机器学习实验报告——隐式马尔可夫模型HMM
目录
一、模型介绍
1.1模型引入
1.2模型背景及发展历程
1.3模型基本假设
1.4模型基本概念介绍
1.5HMM三要素
二、模型基本问题
2.1评估问题
2.1.1说明
2.1.2 解决方法
2.2 学习问题
2.2.1说明
2.2.2 解决方法
2.3 解码问题
2.3.1 说明
2.3.2 解决方法
三、模型实现
3.1 hmmlearn库简介
3.2案例实现
3.3代码实现
3.4分析
四、模型讨论
4.1 优缺点讨论
4.3 HMM的应用
五、模型总结
一、模型介绍
1.1模型引入
隐式马尔科夫模型(Hidden Markov Model,HMM)可以通过日常生活中的情境来进行类比。
例如,假设你想根据某地区的天气情况预测未来几天的天气。在这个情景下,天气状况可以被视为“隐藏状态”,而每一天的具体天气现象则是你能够观测到的内容,即“观测状态”。隐藏状态是无法直接观测到的,而观测状态是实际可见的天气情况。进一步地,你可以将天气的变化看作是一个马尔科夫过程,即当前的天气状态只依赖于前一天的天气状态,类似于HMM中的状态转移概率。而观测状态则对应于你能够观测到的具体天气现象,每种天气现象发生的概率可以看作是HMM的观测概率分布。通过这个类比,你可以将天气预测问题理解为一个隐式马尔科夫模型,通过观测到的天气现象来推断隐藏状态,即未来几天的天气情况。
1.2模型背景及发展历程
隐式马尔科夫模型(Hidden Markov Model,HMM)的背景可以追溯到20世纪60年代。HMM最初由L. E. Baum和T. Petrie于1966年提出,并应用于语音识别领域。
随着时间的推移,HMM逐渐被引入到其他领域,并取得了广泛的发展和应用。以下是HMM的一些重要的发展历程:
·1970年代:HMM在自然语言处理领域得到应用,用于词性标注、句法分析等任务。这一时期的研究为之后的语言模型和基于HMM的序列标注方法奠定了基础。
·1980年代:HMM在语音识别领域取得了显著的进展。研究者们利用HMM来建模语音信号的产生过程,实现了较高准确率的语音识别系统。这个时期也见证了HMM的一些扩展,如连续混合HMM(Continuous HMM)和大词汇连续语音识别(Large Vocabulary Continuous Speech Recognition)。
·1990年代:HMM在生物信息学领域得到广泛应用。研究者们将HMM用于DNA和蛋白质序列的分析,例如基因识别、蛋白质家族分类等。HMM在这些任务中展现了强大的建模能力。
·2000年代至今:HMM在更多领域得到应用,并且继续发展和演进。随着深度学习方法的兴起,HMM往往与神经网络结合使用,形成了混合模型,如深度置信网络(Deep Belief Networks)和循环神经网络(Recurrent Neural Networks)。这些混合模型在语音识别、自然语言处理和其他序列数据建模任务中取得了重要突破。
总体来说,隐式马尔科夫模型经历了几十年的发展,从最初的语音识别到涉及自然语言处理、生物信息学、金融预测等多个领域。它的发展为时序数据的建模提供了重要的工具和理论基础,并且对后续的深度学习方法也产生了影响。
1.3模型基本假设
隐式马尔科夫模型(Hidden Markov Model,HMM)的基本假设包括:
(1)有限历史性假设(Limited History Assumption):当前隐藏状态只依赖于有限的历史状态,而不依赖于更远的过去状态。简言之,当前状态只与前一个状态相关,与更早的状态无关。
其中,表示第i个时间步的隐藏状态,·|·)表示给定前一个状态条件下的概率分布。
(2)齐次性假设(Homogeneous Assumption):系统状态的转移概率在时间上保持不变,即系统状态的转移概率与具体的时间步长无关。这意味着系统在不同时间步骤上的状态转移概率是相同的。
![]()
其中,表示第i个时间步的隐藏状态。
(3)观测独立性假设(Observation Independence Assumption):每个观测状态只依赖于当前的隐藏状态,与其他观测状态和隐藏状态无关。简单来说,当前观测状态只与当前隐藏状态相关,与其他观测状态和隐藏状态无关。
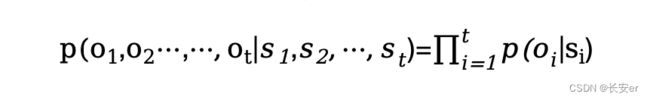
这些假设共同构成了隐式马尔科夫模型的基础。
1.4模型基本概念介绍
隐式马尔科夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述由隐藏状态和可观察状态组成的序列,并建模它们之间的概率关系。HMM常用于序列数据建模和预测问题。以下是HMM的基本概念:
(1)隐藏状态(Hidden State):代表系统内部的状态,不可直接观测到。隐藏状态可以是离散的或连续的,例如天气的状态可以是晴天、雨天、多云等。
(2)观测状态(Observation State):代表我们能够观测到的状态或事件。观测状态可以是离散的或连续的,例如天气的观测状态可以是晴天、雨天、多云等。
(3)状态转移概率(Transition Probability):表示在给定隐藏状态下从一个隐藏状态转移到另一个隐藏状态的概率。这个概率可以通过历史观测状态和隐藏状态的序列来估计。
(4)观测概率分布(Observation Probability):表示在给定隐藏状态下对应观测状态出现的概率。这个概率可以通过已知的观测状态和隐藏状态的序列来估计。
(5)初始状态概率分布(Initial State Probability Distribution):表示系统初始时处于各隐藏状态的概率分布。
HMM的基本思想是通过观测到的序列来推断隐藏状态的序列,并利用状态转移概率和观测概率分布进行模型训练和预测。具体地,可以使用前向-后向算法、维特比算法等方法来计算隐藏状态的最优路径或预测未来的隐藏状态。
1.5HMM三要素
λ=(A, B, π) 称为隐马尔可夫模型的三要素
假设Q是所有可能状态的集合,V是所有可能观测的集合即
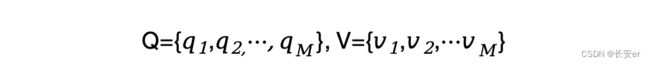
其中,N是可能的状态数,M是可能的观测数(状态q是不可见的,观测v是可见的)
I是长度为T的状态序列,O是对应的观测序列即

(1)A为状态转移概率矩阵:
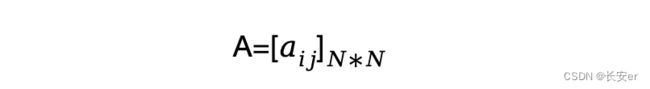
其中==|=),i=1,2,,;j=1,2,,N(代表t时刻处于状态,t+1时刻转移到状态的概率。
(2)B为观测概率矩阵:

其中==|=),k=1,2,,M;j=1,2,,N(代表t时刻处于状态生成观测状态的概率。
(3)pai为初始状态概率变量
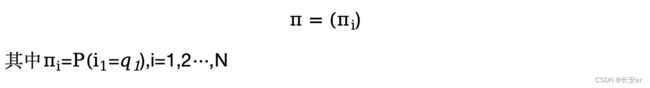
隐马尔可夫模型由初始状态向量π、状态转移矩阵A和观测概率矩阵B决定。π和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型可用三元符号表示,即λ=(A, B, π).
二、模型基本问题
HMM模型通常涉及三个基本问题,它们是:评估问题(Evaluation Problem)、解码问题(Decoding Problem)和学习问题(Learning Problem)。
这三个基本问题是在HMM模型中经常遇到的,并且都有相应的解决方法。通过解决这些问题,我们可以评估、解码和学习HMM模型,使其适应不同的实际应用场景。
2.1评估问题
2.1.1说明
给定一个HMM模型和观测序列,计算该观测序列出现的概率。即,给定模型参数λ=(A, B, π)和观测序列O=(o1, o2, ..., oT),计算P(O|λ)。
2.1.2 解决方法
(1)暴力算法(穷举法)
对所有可能的状态序列和观测序列的联合概率求和
具体步骤
列举所有可能的状态序列,则状态序列的概率为:
![]()
对于固定的状态序列,观测序列O的概率为:
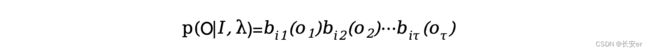
则在模型λ下观测序列O出现的概率:
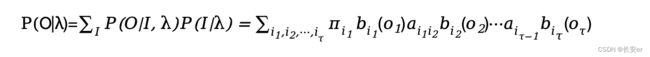
穷举法的时间复杂度过高,可以采用动态规划算法——前向后向算法进行优化
(2)前向算法
在前向算法中,我们定义前向变量 为时间t时刻处于状态i并且观测到的概率。具体步骤如下:


(3)后向算法
在后向算法中,我们定义后向变量 βt(i) 为在时间t的条件下从状态i开始生成部分观测序列, , ..., 的概率。具体步骤如下:
递归,当 t=T 时终止递归:
初值为:βT(i) = 1,即在最终时刻T处于状态i的概率为1。
当t=1时终止递归:
求得观测序列的概率 P(O|λ):
P(O|λ) = ∑i * (o1) *
2.2 学习问题
2.2.1说明
给定观测序列和一些模型结构的假设,从中学习出最优的HMM模型参数。即,给定观测序列O=(, , ..., )和一些关于HMM模型结构的假设,通过估计模型参数λ=(A, B, π),使得该模型在给定观测序列下的概率P(O|λ)最大化。
2.2.2 解决方法
(1)监督学习(极大似然直接估计)
在已知状态序列的情况下,可以直接采用极大似然估计来估计隐马尔可夫模型的参数,但在没有对应状态序列I的情况下,采用人工标注训练数据代价太高,多数时候采用非监督学习算法——Baum-Welch算法
(2)非监督学习(Baum-Welch算法迭代估计)
Baum-Welch算法的步骤如下:
①初始化模型参数 A、B 和 π。
②对于每个观测序列,使用前向-后向算法计算观测序列出现的概率和各个隐藏状态的后验概率。
③使用后验概率更新模型参数 A、B 和 π。
④重复步骤2和步骤3,直到模型参数收敛或达到预设的迭代次数。
通过不断迭代更新模型参数,Baum-Welch算法可以找到最优的HMM模型参数,使模型在给定观测序列下的概率最大化。
总之,学习问题中的非监督学习方法Baum-Welch算法可以从观测序列中学习出HMM模型的最优参数。它通过迭代的方式不断更新模型参数,使模型更好地拟合给定的观测序列。
2.3 解码问题
2.3.1 说明
给定一个HMM模型和观测序列,找出最可能的对应隐藏状态序列。即,给定模型参数λ=(A, B, π)和观测序列O=(, , ..., ),寻找使得P(S|O, λ)最大的隐藏状态序列S=(, , ..., )。
2.3.2 解决方法
当解决HMM模型的解码问题时,可以采用以下两种方法:
(1)贪心近似算法:
贪心近似算法是一种简单而直接的方法,它基于每个时刻选择最可能的状态。具体步骤如下:
对于观测序列中的每个观测值,选择使得最大的状态s,作为当前时刻t的隐藏状态。
重复上述步骤直到遍历完整个观测序列。
贪心近似算法的优点是简单易实现,计算效率高。然而,由于它仅仅基于局部最优选择,可能会导致全局最优路径的漏掉,因此在某些情况下,贪心近似算法可能不够准确。
(2)维特比算法:
维特比算法是一种动态规划的方法,能够找到全局最优的隐藏状态序列。其核心思想是利用动态规划的思路,通过存储中间结果来减少计算量。具体步骤如下:
初始化:定义矩阵δ和ψ,其中δt(i)表示在时刻t处于状态i的路径的最大概率,ψt(i)表示在时刻t处于状态i的路径的概率最大化时t-1时刻的状态。
δ1(i) = πi * bi(o1),即在时刻1处于状态i的路径的最大概率为初始概率πi乘以观测o1的概率。
ψ1(i) = 0,初始时刻的状态设为0。
递推:对于 t = 2, 3, ..., T:
δt(j) = max(δt-1(i) * aij) * bj(ot),即在时刻t处于状态j的路径的最大概率为t-1时刻所有状态i到状态j的路径概率的最大值乘以状态j观测到ot的概率。
ψt(j) = argmax(δt-1(i) * aij),记录取得δt(j)最大值时的状态i。
终止:计算最大概率路径的终结点:
P* = max(δT(i)),其中i表示所有状态。
q*T = argmax(δT(i)),找到使得δT(i)取得最大值的状态i。
路径回溯:从终结点q*T开始,根据ψ矩阵回溯找到对应的最大概率路径。
维特比算法通过动态规划的方式避免了贪心近似算法可能遇到的局部最优问题,能够找到全局最优的隐藏状态序列。因此,在实际应用中,维特比算法更常用于解决HMM模型的解码问题。
三、模型实现
3.1 hmmlearn库简介
hmmlearn 实现了隐马尔可夫模型 (Hidden Markov Models,简称 HMMs)。HMM 是一种生成概率模型,其中一系列可观测的变量由一系列内部隐藏状态生成。这些隐藏状态并不直接观察到。隐藏状态之间的转换被假定为(一阶)马尔可夫链的形式。它们可以通过起始概率向量和转移概率矩阵来指定。一个可观测值的发射概率可以是任何分布,其参数取决于当前的隐藏状态。HMM 完全由这些参数确定。
可用的模型:
hmm.CategoricalHMM: 有分类(离散)发射的隐马尔可夫模型。
hmm.GaussianHMM: 具有高斯发射的隐马尔可夫模型。
hmm.GMMHMM: 具有高斯混合发射的隐马尔可夫模型。
hmm.MultinomialHMM: 具有多项分布发射的隐马尔可夫模型。
hmm.PoissonHMM: 具有泊松发射的隐马尔可夫模型。
vhmm.VariationalCategoricalHMM: 使用变分推断训练的有分类(离散)发射的隐马尔可夫模型。
vhmm.VariationalGaussianHMM: 使用变分推断训练的具有多元高斯发射的隐马尔可夫模型。
构建 HMM 并生成样本:可以通过将上述参数传递给构造函数来构建一个 HMM 实例。然后,可以通过调用 sample() 从 HMM 生成样本。
3.2案例实现
本次实现案例-“天气预测”问题。
假设一个小城市的天气只有两种状态:晴天 (Sunny) 和雨天 (Rainy)。但我们不能直接观察到这些天气状态(假设我们在一个看不到光的室内)。我们只能通过一个朋友每天穿的衣服来推测天气。他有两种衣服:短袖 (Short-sleeved) 和长袖 (Long-sleeved)。这是一个HMM问题,因为天气状态是隐含的,我们只能观察到衣服。
3.3代码实现
from hmmlearn import hmm
import numpy as np
# 定义模型参数
states = ["Sunny", "Rainy"]
observations = ["Short-sleeved", "Long-sleeved"]
initial_probabilities = np.array([0.9, 0.1])
transition_probabilities = np.array([
[0.8, 0.2],
[0.3, 0.7]
])
emission_probabilities = np.array([
[0.7, 0.3],
[0.4, 0.6]
])
# 创建并训练HMM模型
model = hmm.MultinomialHMM(n_components=2, n_trials=1) # 设置n_trials为1
model.startprob_ = initial_probabilities
model.transmat_ = transition_probabilities
model.emissionprob_ = emission_probabilities
# 假设我们观察到的连续三天的衣服是: ["Short-sleeved", "Long-sleeved", "Long-sleeved"]
# 将其转化为多项分布的计数
obs_seq = np.array([
[1, 0], # Short-sleeved
[0, 1], # Long-sleeved
[0, 1] # Long-sleeved
])
# 使用Viterbi算法找到最可能的天气序列
logprob, state_seq = model.decode(obs_seq)
print("Observation sequence:", [observations[np.argmax(obs)] for obs in obs_seq])
print("Most likely weather sequence:", [states[i] for i in state_seq])
3.4分析
3.4.1 代码分析
导入所需的库hmmlearn库中的hmm模块,以及numpy库。这些库分别用于处理隐马尔可夫模型和数值操作。
定义模型参数:
两个隐状态:Sunny和Rainy。
两种观测:Short-sleeved和Long-sleeved。
模型的初始概率、状态转移概率和发射概率。
初始化和设置HMM模型:创建了一个MultinomialHMM模型,该模型具有2个隐状态,并设置了n_trials为1。这意味着每次观测都基于单次试验。接着,我们为模型设置了初始概率、状态转移概率和发射概率。
观测数据:我们定义了一个观测序列,表示连续三天的衣服选择:Short-sleeved, Long-sleeved, Long-sleeved。这些观测被转换为多项分布的计数形式。
使用Viterbi算法解码:我们使用decode方法和Viterbi算法来找出给定观测序列下最有可能的隐状态序列。我们正在尝试观察到的衣服选择预测连续三天的天气,基于我们。
输出结果:最后,我们打印了观测到的衣服选择序列和预测的天气序列。
3.4.2 运行结果及分析

观测序列是["Short-sleeved", "Short-sleeved", "Short-sleeved"],对应的最可能的天气序列是['Sunny', 'Sunny', 'Sunny']。
这意味着根据模型的推断,观测到的连续三天的衣服都是短袖,从而最可能的天气是晴天。这与我们观测到的衣服类型相符,因为在晴天下更容易穿短袖。
四、模型讨论
4.1 优缺点讨论
隐马尔可夫模型(Hidden Markov Model,HMM)具有以下优点和缺点:
(1)优点:
①灵活性:HMM可以用于建模具有时序特征的数据,如语音识别、自然语言处理、时间序列分析等。它可以对观测序列和隐藏状态之间的关系进行建模,并能够处理不完整的观测数据。
②隐含信息:HMM通过隐藏状态序列捕捉和表示了观测数据背后的隐含信息,从而可以更全面地理解和表示数据。
③可扩展性:HMM允许灵活地调整模型的复杂度和规模,可以根据具体问题的需要增加或减少状态数量,以适应不同的数据分布。
(2)缺点:
①独立性假设:HMM基于马尔可夫假设,即当前状态只与前一个状态相关,与更早的状态无关。这个假设可能不符合实际情况,特别是在处理长期依赖关系时,可能会导致模型性能下降。
②参数估计:HMM的参数估计涉及到模型参数的初始化和训练过程,其中包括初始概率、转移概率和发射概率。这些参数的估计过程可能比较复杂,尤其是在数据稀疏或观测到的序列较短时,容易出现过拟合或欠拟合的问题。
③局部最优解:HMM使用的解码算法(如Viterbi算法)可能会陷入局部最优解,而无法找到全局最优解。这可能导致模型的预测准确性下降。
4.2关于模型结构选择的讨论
确定HMM的模型结构是一个关键步骤,它包括确定隐藏状态的数量、建模状态之间的转移概率以及建模观测状态与隐藏状态之间的关系。下面详细说明每个方面的考虑因素:
(1)隐藏状态的数量:
隐藏状态的数量表示了模型对于隐藏状态的划分和建模能力。确定隐藏状态的数量通常是一个挑战性的问题,需要根据具体应用的领域知识、数据特征和实际需求进行决策。一些常见的方法包括:
①领域知识:根据对问题领域的理解和专业知识,预估可能存在的隐藏状态的数量。
②模型选择准则:通过基于信息准则(如赤池信息准则AIC、贝叶斯信息准则BIC)或交叉验证等方法,在不同隐藏状态数量下比较模型的拟合能力,选择最合适的隐藏状态数量。
(2)状态转移概率:
状态转移概率定义了隐藏状态之间的转移关系,即从一个隐藏状态转移到另一个隐藏状态的概率。一般情况下,可以使用训练数据来估计状态转移概率。常用的方法是使用最大似然估计或Baum-Welch算法进行参数估计。如果有领域知识可用,也可以根据先验知识或经验设置状态转移概率。
(3)观测状态与隐藏状态之间的关系:
观测状态与隐藏状态之间的关系可以通过发射概率进行建模。发射概率定义了在给定隐藏状态下,观测到某个观测状态的概率。发射概率可以是离散的(如符号观测)或连续的(如高斯混合模型)。参数估计方法可以根据具体情况选择适合的算法。
在选择HMM的模型结构时,需要综合考虑问题的领域知识、数据特征以及实际需求。灵活性和实验验证是确定模型结构的关键。可以使用交叉验证等技术来评估不同模型结构的性能,并选择最佳的模型结构来提高模型的预测准确性和泛化能力。
4.3 HMM的应用
HMM在以下几个领域中得到了广泛应用:
语音识别:HMM被广泛用于语音识别任务,包括语音识别系统的前端特征提取和声学模型建模。通过将语音信号建模为隐藏状态序列,HMM可以对语音信号进行建模并识别出具体的语音内容。
自然语言处理:在自然语言处理中,HMM被用于词性标注、命名实体识别、句法分析和机器翻译等任务。通过将观测序列建模为隐藏状态序列,HMM可以根据上下文信息来预测和生成相应的语言结构。
机器翻译:HMM在机器翻译中被用于词对齐和翻译建模。通过将源语言和目标语言之间的对应关系建模为隐藏状态序列,HMM可以实现基于统计的翻译模型。
手写识别:在手写识别中,HMM被用于建模和识别手写字符和笔画。通过将手写轨迹建模为隐藏状态序列,HMM可以对手写字符进行建模并进行识别。
生物信息学:在生物信息学中,HMM被用于DNA序列分析、蛋白质序列分析和基因识别等任务。通过将DNA或蛋白质序列建模为隐藏状态序列,HMM可以对这些生物序列进行建模和分析。
在不同的应用领域中,HMM面临着一些特定的问题和挑战。例如,在语音识别中,HMM可能面临噪声和发音变异等问题;在机器翻译中,HMM可能面临词义歧义和长距离依赖等问题。因此,在具体应用中,需要根据问题的特点和需求来选择合适的HMM模型结构和算法,并结合领域知识和数据特征进行定制化的优化和改进。
五、模型总结
隐式马尔可夫模型(HMM)是一种用于描述由隐藏状态和可观察状态组成的序列,并建模它们之间概率关系的统计模型。HMM在语音识别、自然语言处理、生物信息学和金融预测等领域得到广泛的应用。
HMM的基本概念包括隐藏状态、观测状态、状态转移概率、观测概率分布和初始状态概率分布。HMM模型的基本假设包括有限历史性假设、齐次性假设和观测独立性假设。
HMM由初始状态向量π、状态转移矩阵A和观测概率矩阵B决定,这些要素决定了HMM模型的行为。
HMM模型涉及三个基本问题:评估问题、解码问题和学习问题。
评估问题是给定一个HMM模型和观测序列,计算该观测序列出现的概率。
解码问题是给定一个HMM模型和观测序列,找出最可能的对应隐藏状态序列。
学习问题是给定观测序列和一些模型结构的假设,从中学习出最优的HMM模型参数。
维特比算法是解码问题的一种常用方法,通过动态规划的方式找到最可能的隐藏状态序列。
总之,HMM模型在时序数据建模和预测问题中具有重要的意义,并有相应的解决方法可以评估、解码和学习HMM模型,使其适应不同的实际应用场景。