Pandas数据分析详解(二)
1.索引
1.1重新设置索引
import pandas as pd
s=pd.Series(data=[1,2,3],index=[0,1,2])
print(s)
#重新设置索引
print(s.reindex(range(1,6)))#注意此时原数据行索引0被舍弃了,因为不匹配
#多的用0填充
print(s.reindex(range(1,6),fill_value=0))
#向前/后填充
print(s.reindex(range(1,6),method='ffill'))#fill:前 bfill:hou
import pandas as pd
data=[[100,120,125],[105,120,85],[115,135,130]]
index=['ms001','ms002','ms003']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
print(df.reindex(index=['ms001','ms002','ms003','ms004','ms005'],columns=['语文','数学','英语','物理','化学','生物'],fill_value=0))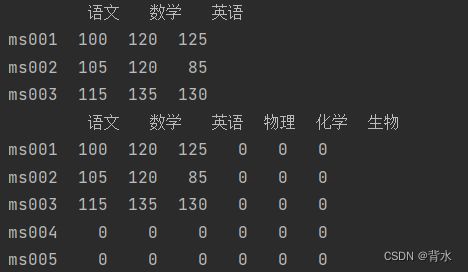
1.2将某一列设置新的索引
DataFrame.set_index(keys, *, drop=True, append=False, inplace=False, verify_integrity=False)
| 参数 | 含义 |
|---|---|
| keys | 作为行标签的列名,可以DataFrame中的是单个列或者多列组成的列表,或者指定的Series |
| drop | 布尔值,默认为True:从DataFrame中删除作为索引的列,当取值为False时,作为索引的列在DataFrame中仍作为数据存在 |
| append | 布尔值,默认为False:用新的keys列替换原来的索引;当取值为True:将指定的新索引列增加到原索引上,形成多层索引 |
| inplace | 布尔值,默认False:创建新的DataFrame;取值为True:修改原DataFrame |
| vertify_integrity | 布尔值,默认为False :不检查索引是否重复 |
import pandas as pd
df=pd.read_excel('d:\JD\Desktop\\trydata.xlsx',)
print(df)
df=df.set_index(['会员名','购买时间'])#双索引
print(df)没有修改前:
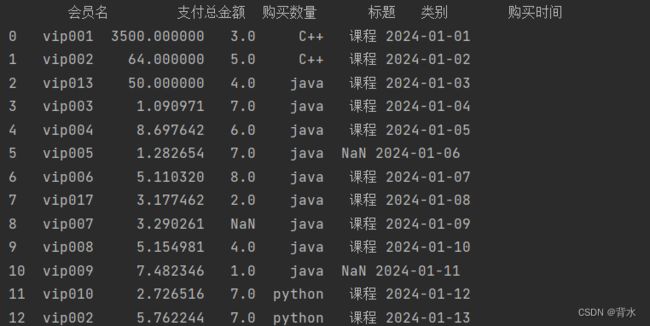
设置索引后:

1.3数据清洗后设置连续索引
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
- drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
- inplace: 是否在原DataFrame上改动,默认为False
- level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列
- col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级
- col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名
import pandas as pd
df=pd.read_excel('d:\JD\Desktop\\trydata.xlsx',)
print(df)
df.dropna(inplace=True)
df=df.reset_index()
print(df)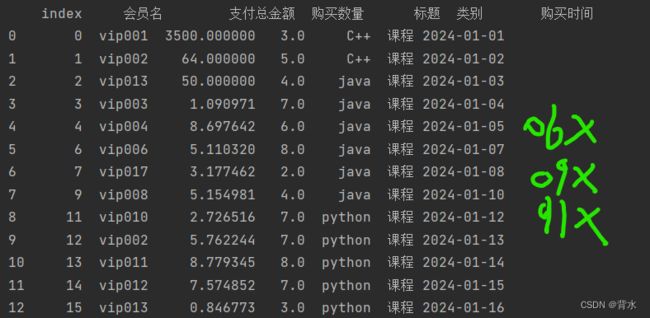
上述清楚后索引变成连续的了。
2.数据排序
2.1sort_values函数
df.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
参数说明
- by :指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
- axis : 若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
- ascending : 是否按指定列的数组升序排列,默认为True,即升序排列
- inplace : 是否用排序后的数据集替换原来的数据,默认为False,即不替换
- na_position : {‘first’,‘last’},设定缺失值的显示位置
2.1rank函数
DataFrame.rank(axis=0, method=‘average’, numeric_only=NoDefault.no_default, na_option=‘keep’, ascending=True, pct=False)
- axis: axis=0为按行排名,axis=1为按列排名
- method: 如何对具有相同价值(即领带)的记录组进行排序:
- average: 组里的平均排名
- min: 组里的最低排名
- max: 组里的最高排名
- first: 按照他们在数组中出现的顺序排列
- dense: 就像’ min '一样,但是在组之间rank总是增加1
- numeric_only: 对于DataFrame对象,如果设置为True,则只对数字列排序。
- na_option: 如何对NaN值进行排序:
- keep: 空值排序仍为空值
- top: 排序放在第一位
- bottom: 排在最后一位
- ascending: 元素按升序/降序排列
- pct: 是否以百分比形式显示返回的排名。
3.数据计算
3.1求和
dataframe.sum(axis, skipna, level, numeric_only, min_count, kwargs)
| 参数 | 值 | 描述 |
|---|---|---|
| axis | 0 1 'index' 'columns' |
可选, 要检查的轴,默认为 0 |
| skip_na | True False |
可选, 默认值 True。 如果结果不应跳过空值,则设置为 False |
| level | Number level name |
可选, 默认值 None。指定要检查的级别(在分层多索引中) |
| numeric_only | None True False |
可选。指定是否仅检查数值 默认值 None |
| min_count | None True False |
可选。 指定执行操作所需的最小值数 默认值 0 |
| kwargs | 可选, 关键字参数。这些参数无效,但可以被 NumPy 函数接受 |
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data=[[90,90,90],[70,80,90],[60,70,80]]
df=pd.DataFrame(data=data,columns=['语文','数学','英语'])
print(df)
df['总成绩']=df.sum(axis=1)
print(df)
4.分组处理
4.1apply
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
func:要应用的函数。它可以是一个 Python 函数,也可以是一个字符串(例如'sum'、'mean'等)。axis:应用函数的轴。如果axis=0(默认值),则函数将沿着列方向应用;如果axis=1,则函数将沿着行方向应用。raw:是否将底层数据传递给函数。如果raw=True,则传递底层 NumPy 数组;否则传递Series对象。result_type:结果类型。可以是'expand'、'reduce'或'broadcast'。args:要传递给函数的额外参数。*kwds:要传递给函数的额外关键字参数。apply函数允许你对DataFrame或Series对象中的数据应用一个函数。它接受一个函数作为参数,并将这个函数应用到对象的每一行或每一列上
import pandas as pd
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data)现在,我们想要计算每一列的平均值。我们可以使用 apply 函数来实现这一点:
result = df.apply(lambda x: x.mean())
print(result)
#结果:
A 2.0
B 5.0
C 8.0
dtype: float64除了计算平均值之外,我们还可以使用 apply 函数来执行其他操作。例如,我们可以使用它来计算每一行的最大值:
result = df.apply(lambda x: x.max(), axis=1)
print(result)
#结果:
0 7
1 8
2 9
dtype: int64还可以使用 apply 函数来对数据进行转换。例如,假设我们想要对 df 中的所有数据都加上一个常数,我们可以使用以下代码:
result = df.apply(lambda x: x + 1)
print(result)
#结果:
A B C
0 2 5 8
1 3 6 9
2 4 7 10对每一列进行归一化,使得每一列的最小值为 0,最大值为 1:
import pandas as pd
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data)
re = df.apply(lambda x: (x - x.min()) / (x.max() - x.min()))
print(re)
4.2map函数
map函数只能处理一列数据,所以不能直接用DataFrame.map。
import pandas as pd
data=[['男'],['男'],['女'],['男']]
df=pd.DataFrame(data=data,columns=['性别'])
df.index=df.index.map(lambda x:x+1)
print(df)
def fun(x):#将男设置为1,女设置为0
if x=='男':
return 1
else:
return 0
df['性别']=df['性别'].map(fun)
print(df)
具体还有很多解释,可以在这篇文章上查看:Pandas数据分析基础—pandas自带函数map()/apply()/applymap()_pandas map-CSDN博客
4.3groupby函数
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=no_default, observed=False, dropna=True):
- by: 指定根据哪个/哪些字段分组,默认值是None,按多个字段分组时传入列表。by参数可以按位置参数的方式传入。
- axis: 设置按列分组还是按行分组,0或index表示按列分组,1或columns表示按行分组,默认值为0。
- level: 当DataFrame的索引为多重索引时,level参数指定用于分组的索引,可以传入多重索引中索引的下标(0,1...)或索引名,多个用列表传入。
level参数不能与by参数同时使用,如果两者同时存在,当by参数传入的是多重索引中的索引,则level不生效,当by参数传入的是DataFrame的列名,则报错。
- as_index: 分组结果默认将分组列的值作为索引,如果按单列分组,结果默认是单索引,如果按多列分组,结果默认是多重索引。将as_index设置为False可以重置索引(0,1...)。
- sort: 结果按分组列的值升序排列,将sort设置为False则不排序,可以提升性能。
- dropna: 默认情况下,分组列的NaN在分组结果中不保留,将dropna设置为False,可以保留NaN分组。
import pandas as pd
data = {
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
'class': ['X', 'X', 'Y', 'Y']
}
df = pd.DataFrame(data)想要计算每个类别中 A 列的平均值:
re = df.groupby('class')['A'].mean()
print(re)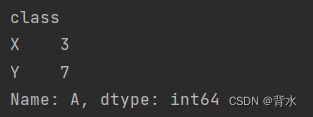
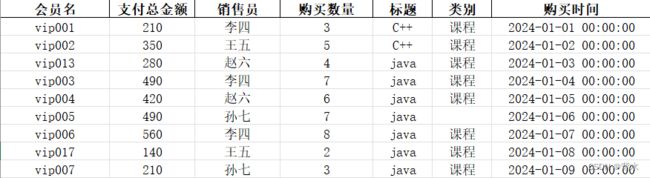
接下来将用一个实例进行讲解,先看要导入的EXCEL文件:
按照一列分组统计
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=data[['支付总金额','购买数量','标题']]#提取有用的三列
print(df.groupby('标题').sum())#按照一列分组统计,注意分组后标签为统计关键字!!!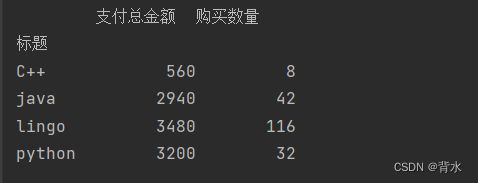
按照多列进行分组
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=data[['支付总金额','销售员','购买数量','标题']]
print(df.groupby(['标题','销售员']).sum())#
只计算指定的列:
只要在上面的基础上加一层索引就行
print(df.groupby(['标题','销售员'])['支付总金额'].sum())4.4分组数据的迭代
print(df.groupby(['标题','销售员']))最后输出的是上面的东西,想要查看需要用到for循环。其中由name、和group两类变量。
for name,group in df.groupby(['标题','销售员']):
print(name)
#结果:
('C++', '李四')
('C++', '王五')
('java', '孙七')
('java', '李四')
('java', '王五')
('java', '赵六')
('lingo', '孙七')
('lingo', '李四')
('lingo', '王五')
('lingo', '赵六')
('python', '孙七')
('python', '李四')
('python', '王五')
('python', '赵六')import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=data[['支付总金额','销售员','购买数量','标题']]
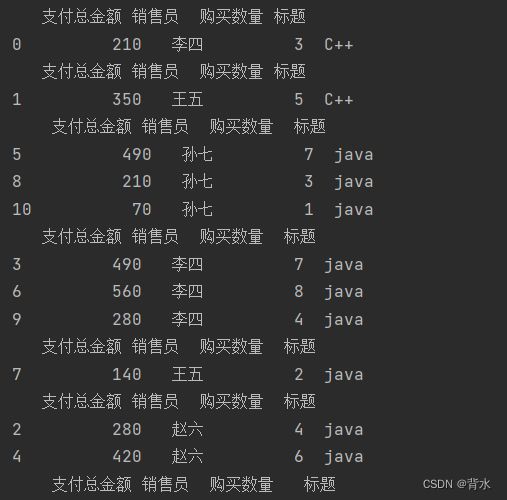
for name,group in df.groupby(['标题','销售员']):
print(group)
4.5agg函数
print(df.groupby(['标题','销售员']).agg(['sum','mean']))#确定最后统计结果如何操作
对不同的列进行不同的操作:
可以用字典进行操作。
print(df.groupby(['标题','销售员']).agg({'支付总金额':['sum','max'],'购买数量':'sum'}))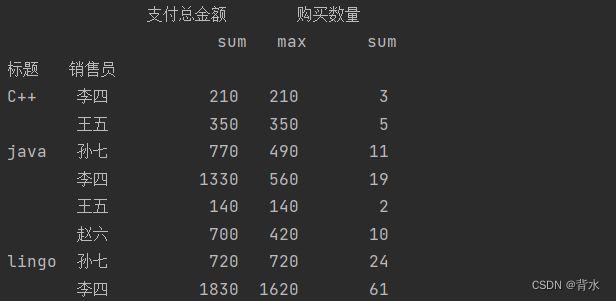
5.数据导出
导出成excel文件:
df.to_excel('....xlsx',index=False,sheet_name='....')
index默认为True,导出行标签,False为不导出
sheet_name表示在哪个目录进行导入,若没有则建立新的
6.日期数据处理
6.1将各种字符转换成日期格式:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
df=pd.DataFrame({'原日期':['14-feb-23','02/14/23','2023/12/14','2023-12-14','2023.12.14','20230214',]})
df['转换后的日期']=pd.to_datetime(df['原日期'])
print(df)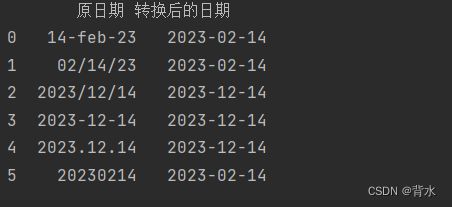
6.2dt对象的使用
dt对象可以对日期进行提取相关信息操作,具体如下:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
df=pd.DataFrame({'原日期':['2024.1.1','2024.1.5','2024.1.7','2024.1.15','2024.1.18']})
df['日期']=pd.to_datetime(df['原日期'])
df['年']=df['日期'].dt.year#提取年
df['月']=df['日期'].dt.year#提取月
df['日']=df['日期'].dt.day#提取天
df['星期几']=df['日期'].dt.day_name()#提取这天是星期几
df['季度']=df['日期'].dt.quarter#提取季度
df['是否年底']=df['日期'].dt.is_year_end#判断是否年底
print(df)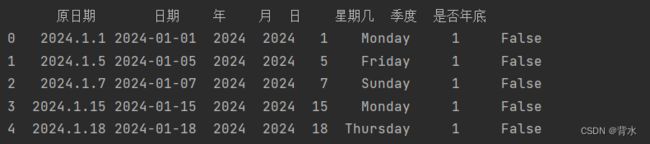
6.3获取指定日期区间的数据
注意想要使用切片操作,日期必须是有顺序的,所以要进行排序。
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
df=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=df[['购买时间','会员名','支付总金额','销售员','购买数量','标题','类别']]
df=df.sort_values(by=['购买时间'])#排序使其相对连续,以便切片
df=df.set_index('购买时间')
print(df['2024-01-01':'2024-01-10'])#查看2024-01-01到2024-01-10的数据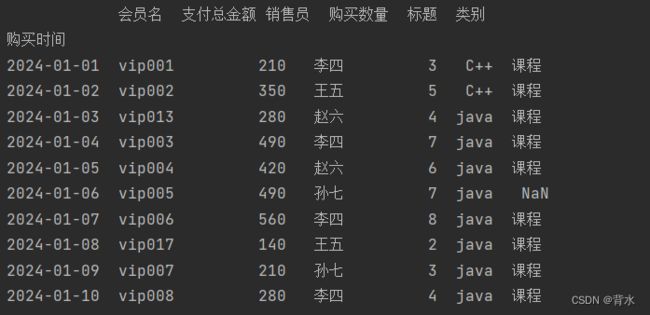
也可以通过下面的方法进行:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
df=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=df[['购买时间','会员名','支付总金额','销售员','购买数量','标题','类别']]
#df=df.sort_values(by=['购买时间'])
#df=df.set_index('购买时间')
print(df.loc[(df['购买时间']>='2024-01-01')&(df['购买时间']<='2024-01-10'),:])#查看2024-01-01到2024-01-10的数据6.4按不同时期统计数据
df.resample(
rule,
axis=0,
closed: Union[str, NoneType] = None,
label: Union[str, NoneType] = None,
convention: str = 'start',
kind: Union[str, NoneType] = None,
loffset=None,
base: int = 0,
on=None,
level=None,
)
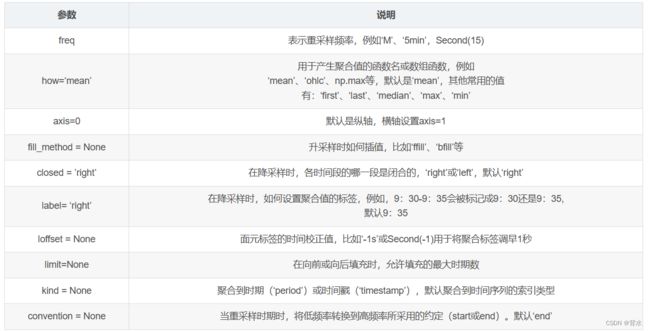
freq参数:

import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
df=pd.read_excel("d:\JD\Desktop\\trydata1.xlsx")
df=df[['购买时间','会员名','支付总金额','销售员','购买数量','标题','类别']]
df=df.sort_values(by=['购买时间'])
df=df.set_index('购买时间')
print(df)
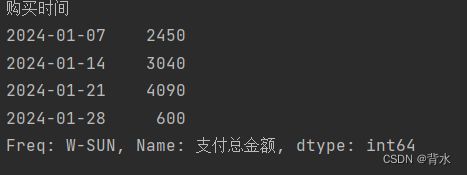
print(df.resample('W').sum()['支付总金额'])