NeRF 其二:Mip-NeRF
NeRF 其二:Mip-NeRF
- 1. 混叠
-
- 图像中的混叠现象
- 2. 如何抗混叠
- 3. NeRF 中的解决方案
- 4. 圆锥台近似计算与集成位置编码
-
- 4.1 圆锥台采样
- 4.2 三维高斯逼近圆锥台
- 4.3 集成位置编码
- 5. Mip-NeRF 与 NeRF 的比较
-
- 5.1 位置编码与集成位置编码
- 5.2 采样差异
- 5.3 网络数量
Reference:
- 深蓝学院:NeRF基础与常见算法解析
系列文章:
- NeRF 其一:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- NeRF 其二:Mip-NeRF
- NeRF 其三:Instant-NGP
相关文章:
- 3DGS 其一:3D Gaussian Splatting for Real-Time Radiance Field Rendering
相比于 NeRF,Mip-NeRF 主要是在视觉上的改进。混叠会造成视觉质量的下降,将抗混叠应用到 NeRF 里,就生成了 Mip-NeRF。至于什么是混叠,让我们接着看看。
1. 混叠
介绍混叠之前,要介绍一个词:采样,因为混叠是伴随着采样而产生的。
奈奎斯特准则:假设信号的最大频率为 B B B,信号的采样频率为 f s f_s fs,则奈奎斯特率(Nyquist rate)为 2 B 2B 2B,奈奎斯特准则是 f s > 2 B f_s>2B fs>2B 时原始信号采样后不会丢失信息。混叠:当采样频率设置不合理时,即采样频率 f s f_s fs 低于 2 2 2 倍的信号频率( f s < 2 B f_s<2B fs<2B),会导致原本的高频信号被采样成低频信号。这种频谱的重叠导致的失真称为混叠,也就是高频信号被混叠成了低频信号。
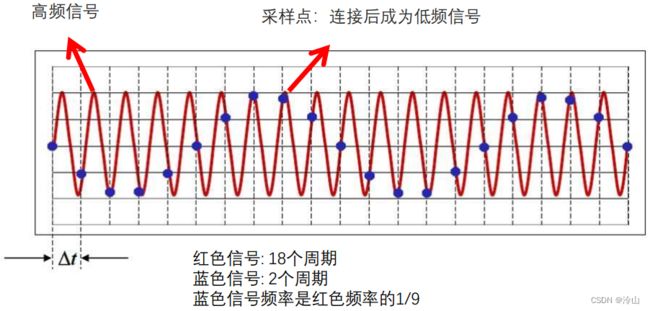 在图中以 Δ t \Delta _t Δt 的时间间隔去采样,可以得到蓝色点。很显然蓝色信号的频率只有红色信号频率的 1 / 9 1/9 1/9,本身的红色信号是一个高频信号,被采样成了一个低频信号。这样就会导致混叠:
在图中以 Δ t \Delta _t Δt 的时间间隔去采样,可以得到蓝色点。很显然蓝色信号的频率只有红色信号频率的 1 / 9 1/9 1/9,本身的红色信号是一个高频信号,被采样成了一个低频信号。这样就会导致混叠:
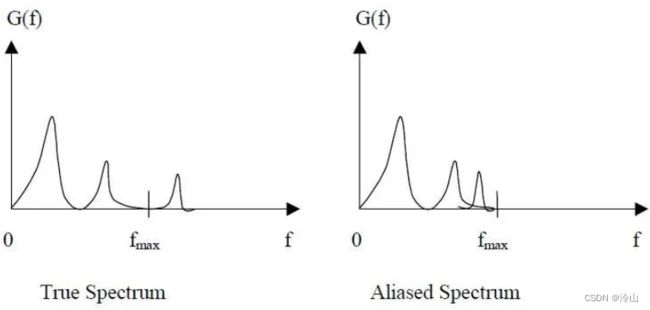 图中的 f m a x f_{max} fmax 为现在采样频率的 1 / 2 1/2 1/2,即 f s 2 \frac{f_s}{2} 2fs。
图中的 f m a x f_{max} fmax 为现在采样频率的 1 / 2 1/2 1/2,即 f s 2 \frac{f_s}{2} 2fs。
- 当原始信号频率< f s 2 \frac{f_s}{2} 2fs时,即 f s > 2 B f_s > 2B fs>2B,没有问题;
- 当原始信号频率> f s 2 \frac{f_s}{2} 2fs时,会导致将高出来的频率部分高频信号采样成低频,原始的低频很好的保留了,而高频这部分采样成了低频,和原始的低频信号有了混合,这就是混叠。
只有在采样的问题下(采样频率不合适的情况下)才会产生混叠的概念。
图像中的混叠现象
-
锯齿
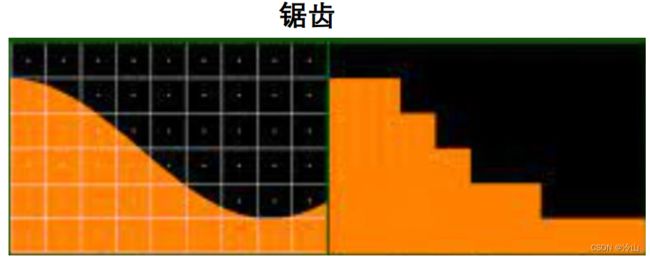 本来图中很细腻的图像,比如将 320 × 240 320\times 240 320×240 采样成 9 × 6 9\times 6 9×6 的图像。在采样率不够的时候就会产生一个个的锯齿。
本来图中很细腻的图像,比如将 320 × 240 320\times 240 320×240 采样成 9 × 6 9\times 6 9×6 的图像。在采样率不够的时候就会产生一个个的锯齿。 -
摩尔纹
 在左图采样率好的时候,墙面采样的很好没有产生多的东西,而当采样率设置不正确的时候,就会产生摩尔纹。原始信号是不会长这样的,这是与低频信号混叠后导致的。
在左图采样率好的时候,墙面采样的很好没有产生多的东西,而当采样率设置不正确的时候,就会产生摩尔纹。原始信号是不会长这样的,这是与低频信号混叠后导致的。
2. 如何抗混叠
抗混叠有以下两种方式:
- 增加采样频率:提高采样频率可以使信号频率 B B B 不会超过采样频率 f s f_s fs 的一半,从而避免混叠的发生。
- 使用低通滤波器:将信号通过低通滤波器,可以去除信号中高于采样频率一半的频率分量,从而避免混叠。
首先从第一种情况说起:如果采样率已经定下来了,比如上一节锯齿的图像,就想使用 9 × 6 9\times6 9×6 的图像,这时候可以考虑在左图中每个框内都多采一些点,然后合并到右图,就可以让右图每个点的均值平滑一点,而不会像现在右图所示这样生硬。这种方式的缺点在于格子中那么多点得到的一个平均,效率就很低下。这就引出了第二种方法。
使用低通滤波器可以直接将超过的频率剔除掉后再采样,就不会有摩尔纹、锯齿这样的情况了。
大图像没有经过一些技术处理的采样采样,就会得到下面这样的结果。近处还好,远处出现了很明显的摩尔纹:
 造成摩尔纹的原因是采样频率过低,既然采样频率不好控制,那么解决方案为:在采样之前,使用低通滤波器去除高于采样频率一半的频率分量。
造成摩尔纹的原因是采样频率过低,既然采样频率不好控制,那么解决方案为:在采样之前,使用低通滤波器去除高于采样频率一半的频率分量。
去除噪声可以用到低通滤波器。噪声点和邻居长得不太像,它属于高频信息,当然除了噪声点外,图像边缘也是高频信息。
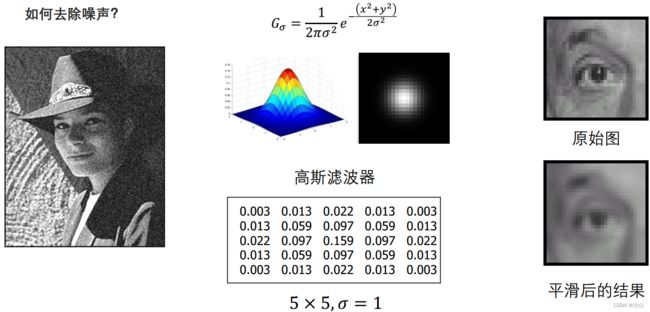 在使用低通滤波器后再进行采样,图像就正常了:
在使用低通滤波器后再进行采样,图像就正常了:
但在这里又有一个问题是,假设我们有一个物体,在相机从近往远的过程中,这个杯子所有的像素在这个相机的成像图像上所占像素会越来越小,也就意味着从高分辨率一点点往低分辨率采。如果每采一次,都需要对图像做一次低通滤波,然后再去采样,这样效率就会很差。这个系统的性能就会非常的弱。为了解决这个问题,就引入了一个新的概念,叫做 MipMap。
 MipMap 的做法是,先将一张大图生成一系列的小图像。在原来方法内每移动一次距离都需要 平滑+采样,这样太慢。MipMap 会将几个尺度的 平滑+采样 的图先存下来,将来相机拉到某一尺度时,就会从一个分辨率接近的图再去做处理,因为分辨率接近,这时候就不需要再做低通滤波了,也就不会再出现混叠的问题。
MipMap 的做法是,先将一张大图生成一系列的小图像。在原来方法内每移动一次距离都需要 平滑+采样,这样太慢。MipMap 会将几个尺度的 平滑+采样 的图先存下来,将来相机拉到某一尺度时,就会从一个分辨率接近的图再去做处理,因为分辨率接近,这时候就不需要再做低通滤波了,也就不会再出现混叠的问题。
3. NeRF 中的解决方案
下图展示了原始 NeRF 模型,在摄像机往远离物体的方向移动时,渲染结果存在混叠。每张图下的小数代表 SSIM,是与真值间的距离,值越大,表示模型生成的越好。
 为了将下面一行的图像看清,将小图放大到和上面大图一样,实际只有前面的 1 / 8 1/8 1/8。
为了将下面一行的图像看清,将小图放大到和上面大图一样,实际只有前面的 1 / 8 1/8 1/8。
- 第一列为相近视角下生成的模型,可以看到全分辨率的图像 SSIM 值挺高,而降低分辨率后产生了鬼影,导致了视觉质量下降的相当明显;
- 第二列将近距离视角和远距离视角混在一起训练来生成模型。这样对远处的 SSIM 确实有提升,但是原来近距离的质量出现出现了下降,这并不是所希望的。
为什么会出现这种现象呢?
因为同一个像素在不同距离上看,颜色是不一样的。下图内黄色为一个像素,当物体比较近的时候,像素是由近处时的物体投影过去的;当物体距离相机比较远时,需要把图像后面把物体更大一块映射到这个像素上(它包含了更多的内容)。假设前面一个映射到像素上的颜色为 C C C;后面一个像素映射为 C ′ C' C′,很明显 C C C 和 C ′ C' C′ 的颜色不一样。
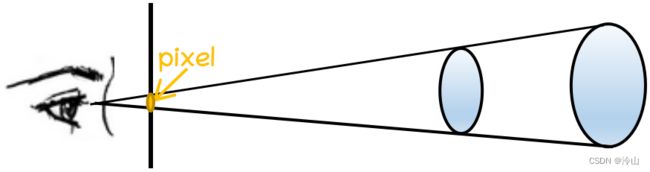
而如果在传统 NeRF 的情况下,因为视线 d d d 上同一位置的体密度和颜色值是一样的,所以训练出来的 C C C 和 C ′ C' C′ 的颜色应该是一样的。而真实情况下,这两个像素的颜色是不一样的。
 使用不同距离一起训练 NeRF,会使网络学出来一个中间值,它既不趋近 C C C,也不趋近 C ′ C' C′。
使用不同距离一起训练 NeRF,会使网络学出来一个中间值,它既不趋近 C C C,也不趋近 C ′ C' C′。
那么前面我们在抗混叠的方式中提到了 增加采样频率的方法------超采样。做法是一个像素点多采样几个光线,将每个像素的体渲染和颜色的结果做一个加权平均,来得到当前像素点结果。但是需要知道的是,辐射场上一条光线的速度已经很慢了,一个像素要是计算多条光线那计算量是不能接受的,所以超采样这条路走不通。
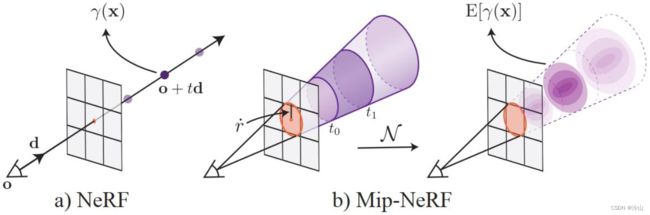 现在考虑另一种抗混叠方案:使用低通滤波器,即 使用圆锥体取代光线:NeRF 一条射线对应 Mip-NeRF 一个圆锥体,NeRF 一个采样点对应 Mip-NeRF 一个圆锥截台。
现在考虑另一种抗混叠方案:使用低通滤波器,即 使用圆锥体取代光线:NeRF 一条射线对应 Mip-NeRF 一个圆锥体,NeRF 一个采样点对应 Mip-NeRF 一个圆锥截台。
这种方法与超采样的打很多条光线相近,思路为 ①:将圆台内的每一个点都送入神经网络,并由 γ ( x 1 ) \gamma(x_1) γ(x1)、 γ ( x 2 ) \gamma(x_2) γ(x2)… γ ( x n ) \gamma(x_n) γ(xn) 得到 σ 1 c 1 \sigma_1c_1 σ1c1、 σ 2 c 2 \sigma_2c_2 σ2c2… σ n c n \sigma_nc_n σncn,最后求一个加权平均,得到 σ ˉ \bar{\sigma} σˉ 和 c ˉ \bar{c} cˉ。它相比原来的好处是考虑了邻域信息的的加权求和,相比 NeRF 方法会更加平滑。但因为每一个点都得走一次神经网络,这里的算力并没有减小。
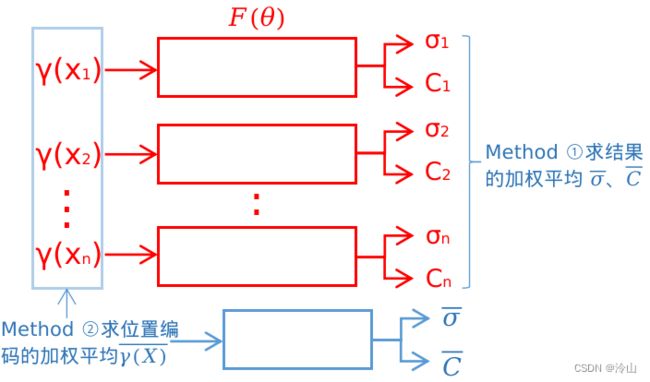
于是就有了这种方法的进阶版 ②:既然会对神经网络的结果做一个加权平均,那么现在直接对多个 γ ( x ) \gamma(x) γ(x) 做一次平均,把这个值输入到神经网络 F ( θ ) F(\theta) F(θ) 内,最终得到的值应该也是逼近 σ ˉ \bar{\sigma} σˉ 和 c ˉ \bar{c} cˉ 的。
这种成像过程相比 NeRF 更为真实。
4. 圆锥台近似计算与集成位置编码
4.1 圆锥台采样
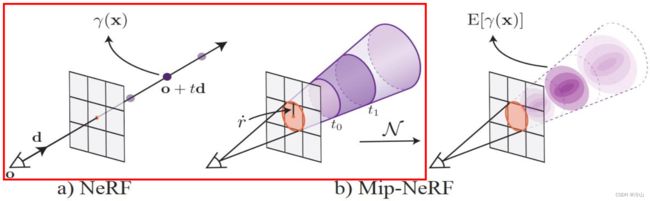
在上一节末我们想实现的方法为:对圆锥台范围内的 γ ( x ) \gamma(x) γ(x) 求加权平均,即求取圆锥台里面每个位置编码的期望值,那么就需要搞清楚,哪些点是属于当前圆台的:
若 x \boldsymbol{x} x 位于由相机位置 o \boldsymbol{o} o、视线方向 d \boldsymbol{d} d、圆台半径 r ˙ \dot{r} r˙、以及圆台深度区间 [ t 0 , t 1 ] [t_0, t_1] [t0,t1] 定义的圆台中,定义 F ( x , ⋅ ) = 1 F(\boldsymbol{x},\cdot)=1 F(x,⋅)=1,
F ( x , o , d , r ˙ , t 0 , t 1 ) = 1 { ( t 0 < d T ( x − o ) ∥ d ∥ 2 < t 1 ) ∧ ( d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 > 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 ) } {F\left(\boldsymbol{x}, \boldsymbol{o}, \boldsymbol{d}, \dot{r}, t_{0}, t_{1}\right)=1\left\{\left(t_{0}<\frac{\boldsymbol{d}^{T}(\boldsymbol{x}-\boldsymbol{o})}{\|\boldsymbol{d}\|_{2}}
-
① t 0 < d T ( x − o ) ∥ d ∥ 2 < t 1 t_{0}<\frac{\boldsymbol{d}^{T}(\boldsymbol{x}-\boldsymbol{o})}{\|\boldsymbol{d}\|_{2}}
-
② d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 > 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 \frac{\boldsymbol{d}^{T}(\boldsymbol{x}-\boldsymbol{o})}{\|\boldsymbol{d}\|_{2}\|\boldsymbol{x}-\boldsymbol{o}\|_{2}}>\frac{1}{\sqrt{1+\left(\dot{r} /\|\boldsymbol{d}\|_{2}\right)^{2}}} ∥d∥2∥x−o∥2dT(x−o)>1+(r˙/∥d∥2)21:左边和公式 ① 近似,这里多除了一个 ∥ x − o ∥ 2 \|\boldsymbol{x}-\boldsymbol{o}\|_{2} ∥x−o∥2,表示这里计算的是教教的余弦值。右式可从下图中得到:
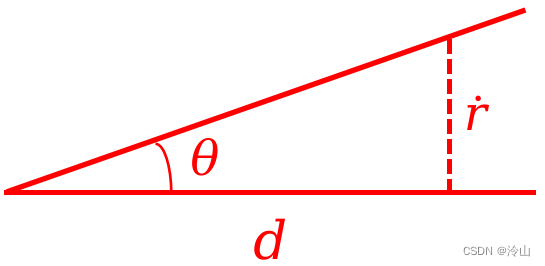 即 cos θ = ∥ d ∥ 2 d 2 + ( r ˙ ) 2 = 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 \cos\theta=\frac{\|\boldsymbol{d}\|_{2}}{\sqrt{\boldsymbol{d}^2+\left(\dot{r} \right)^{2}}}=\frac{1}{\sqrt{1+\left(\dot{r} /\|\boldsymbol{d}\|_{2}\right)^{2}}} cosθ=d2+(r˙)2∥d∥2=1+(r˙/∥d∥2)21
即 cos θ = ∥ d ∥ 2 d 2 + ( r ˙ ) 2 = 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 \cos\theta=\frac{\|\boldsymbol{d}\|_{2}}{\sqrt{\boldsymbol{d}^2+\left(\dot{r} \right)^{2}}}=\frac{1}{\sqrt{1+\left(\dot{r} /\|\boldsymbol{d}\|_{2}\right)^{2}}} cosθ=d2+(r˙)2∥d∥2=1+(r˙/∥d∥2)21又因为 cos \cos cos 越大角度越小,所以这里得到的是两夹角的范围。
综上,整个公式的就将三维点区间限制在了圆台内。
圆锥台位置编码的期望可以定义为:
γ ∗ ( o , d , r ˙ , t 0 , t 1 ) = ∫ γ ( x ) F ( x , o , d , r ˙ , t 0 , t 1 ) d x ∫ F ( x , o , d , r ˙ , t 0 , t 1 ) d x {\gamma^{*}\left(\boldsymbol{o}, \boldsymbol{d}, \dot{r}, t_{0}, t_{1}\right)=\frac{\int \gamma(\boldsymbol{x}) F\left(\boldsymbol{x}, \boldsymbol{o}, \boldsymbol{d}, \dot{\boldsymbol{r}}, t_{0}, t_{1}\right) d x}{\int F\left(\boldsymbol{x}, \boldsymbol{o}, \boldsymbol{d}, \dot{r}, t_{0}, t_{1}\right) d x}} γ∗(o,d,r˙,t0,t1)=∫F(x,o,d,r˙,t0,t1)dx∫γ(x)F(x,o,d,r˙,t0,t1)dx可知这里的 γ ∗ = E ( γ ( x ) ) \gamma^*=E(\gamma(\boldsymbol{x})) γ∗=E(γ(x)),分子为圆台内位置编码的和,分母为圆台内总个数。因为这里是对圆台内所有位置的积分,所以这个位置编码又称为 集成位置编码。
那么问题又来了,上面这个公式的计算是非常不容易的,所以需要对它做近似。
4.2 三维高斯逼近圆锥台
因为圆台不好算,所以用一个三维高斯球逼近圆台,让这个三维高斯球里包含的 x \boldsymbol{x} x 个数尽量和圆台内的重叠。这样做是因为使用高斯来计算 γ ( x ) \gamma(\boldsymbol{x}) γ(x) 的期望值是很容易的。(这里应该就不是平均,而是加权平均了吧,即中心点的权重会更高)
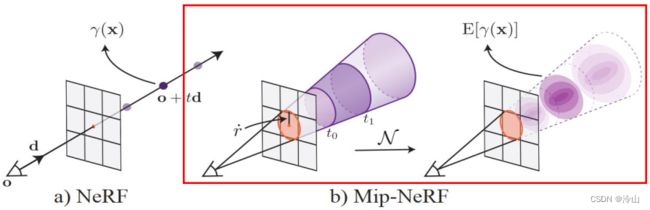 定义 μ t \mu_t μt 表示对应圆锥截台到相机的平均距离, σ t 2 \sigma_t^2 σt2 为沿光线方向的距离方差, σ r 2 \sigma_r^2 σr2 为垂直于光线方向的距离方差:
定义 μ t \mu_t μt 表示对应圆锥截台到相机的平均距离, σ t 2 \sigma_t^2 σt2 为沿光线方向的距离方差, σ r 2 \sigma_r^2 σr2 为垂直于光线方向的距离方差:
μ t = t μ + 2 t μ t δ 2 3 t μ 2 + t δ 2 σ t 2 = t δ 2 3 − 4 t δ 4 ( 12 t μ 2 − t δ 2 ) 15 ( 3 t μ 2 + t δ 2 ) 2 σ r 2 = r ˙ 2 ( t μ 2 4 + 5 t δ 2 12 − 4 t δ 4 15 ( 3 t μ 2 + t δ 2 ) ) {\mu_{t}=t_{\mu}+\frac{2 t_{\mu} t_{\delta}^{2}}{3 t_{\mu}^{2}+t_{\delta}^{2}} \quad \sigma_{t}^{2}=\frac{t_{\delta}^{2}}{3}-\frac{4 t_{\delta}^{4}\left(12 t_{\mu}^{2}-t_{\delta}^{2}\right)}{15\left(3 t_{\mu}^{2}+t_{\delta}^{2}\right)^{2}} \quad \sigma_{r}^{2}=\dot{r}^{2}\left(\frac{t_{\mu}^{2}}{4}+\frac{5 t_{\delta}^{2}}{12}-\frac{4 t_{\delta}^{4}}{15\left(3 t_{\mu}^{2}+t_{\delta}^{2}\right)}\right)} μt=tμ+3tμ2+tδ22tμtδ2σt2=3tδ2−15(3tμ2+tδ2)24tδ4(12tμ2−tδ2)σr2=r˙2(4tμ2+125tδ2−15(3tμ2+tδ2)4tδ4)其中, t μ = ( t 0 + t 1 ) / 2 t_\mu=(t_0+t_1)/2 tμ=(t0+t1)/2, t δ = ( t 1 1 − t 0 ) / 2 t_\delta=(t1_1-t_0)/2 tδ=(t11−t0)/2, r ˙ \dot{r} r˙ 设置为 1 / 3 1/\sqrt{3} 1/3 倍的像素大小。详细推导请浏览原论文。
 从图中可以看出, μ t \mu_t μt、 σ t 2 \sigma_t^2 σt2、 σ r 2 \sigma_r^2 σr2 三个值确定了,高斯球也就确定下来了。
从图中可以看出, μ t \mu_t μt、 σ t 2 \sigma_t^2 σt2、 σ r 2 \sigma_r^2 σr2 三个值确定了,高斯球也就确定下来了。
那么为什么要将 r ˙ \dot{r} r˙,即圆台半径设置为 1 / 3 1/\sqrt{3} 1/3 倍的像素大小(单位像素面积)呢?
Ans:圆的面积为 π r 2 = 1 → r = 1 π ≈ 1 / 3 \pi r^2=1\rightarrow r=\frac{1}{\sqrt{\pi}}\approx1/\sqrt{3} πr2=1→r=π1≈1/3
还要将圆台从圆台坐标转换到世界坐标系:
μ = o + μ t d , Σ = σ t 2 ( d d T ) + σ r 2 ( I − d d T ∥ d ∥ 2 2 ) \boldsymbol{\mu} = \boldsymbol{o} + \mu_t\boldsymbol{d},\quad \Sigma=\sigma_t^2(\boldsymbol{d}\boldsymbol{d}^T)+\sigma_r^2(\boldsymbol{I}-\frac{\boldsymbol{d}\boldsymbol{d}^T}{\|\boldsymbol{d}\|_2^2}) μ=o+μtd,Σ=σt2(ddT)+σr2(I−∥d∥22ddT)其中, o \boldsymbol{o} o 表示相机位置, d \boldsymbol{d} d 表示观察方向。
这里得到的 μ \boldsymbol{\mu} μ 就是 E ( X ) E(X) E(X),但是我们要求的是 E ( γ ( X ) ) E(\gamma(X)) E(γ(X)),所以接下来继续介绍集成位置编码的概念。
4.3 集成位置编码
在上一章内提到的 NeRF 的位置编码 如下:
γ ( q ) = ( sin ( 2 0 π q ) , cos ( 2 0 π q ) , ⋯ , sin ( 2 L − 1 π q ) , cos ( 2 L − 1 π q ) ) \gamma(q)=\left(\sin \left(2^0 \pi q\right), \cos \left(2^0 \pi q\right), \cdots, \sin \left(2^{L-1} \pi q\right), \cos \left(2^{L-1} \pi q\right)\right) γ(q)=(sin(20πq),cos(20πq),⋯,sin(2L−1πq),cos(2L−1πq))该公式在计算上还是比较麻烦,所以想采用一种更简洁的形式表示。
将位置编码写为矩阵的形式:
P = [ 1 0 0 2 0 0 2 L − 1 0 0 0 1 0 0 2 0 ⋯ 0 2 L − 1 0 0 0 1 0 0 2 0 0 2 L − 1 ] T , γ ( x ) = [ sin ( P x ) cos ( P x ) ] \mathbf{P}=\begin{bmatrix}1&0&0&2&0&0&&2^{L-1}&0&0\\0&1&0&0&2&0&\cdots&0&2^{L-1}&0\\0&0&1&0&0&2&&0&0&2^{L-1}\end{bmatrix}^\mathrm{T}, \gamma(x)=\begin{bmatrix}\sin(Px)\\\cos(Px)\end{bmatrix} P= 100010001200020002⋯2L−10002L−10002L−1 T,γ(x)=[sin(Px)cos(Px)] P P P 的维度为 3 L × 3 3L\times3 3L×3, x \boldsymbol{x} x 的维度为 3 × 1 3\times1 3×1,最终 P x P\boldsymbol{x} Px 的维度 3 L × 1 3L\times1 3L×1,与原 NeRF 保持一致。
与原位置编码的差异如下:
- 常数 π \pi π 被干掉了,前面只是从周期的角度理解,加上 π \pi π 更自然,但一个固定量对性能的影响并不大;
- 原 NeRF 是以 sin \sin sin、 cos \cos cos、 sin \sin sin、 cos . . . \cos... cos... 的排列方式。现在将 sin \sin sin 放在一起,然后将 cos \cos cos 放在一起,这种形式更简单。
已知:
E ( γ ( x ) ) = [ E ( sin ( P x ) ) E ( cos ( P x ) ) ] = [ E ( sin ( p 1 ) ) E ( sin ( p 2 ) ) ⋮ E ( cos ( p n ) ) ] E(\gamma(x))=\begin{bmatrix}E(\sin(Px))\\E(\cos(Px))\end{bmatrix}=\begin{bmatrix}E(\sin(p_1))\\E(\sin(p_2))\\ \vdots \\E(\cos(p_n))\end{bmatrix} E(γ(x))=[E(sin(Px))E(cos(Px))]= E(sin(p1))E(sin(p2))⋮E(cos(pn)) 当 p p p 服从高斯分布时,计算 sin ( p ) \sin (p) sin(p) 和 cos ( p ) \cos (p) cos(p) 的期望:
E p ∼ N ( μ , σ 2 ) [ s i n ( p ) ] = s i n ( μ ) e x p ( − ( 1 2 ) σ 2 ) E p ∼ N ( μ , σ 2 ) [ c o s ( p ) ] = c o s ( μ ) e x p ( − ( 1 2 ) σ 2 ) \begin{aligned}E_{p\sim\mathcal{N}(\mu,\sigma^2)}[sin(p)]&=sin(\mu)exp(-(\frac12)\sigma^2)\\E_{p\sim\mathcal{N}(\mu,\sigma^2)}[cos(p)]&=cos(\mu)exp(-(\frac12)\sigma^2)\end{aligned} Ep∼N(μ,σ2)[sin(p)]Ep∼N(μ,σ2)[cos(p)]=sin(μ)exp(−(21)σ2)=cos(μ)exp(−(21)σ2)这样就知道了每一项的计算方式,但这时还没有考虑 P P P 带来的影响。
将高斯分布映射到经过位置编码后的空间:
μ γ = P μ , Σ γ = P Σ P T (对角矩阵) \boldsymbol{\mu_\gamma}=\mathbf{P}\boldsymbol{\mu}, \quad \Sigma_\gamma=\mathbf{P}\Sigma\mathbf{P}^T \text{(对角矩阵)} μγ=Pμ,Σγ=PΣPT(对角矩阵)那么集成位置编码 γ ( μ , Σ ) \gamma(\boldsymbol{\mu},\Sigma) γ(μ,Σ) 的期望计算公式如下,其中 ∘ \circ ∘ 表示逐元素相乘, d i a g diag diag 表示取对角线元素:
γ ( μ , Σ ) = E x ∼ N ( μ γ , Σ γ ) [ γ ( x ) ] = [ sin ( μ γ ) ∘ exp ( − ( 1 2 ) d i a g ( Σ γ ) ) cos ( μ γ ) ∘ exp ( − ( 1 2 ) d i a g ( Σ γ ) ) ] \gamma(\mu,\Sigma)=E_{x\sim\mathcal{N}(\mu_{\gamma},\Sigma_{\gamma})}[\gamma(x)]=\begin{bmatrix}\sin(\boldsymbol{\mu}_{\gamma})\circ\exp(-(\frac{1}{2})diag(\Sigma_{\gamma}))\\\\\cos(\boldsymbol{\mu}_{\gamma})\circ\exp(-(\frac{1}{2})diag(\Sigma_{\gamma}))\end{bmatrix} γ(μ,Σ)=Ex∼N(μγ,Σγ)[γ(x)]= sin(μγ)∘exp(−(21)diag(Σγ))cos(μγ)∘exp(−(21)diag(Σγ)) 集成位置编码 γ ( x ) \boldsymbol{\gamma(x)} γ(x) 的方差计算公式:
d i a g ( Σ γ ) = [ d i a g ( Σ ) , 4 d i a g ( Σ ) , … , 4 L − 1 d i a g ( Σ ) ] T d i a g ( Σ ) = σ t 2 ( d ∘ d ) + σ r 2 ( 1 − d ∘ d ∥ d ∥ 2 2 ) \begin{aligned}diag(\Sigma_\gamma)&=[diag(\Sigma),4diag(\Sigma),\ldots,4^{L-1}diag(\Sigma)]^T\\diag(\Sigma)&=\sigma_t^2(\boldsymbol{d}\circ \boldsymbol{d})+\sigma_r^2(\boldsymbol{1}-\frac{\boldsymbol{d}\circ \boldsymbol{d}}{\|\boldsymbol{d}\|_2^2})\end{aligned} diag(Σγ)diag(Σ)=[diag(Σ),4diag(Σ),…,4L−1diag(Σ)]T=σt2(d∘d)+σr2(1−∥d∥22d∘d)
5. Mip-NeRF 与 NeRF 的比较
5.1 位置编码与集成位置编码
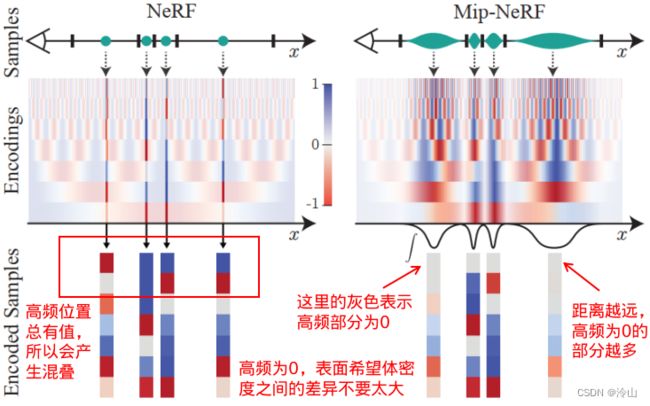
- NeRF:
位置编码,从图中可以看到,高频位置总是有值,所以会产生混叠; - Mip-NeRF:
集成位置编码,理论上越往前的圆锥台越小,就越有可能近似到一个点上(当然遇到空气等另说)。越小的时候,积分区域就越小,表明累加得圆锥台越小,就越容易落到一个点上,高频区域就会有信号值;距离远的时候,平均的数量就变多了,本来差别很大的,就给拉平了,导致更不容易学到高频信息,越高频越没有值-----这样就可以自适应的调节了。
5.2 采样差异
- NeRF:以传统方式看一个点,图中都是一个个小圆点,远处和近处看到的都是一样的;
- Mip-NeRF:看到的圆锥台大小都不一样,说明近处看远处看这个点的内容是不一样的。

5.3 网络数量
- NeRF:使用了两套网络,先取粗再取细。一个网络关注粗粒度,另一个关注细粒度。这两个网络如果放在一起,就粗不粗细不细;
- Mip-NeRF:因为使用了圆锥台的概念,所有的区域位置信息都会被利用上,所以就没有必要再用两套网络。