多流转换 (分流,合流,基于时间的合流——双流联结 )
目录
一,分流
1.实现分流
2.使用侧输出流
二,合流
1,联合
2,连接
三,基于时间的合流——双流联结
1,窗口联结
1.1 窗口联结的调用
1.2 窗口联结的处理流程
2,间隔联结
2.1 间隔联结的原理
2.2 间隔联结的调用
在数据处理中,多流转换是一个重要的概念。它主要涉及分流和合流两种操作。分流通常通过侧输出流实现,有助于将数据流拆分成多个子流进行独立处理。合流则提供了多种算子,如union()、connect()和join(),根据实际需求合并不同数据流。
一,分流
分流操作是指将一条数据流拆分为多个完全独立的数据流。基于一个DataStream,我们可以获得多个等价的子DataStream。为了实现这一过程,通常会定义特定的筛选条件,以确保符合特定标准的数据被正确地分配到相应的流中。通过这种方式,我们可以对数据进行更细致的处理和分析,同时确保每个子流中的数据都是独特的,避免重复。
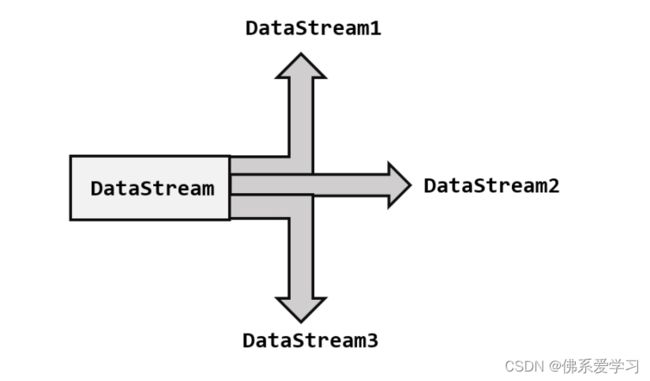
1.实现分流
根据条件筛选数据的需求确实可以通过多次独立调用filter()方法来实现。这种方法允许我们针对同一条数据流进行多次筛选,从而将数据拆分成多个子流。通过这种方式,我们可以根据不同的筛选条件对数据进行分类和分离,以满足不同的处理和分析需求。这种分流操作在数据处理中非常常见,它有助于提高数据处理的灵活性和效率。
import org.apache.flink.api.scala._
object SplitStreamExample {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 定义数据源
val dataStream = env.fromElements(1, 2, 3, 4, 5)
// 定义筛选条件
val condition1: (Int) => Boolean = (x: Int) => x % 2 == 0
val condition2: (Int) => Boolean = (x: Int) => x > 3
// 对DataStream进行分流操作,得到两个子DataStream
val stream1 = dataStream.filter(condition1) // 筛选出偶数
val stream2 = dataStream.filter(condition2) // 筛选出大于3的数
// 输出结果到控制台
stream1.print() // 输出偶数到控制台
stream2.print() // 输出大于3的数到控制台
// 执行程序
env.execute("Split Stream Example")
}
}在上面的代码中,我们首先导入了必要的库。然后,我们创建了一个执行环境,并定义了一个包含一些整数的DataStream。接下来,我们定义了两个筛选条件,分别为条件1和条件2。条件1用于筛选出偶数,条件2用于筛选出大于3的数。然后,我们使用filter()方法对DataStream进行分流操作,得到两个子DataStream,分别为stream1和stream2。最后,我们使用print()方法将两个子DataStream中的数据输出到控制台。最后,我们执行程序。
2.使用侧输出流
在Flink 1.13版本中,split()方法确实已被弃用,取而代之的是使用处理函数(process function)的侧输出流(side output)。这意味着您不再需要将数据流拆分为独立的流,而是可以通过侧输出流将数据发送到不同的目的地。
为了将数据发送到侧输出流,您需要使用处理函数中的上下文(Context)对象的output()方法。这个方法允许您输出任意类型的数据,并将其发送到指定的侧输出流。
侧输出流的标记和提取都离不开一个“输出标签”(OutputTag)。这个标签相当于split()分流时的“戳”,用于指定侧输出流的id和类型。通过使用OutputTag,您可以轻松地标记和提取侧输出流中的数据,以便进一步处理或分析。
总之,Flink 1.13版本通过引入处理函数的侧输出流,使得数据分流更加灵活和方便。使用OutputTag和上下文对象的output()方法,您可以轻松地将数据发送到不同的侧输出流,并根据需要对其进行处理或分析。
import org.apache.flink.api.scala._
import org.apache.flink.util.OutputTag
object SideOutputExample {
// 定义侧输出标签
val outputTag: OutputTag[Int] = OutputTag[Int]("side-output")
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 定义数据源
val dataStream = env.fromElements(1, 2, 3, 4, 5)
// 定义处理函数
val processFunc = new ProcessFunction[Int, Int] {
override def processElement(value: Int,
ctx: ProcessFunction[Int, Int]#Context,
out: Collector[Int]): Unit = {
// 检查是否属于侧输出流
if (ctx.outputTag(outputTag).isOutputDropped(value)) {
// 如果是侧输出流的数据,则忽略输出
return
}
// 将数据正常输出到主输出流
out.collect(value)
}
}
// 将侧输出标签注册到执行环境
env.registerOutputTag(outputTag)
// 创建数据流并连接处理函数和侧输出流
val resultStream = dataStream.connect(outputTag) { (in, out) => processFunc }
// 输出结果到控制台
resultStream.print() // 输出主输出流到控制台
// 执行程序
env.execute("Side Output Example")
}
} 在上面的代码中,我们首先定义了一个侧输出标签outputTag,用于标记侧输出流。然后,我们创建了一个处理函数processFunc,它实现了ProcessFunction接口。在处理函数中,我们使用ctx.outputTag(outputTag).isOutputDropped()方法来检查每个数据是否属于侧输出流。如果是侧输出流的数据,我们将其忽略;否则,我们将数据正常输出到主输出流。最后,我们将侧输出标签注册到执行环境,并创建数据流resultStream,通过使用connect()方法将处理函数和侧输出流连接起来。最后,我们将结果流输出到控制台。执行程序后,主输出流的数据将被打印到控制台。
二,合流
在数据处理中,将多条流进行合并是一个常见的需求。在实际应用中,我们经常遇到来自不同源的多条数据流,需要对它们进行联合处理。因此,Flink 中的合流操作更为普遍,对应的 API 也更加丰富。
1,联合
最简单的合流操作是直接将多条流合在一起,被称为“联合”(union)。在Flink中,我们可以使用union()算子来实现这一操作。联合操作要求参与合并的流中的数据类型必须相同,因为只有这样,Flink才能正确地识别和处理数据。
当多条流进行联合操作后,会形成一个新的流,这个新流包含了所有参与合并的流中的元素,并且数据类型保持不变。这种合流方式非常直接和简单,就像公路上多个车道汇集成一个车道一样。通过联合操作,我们可以将多个数据流有效地整合在一起,以便进行更全面的处理和分析。
需要注意的是,联合操作可能会导致数据重复,因为所有流中的元素都会包含在新流中。因此,在使用联合操作时,需要谨慎处理重复数据的问题。另外,根据具体的数据处理需求,可能还需要考虑其他合流策略和算子,例如使用connect()算子进行流之间的连接操作,或者使用join()算子进行基于键的流合并等。

2,连接
在Flink中,连接(connect)是一种方便的合流操作。与联合(union)不同,连接操作允许两条流直接对接在一起。这意味着你可以在一条流中的每个元素上执行一些操作,然后将结果连接到另一条流中的相应元素上。
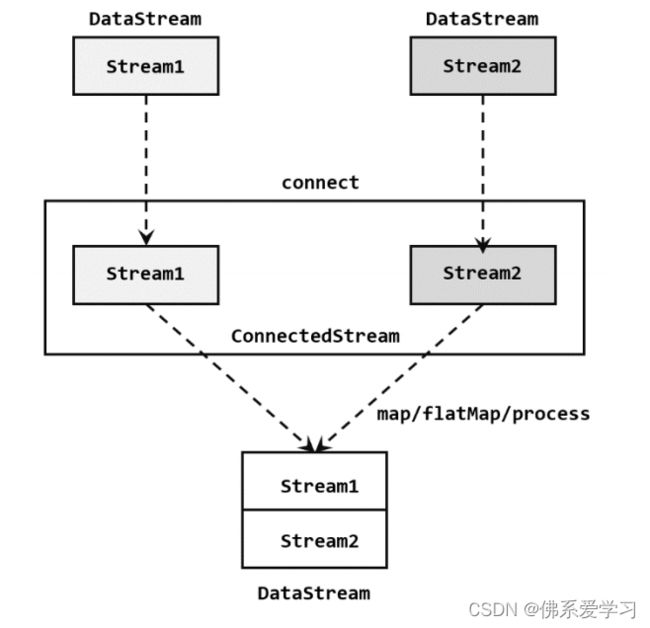
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.datastream.DataStream
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
object FlinkConnectExample {
def main(args: Array[String]): Unit = {
// 创建Flink流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建第一条流
val stream1 = env.fromElements("A", "B", "C")
// 创建第二条流
val stream2 = env.fromElements("X", "Y", "Z")
// 使用连接操作将两条流对接在一起
val connectedStream = stream1.connect(stream2)
// 对连接后的流进行处理
connectedStream
.map(new MapFunction[(String, String), String] {
override def map(value: (String, String)): String = {
s"Connected: ${value._1} - ${value._2}"
}
})
.print()
// 启动Flink作业
env.execute("Flink Connect Example")
}
}
在这个示例中,我们首先创建了两个数据流stream1和stream2,然后使用connect()方法将它们连接在一起。接下来,我们使用map()操作对连接后的流进行处理,将每个元组的第一个元素和第二个元素连接起来,并打印输出结果。最后,我们通过调用execute()方法启动Flink作业。
三,基于时间的合流——双流联结
在处理两条流的合并时,我们往往不仅仅是将所有数据简单放在一起,而是希望能够根据某个字段的值将它们联结起来,进行更细致的处理。这种需求与关系型数据库中的表连接操作非常相似。在Flink中,我们可以通过connect()操作来实现类似于SQL中的join操作。通过在connect()操作中指定键进行分组后合并,我们可以将两条流根据某个字段的值进行联结,并进行相应的处理。
除了connect()操作外,Flink的DataStream API还提供了两种内置的join()算子,用于基于时间的合流操作。这些算子使得我们能够更方便地实现基于时间的合流操作,而无需自定义触发逻辑和设置定时器。通过使用这些内置的join()算子,我们可以更高效地处理涉及多条相关数据流的应用场景。
综上所述,Flink提供了多种合流操作的算子和功能,使得我们能够根据实际需求选择适合的合流策略和算子。通过灵活运用这些功能,我们可以充分利用Flink的强大处理能力,实现更高效、更灵活的数据流处理和分析。
1,窗口联结
在处理基于时间的操作时,时间窗口是最基本的操作之一。我们之前已经介绍了Window API的用法,主要用于在特定时间段内对单一数据流进行计算和处理。如果你希望将两条流的数据进行合并,并在特定时间段内进行统计和处理,你可以使用Flink提供的窗口联结(window join)算子。
窗口联结算子允许你定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。通过这种方式,你可以对两条流的数据进行合并,并在指定的时间窗口内进行聚合、过滤、转换等操作。
使用窗口联结算子,你可以根据实际需求选择不同的窗口策略,例如滚动窗口、滑动窗口或会话窗口等。你还可以根据时间或事件进行窗口触发,并使用Flink提供的各种函数对窗口内的数据进行处理和分析。
总之,窗口联结算子为基于时间的合流操作提供了一种强大而灵活的工具,使得你可以在Flink中高效地处理涉及多条相关数据流的应用场景。通过合理使用窗口联结算子,你可以更好地满足实际应用中对时间相关数据处理的需求。
1.1 窗口联结的调用
窗口联结在代码中的实现首先需要调用DataStream的
join()方法来合并两条流,得到一个JoinedStreams对象。然后,通过where()和equalTo()方法指定两条流中用于联结的键。接下来,使用window()方法来定义窗口,并根据实际需求选择窗口策略,如滚动窗口、滑动窗口或会话窗口等。最后,调用apply()方法并传入一个联结窗口函数来进行处理计算。
1.2 窗口联结的处理流程
在Flink的窗口联结操作中,
JoinFunction是一个重要的函数类型,用于定义如何将两条流中的数据进行联结匹配。JoinFunction有两个参数,分别代表了来自两条流中匹配的数据。在窗口中,每成功匹配一对数据,
JoinFunction的join()方法就会被调用一次。通过在join()方法中定义相应的逻辑,你可以对匹配的数据进行处理和计算,并输出一个结果。除了
JoinFunction,你还可以在apply()方法中传入FlatJoinFunction。FlatJoinFunction的用法与JoinFunction非常类似,主要区别在于其内部实现的join()方法没有返回值。这意味着对于每对匹配的数据,你可以通过FlatJoinFunction输出任意数量的结果,这些结果将被收集并处理。在Flink中,结果的输出是通过收集器(Collector)来实现的。通过将收集器作为参数传递给窗口函数,你可以将处理后的结果发送到外部系统或进行进一步的处理。
通过合理使用
JoinFunction和FlatJoinFunction,你可以在Flink的窗口联结操作中实现对两条流数据的匹配和处理,并根据实际需求输出相应的结果。
2,间隔联结
Flink 提供了一种称为“间隔联结”(interval join)的合流操作。这种联结操作的核心思想是针对一条数据流中的每个数据,根据其时间戳确定一个时间间隔,然后查看另一条数据流中是否存在匹配的数据。间隔联结的主要目的是找到两条数据流中在特定时间范围内相关联的数据。
在Flink中实现间隔联结操作,需要使用
IntervalJoin类。通过将两条数据流作为输入,并指定时间间隔的范围,你可以在时间窗口内找到匹配的数据对。在处理间隔联结时,你需要考虑时间窗口的配置,以确保正确的时间范围被用于匹配操作。此外,你还需要根据实际需求选择合适的匹配条件和数据处理逻辑。
通过合理配置间隔联结操作,你可以有效地在Flink中处理涉及时间相关性的数据流,并找到在特定时间范围内的关联数据。这有助于提高数据处理效率和准确性,为进一步的分析和决策提供有价值的信息。
2.1 间隔联结的原理
间隔联结是一种特殊的联结操作,其核心思想是根据指定的时间间隔来匹配两条数据流中的数据。具体来说,给定两个时间点,分别称为“下界”和“上界”,对于一条数据流中的每个数据元素,可以开辟一个时间间隔,即以该数据元素的时间戳为中心,下至下界点、上至上界点的一个闭区间。这个区间被认为是可匹配另一条流数据的“窗口”范围。
匹配的条件是,另一条流中的数据元素的时间戳必须落在该区间范围内,才能成功配对并进入计算和输出结果。需要注意的是,进行间隔联结的两条流必须基于相同的键,下界应小于等于上界,且两者都可以是正数或负数。此外,间隔联结目前仅支持事件时间语义。
通过合理配置和使用间隔联结,可以在Flink中高效地处理涉及时间相关性的数据流,找到在特定时间范围内的关联数据,并进一步进行复杂的数据分析和处理。

流A与流B进行间隔联结。基于流A中的每个数据元素,我们可以确定一个时间间隔。在此示例中,下界设置为-2毫秒,上界设置为1毫秒。
对于流A中时间戳为2的元素,其可匹配的时间间隔为[0, 3]。在流B中,时间戳为0和1的两个元素落在这个区间内,因此它们与流A中的元素(2, 0)和(2, 1)匹配。同样地,流A中时间戳为3的元素的可匹配区间为[1, 4],而流B中只有时间戳为1的元素与之匹配,得到匹配数据对(3, 1)。
值得注意的是,间隔联结是一种内连接(inner join),这意味着只有匹配的数据对才会被包括在结果中。与窗口联结不同,间隔联结的时间段是基于流中数据的,因此是不确定的。此外,流B中的数据可以在多个区间内被匹配,这意味着它可以与流A中的多个元素相匹配。
通过合理配置和使用间隔联结,我们可以有效地处理涉及时间相关性的数据流,并找到在特定时间范围内的关联数据。这有助于提高数据处理效率和准确性,为进一步的分析和决策提供有价值的信息。
2.2 间隔联结的调用
在代码中实现间隔联结操作,通常基于KeyedStream进行联结(join)操作。在DataStream经过keyBy()方法得到KeyedStream之后,可以调用intervalJoin()方法来合并两条流。传入的参数也是一个KeyedStream,且两者的key类型应该一致。intervalJoin()方法返回一个IntervalJoin类型,后续的操作顺序是固定的。
首先,通过between()方法指定间隔的上下界,然后调用process()方法来定义对匹配数据对的处理操作。process()方法需要传入一个ProcessJoinFunction,它是处理函数家族中的一员,专门用于处理联结操作。
通过合理配置和使用间隔联结操作,可以在代码中高效地处理涉及时间相关性的数据流,并找到在特定时间范围内的关联数据。这有助于提高数据处理效率和准确性,为进一步的分析和决策提供有价值的信息。