用openai开源的whisper部署自己的语音识别系统秒杀收费产品
openai开源了自己的语音识别项目whisper,可将视频和语音文件转为文字,个人认为效果可以比肩科大讯飞的收费产品,并且无需GPU,普通配置就可以运行。
这是whisper项目的github:https://github.com/openai/whisper
但是我们今天不按照官方的文档部署,而使用这个项目https://github.com/ahmetoner/whisper-asr-webservice,这个项目在whisper基础上提供了web界面,并且可以用docker部署,非常方便。
话不多说,开始实战,下面操作基于windows系统。
一、下载镜像
docker搜索openai-whisper-asr-webservice,选择第一个pull。

二、启动
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest运行之后在浏览器输入以下地址
http://localhost:9000/第一次访问会下载模型,所以需要稍等一会,之后可以看到以下页面,到这一步已经部署成功,是不是非常简单!

三、使用
这个项目提供了2个http接口:
1./asr:语音识别接口,上传语音或者视频文件,输出文字。
2./detect-language:语言检测接口,上传语音或者视频文件,输出语言。
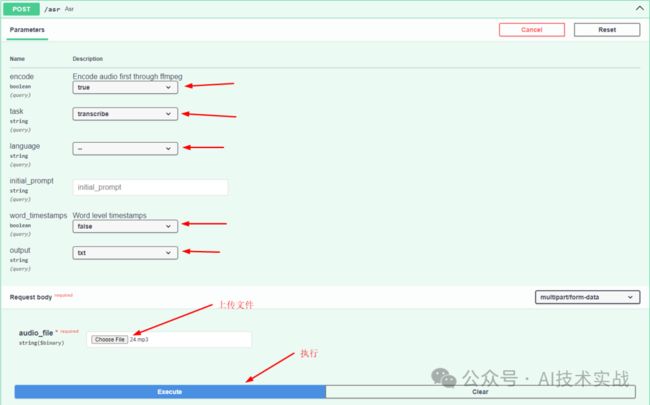
先试一下语音识别,点击"Try it out"按钮,填写参数,上传语音或视频文件,点击Execute就可以转换了。
3.1 英文音频转文字
先用一个英文mp3音频看看识别效果,可以先照抄我截图中的参数,后面会写每个参数的意思。需要音频文件的可以在这里下载:https://pan.baidu.com/s/1NSeuM1vYYYf5hHIRY_TB4w?pwd=9hkc
稍等一会即可转换完成,在response body中可看到转换结果。
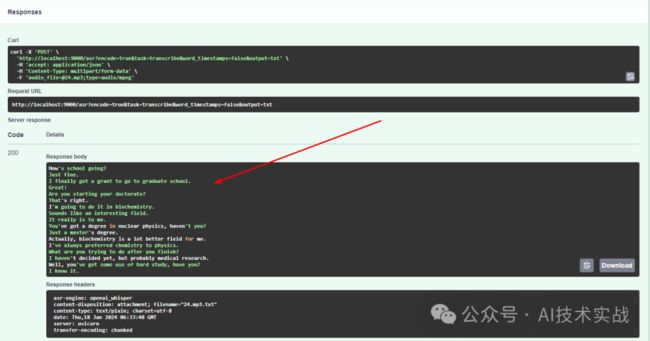
下面识别结果,可以看到效果非常不错,可以听音频对照着看一下。
英语音频,AI技术实战,38秒
How's school going?Just fine.I finally got a grant to go to graduate school.Great!Are you starting your doctorate?That's right.I'm going to do it in biochemistry.Sounds like an interesting field.It really is to me.You've got a degree in nuclear physics, haven't you?Just a master's degree.Actually, biochemistry is a lot better field for me.I've always preferred chemistry to physics.What are you trying to do after you finish?I haven't decided yet, but probably medical research.Well, you've got some use of hard study, have you?I know it.
3.2 中文视频转文字
与上面操作一样,只是选文件的时候选一个视频就可以了,我使用以下视频测试:
进度条,百分之65
以下是识别结果,对照视频看一下。
养养你长大以后,挣了钱会不会给爸爸花呀?会那你会给爸爸买什么呀?会给爸爸买小马宝链,然后再买好几个贴纸,买画饼,然后再买超清年图,再买一个外卖,再买医院,再买脑积极转弯书,再买颜色,再买小丫头,再买冰淇淋买这么多呀?嗯为什么呀?因为是我最喜欢的老板家,还有巧克力我忘说了哦,谢谢你还有水买这么多啊?对的谢谢你还有玩具还有书还有黄罐还有钟表呢抽屉会把世界上的东西全部都买一遍真的假的呀?真的我挣了好多钱,就把世界上的全部东西都给你挣了我要是挣的多,但是我要是能挣的特别多的钱就能把世界上的房子,流星,还有飞机,还有书,什么都带到咱们家里好,那你赶快长大吧,好不好?好
3.3 语言检测
不识别文字,只检测一下是什么语言,大文件只会检查前30秒。

四、修改模型

这是官方几种模型的对比说明,包括模型大小、需要的内存和相对速度,比如tiny模型中的~32x标识使用这个模型的速度是large模型的32倍。模型越大识别效果越好,如果只识别英文可以使用.en的模型。
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest上面启动命令中ASR_MODEL=base中的base就是模型名称,可以根据情况修改。
五、模型缓存
按照上面的方法每次运行docker命令后,第一次打开网页都会重新下载模型,比较耗时,我们可以按照如下方式将模型保存到宿主机的指定目录下,这样第一次打开会将模型下载到这里,之后再打开速度就快了。
docker run -d -p 9000:9000 -v c:/whiper/:/root/.cache/whisper -e ASR_MODEL=medium onerahmet/openai-whisper-asr-webservice:latest上面增加了-v c:/whisper/:/root/.cache/whisper,其中c:/whisper是我自己定义的目录,可以自行修改。
六、接口参数
1.encode:看意思是识别之前先通过ffmpeg编码音视频文件,但是暂时不清楚什么情况下不用编码,上面测试的音频如果选false识别不出来结果,所以这里就固定写true吧,如果有人知道可以评论区留言。
2.task:选择transcribe就是将语音识别为文字,中文语音识别为中文文字,英文语音识别为英文文字;选择translate是将无论源文件中是什么语言,都在识别后先翻译为英文再输出。
3.language:告诉接口源文件中是用的什么语言,这个不需要指定,可以自动识别出来,如果指定错了输出的结果是不对的,比如本来是英文,但是参数填写为中文,识别程序就会以中文来识别,结果就是完全错的。
4.initial_prompt:应该是类似于chatgpt的prompt吧,但是感觉没什么需要填写的必要。
5.word_timestamps:单词级别的时间戳。在输出格式为json时起作用,会输出每个单词的开始时间、结束时间、识别正确的可能性。
6.output:输出格式。
txt:文本格式。
vtt、srt:字幕格式,可以给视频制作字幕。
tsv:类似于csv的一种制表符分隔的数据格式。
json:可以输出非常详细的信息。