现有的序列推荐模型不能直接用于满足这些实际用例。作者认为这些功能源自于RQ-VAE的语义ID和框架的生成型检索方法之间的协同效应。
4.4.1 冷启动推荐
由于真实世界推荐语料库的快速变化,不断引入新的item。由于新增item在训练数据中没有用户表达,因此使用随机原子ID表示item的现有推荐模型无法检索新item作为潜在候选集。相反,TIGER可以轻松地以端到端方式执行冷启动推荐。
对于这个分析,考虑了来自Amazon Reviews的Beauty dataset。为了模拟新增item,我们从训练数据集中删除5%的测试项。将这些删除的项称为未看到的item。从训练集中删除这些item可确保不存在关于未看到的item的数据泄漏。与之前一样,使用长度为4的语义ID来表示item,其中前面三个tokens使用RQ-VAE生成,第4个token用于确保所见到的所有item存在唯一ID。在训练分裂上训练RQ-VAE量化器和序列到序列模型。训练完成后,使用RQ-VAE模型生成包括项语义ID的数据集中的所有item,包括任何未看到的item。
给定模型预测的语义ID(1,2,3,4),我们检索具有相同对应ID的已看到的item。根据定义,每个模型预测的语义ID最多可以与训练数据集中的一个item相匹配。此外,与前三个语义标记相同的未看到的item(1,2,3)包含在检索到的候选集列表中。最后,当检索一组前K个候选项时,文中引入一个超参数,该参数指定最大比例的未看到的item被选择。
在图5中将TIGER与K最近邻(KNN)方法在冷启动推荐设置中的性能进行了比较。

对于KNN,使用语义表示空间来执行最近邻搜索。我们将基于KNN的基线称为Semantic_KNN。图5a表明,本文得框架在=0.1的情况下始终优于所有Re call@K指标的Semantic_KNN。在图5b中,作者对本文的方法和Semantic_KNN在各种值下进行了比较。对于所有≥0.1的设置,本文的方法都优于基线。
4.4.2 推荐多样性
虽然Recall和NDCG是评估推荐系统的主要指标,但预测多样性也是另一个重要的目标。预测多样性较差的推荐系统可能对用户的长期参与造成损害。在本节中,将讨论如何使用我们的生成检索框架来预测多样性item。作者展示了在解码过程中基于温度系数的采样可以有效地用于控制模型预测的多样性。虽然基于温度系数的采样可以应用于任何现有的推荐模型,但由于RQ-VAE语义ID的属性,TIGER允许在各种层次上进行采样。例如,采样语义ID的第一个token允许从粗略级别的类别中检索项,而采样第二/第三个token允许在类别内采样item。
我们使用熵@K指标定量地衡量预测多样性,对于模型预测的前K个item中ground-truth类别分布计算熵值。在表5中报告了各种温度系数值的熵@K。在解码阶段使用基于温度系数的采样可以有效地增加item的分类多样性。

5 讨论
无效ID。由于模型自回归地解码目标语义ID的代码字,因此有可能模型会预测出无效的ID(即,它可能不映射到推荐数据集中的任何item)。在实验中,使用长度为4的语义ID,其中每个代码字具有256的基数(即,每个级别的码本大小= 256)。通过这个组合可能产生的ID数量= 2564,大约为4万亿。另一方面,数据集中的项目数为10K-20K(见表2)。尽管有效ID的数量只是整个ID空间的一小部分,但观察到模型几乎总是预测有效ID。在图6中将TIGER产生的无效ID的比例可视化为检索item数的函数。

语义ID长度和码本大小的影响。作者尝试了改变语义ID长度和码本大小,例如,使用由大小为64的码本中的6个代码字组成的ID。我们注意到,TIGER的推荐指标对这些变化具有鲁棒性。但是,输入序列长度随着更长的ID(即,每个ID的代码字更多)而增加,这使得基于Transformer的序列到序列模型的计算变得更加昂贵。
推理成本。尽管作者提出的模型在序列推荐任务上取得了显著成功,但在推理期间(而非训练期间),本文模型比基于ANN的模型更昂贵,因为使用beam搜索进行自回归解码。
6 结论
本文提出了一种新的范式,称为TIGER,使用生成模型检索推荐系统中的候选集。支持此方法的是一种新颖的用于item的语义ID表示,它使用分层量化器(RQ-VAE)在内容嵌入上生成形成语义ID的token。方法是端到端的,即可以使用单个模型进行训练和服务,而无需创建索引 - Transformer存储器充当索引。本文的嵌入表的基数不会线性增长,这对于需要在训练期间创建大型嵌入表或为每个单个项生成索引的系统来说是有利的。通过对三个数据集的实验,展示了本文的模型可以实现SOTA结果,并能够很好地推广到新的和未知的项目。