【小白学PyTorch】5.torchvision预训练模型与数据集全览
【机器学习炼丹术】的学习笔记分享
<<小白学PyTorch>>
小白学PyTorch | 4 构建模型三要素与权重初始化
小白学PyTorch | 3 浅谈Dataset和Dataloader
小白学PyTorch | 2 浅谈训练集验证集和测试集
小白学PyTorch | 1 搭建一个超简单的网络
小白学PyTorch | 动态图与静态图的浅显理解
文章目录:
1 torchvision.datssets
2 torchvision.models
模型比较
本文建议复制代码去跑跑看,增加一下手感。如果有些数据需要科学上网,公众号回复【torchvision】获取代码和数据。
torchvision
官网上的介绍():The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision.
翻译过来就是:torchvision包由流行的数据集、模型体系结构和通用的计算机视觉图像转换组成。简单地说就是常用数据集+常见模型+常见图像增强方法
这个torchvision中主要有包组成:
torchvision.datasetstorchvision.modelstorchvision.transforms
1 torchvision.datssets
包含贼多的数据集,包含下面的: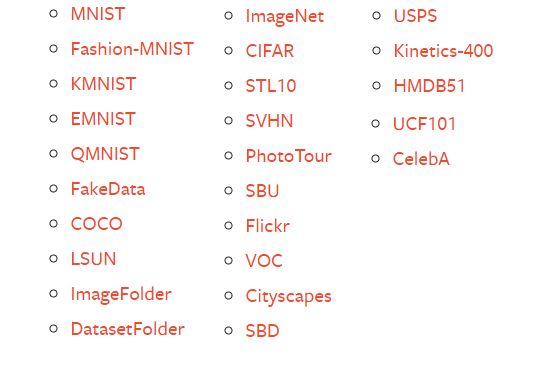
官方说明了:All the datasets have almost similar API. They all have two common arguments: transform and target_transform to transform the input and target respectively.
翻译过来就是:每一个数据集的API都是基本相同的。他们都有两个相同的参数:transform和target_transform(后面细讲)
我们就用最经典最简单的MNIST手写数字数据集作为例子,先看这个的API: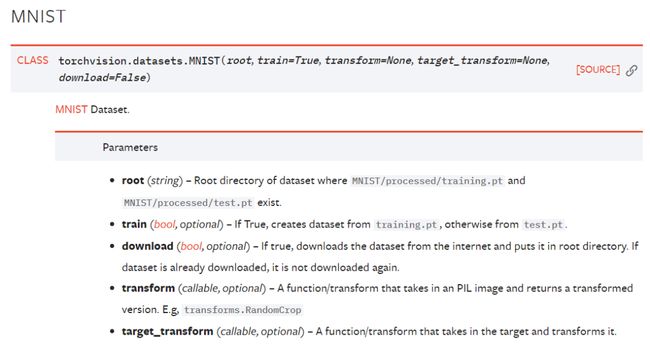
包含5个参数:
root:就是你想要保存MNIST数据集的位置,如果download是Flase的话,则会从目标位置读取数据集;
download:True的话就会自动从网上下载这个数据集,到root的位置;
train:True的话,数据集下载的是训练数据集;False的话则下载测试数据集(真方便,都不用自己划分了)
transform:这个是对图像进行处理的transform,比方说旋转平移缩放,输入的是PIL格式的图像(不是tensor矩阵);
target_transform:这个是对图像标签进行处理的函数(这个我没用过不太确定,也许是做标签平滑那种的处理?)
【下面用代码进一步理解】
import torchvision
mydataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=None,
target_transform=None,
download=True)
运行结果如下,表示下载完毕(我不太确定这个下载数据集是否需要,我会把这次需要用的代码和数据集放到公众号,后台回复【torchvision】获取,下载出现问题请务必私戳我)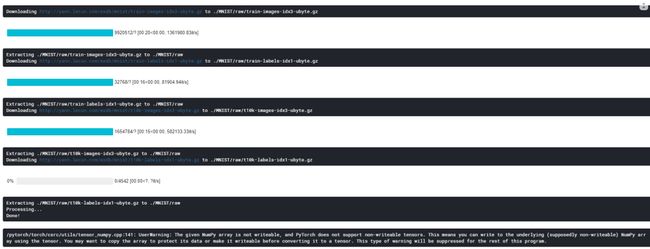
之后我们需要用到上一节课讲到的dataloader的内容:
from torch.utils.data import Dataset,DataLoader
myloader = DataLoader(dataset=mydataset,
batch_size=16)
for i,(data,label) in enumerate(myloader):
print(data.shape)
print(label.shape)
break
这时候会抛出一个错误:![]()
大致看一看,就是pytorch的这个dataloader不是可以把数据集分成batch嘛,这个dataloder只能把tensor或者numpy这样的组合成batch,而现在的数据集的格式是PIL格式。这里验证了之前说到的,transform这个输入是PIL格式的图片,解决方法是:transform不能是None,我们需要将PIL转化成tensor才可以
所以我们把上面的transform稍作修改:
mydataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=torchvision.transforms.ToTensor(),
target_transform=None,
 download=True)
重新运行的时候可以得到结果:![]() 结果中,16表示一个batch有16个样本,1表示这是单通道的灰度图片,28表示MNIST数据集图片是 的大小,然后每一个图片有一个label。
结果中,16表示一个batch有16个样本,1表示这是单通道的灰度图片,28表示MNIST数据集图片是 的大小,然后每一个图片有一个label。
想要获取其他的数据集也是一样的,不过这里就用MNIST作为举例,其他的相同。
2 torchvision.models
预训练模型中torchvision提供了很多种,大体分成下面四类:
分别是分类模型,语义模型,目标检测模型和视频分类模型。这里呢因为分类模型比较常见也比较基础,就主要介绍这个好啦。
在torch1.6.0版本中(应该是比较近的版本),主要包含下面的预训练模型:
构建模型可以通过下面的代码:
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet = models.mobilenet_v2()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
这样构建的模型的权重值是随机的,只有结构是保存的。想要获取预训练的模型,则需要设置参数pretrained:
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet = models.mobilenet_v2(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
我看官网的英文讲解,提到了一点:似乎这些模型的预训练数据集都是ImageNet的那个数据集,输入图片都是3通道的,并且要求输入图片的宽高不小于224像素,并且要求输入图片像素值的范围在0到1之间,然后做一个normalization标准化。
不知道各位在看一些案例的时候,有没有看到这个标准化:mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225],这个应该是ImageNet的图片的标准化的参数。
这些预训练的模型参数不确定能不能直接下载,我也就把这些模型存起来一并放在了公众号的后台,依然是回复【torchvision】获取。
得到了.pth文件之后使用torch.load来加载即可。
# torch.save(model, 'model.pth')
model = torch.load('model.pth')
模型比较
最后呢,torchvision官方提供了一个不同模型在Imagenet 1-crop 的一个错误率的比较。可以一起来看看到底哪个模型比较好使。这里我放了一些常见的模型。。像是Wide ResNet这种变种我就不放了。
| 网络 | Top-1 error | Top-5 error |
|---|---|---|
| AlexNet | 43.45 | 20.91 |
| VGG-11 | 30.98 | 11.37 |
| VGG-13 | 30.07 | 10.75 |
| VGG-16 | 28.41 | 9.62 |
| VGG-19 | 27.62 | 9.12 |
| VGG-13 with BN | 28.45 | 9.63 |
| VGG-19 with BN | 25.76 | 8.15 |
| Resnet-18 | 30.24 | 10.92 |
| Resnet-34 | 26.70 | 8.58 |
| Resnet-50 | 23.85 | 7.13 |
| Resnet-101 | 22.63 | 6.44 |
| Resnet-152 | 21.69 | 5.94 |
| SqueezeNet 1.1 | 41.81 | 19.38 |
| Densenet-161 | 22.35 | 6.2 |
整体来看,还是Resnet残差网络效果好。不过EfficientNet效果更好,不过这个模型在Torchvision中没有提供,会在之后专门讲解和提供代码模板。(先挖坑)。
- END -
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/662nyZF本站qq群1003271085。加入微信群请扫码进群(如果是博士或者准备读博士请说明):