import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, label_binarize
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import precision_recall_curve, average_precision_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
def data_preproce():
# 加载数据,数据预处理
digits = datasets.load_digits()
X, y = digits.data, digits.target
random_state = np.random.RandomState(0)
n_example, n_features = X.shape
X = np.c_[X, random_state.randn(n_example, 10 * n_features)] # 添加噪声特征
X = StandardScaler().fit_transform(X) # 标准化
y = label_binarize(y, classes=np.unique(y)) # one-hot
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0,
shuffle=True, stratify=y)
return X_train, X_test, y_train, y_test
def model_trian(model):
# 模型训练
classifier = OneVsRestClassifier(model)
classifier.fit(X_train, y_train)
y_score = classifier.decision_function(X_test)
return y_score
def micor_PR(y_test, y_score):
# For each class
precision = dict()
recall = dict()
average_precision = dict()
n_classes = y_score.shape[1] # 类别数
for i in range(n_classes):
# Compute precision-recall pairs for different probability thresholds.
precision[i], recall[i],_ = precision_recall_curve(y_test[:, i], y_score[:, i])
# Compute average precision (AP) from prediction scores.
# \\text{AP} = \\sum_n (R_n - R_{n-1}) P_n
average_precision[i] = average_precision_score(y_test[:, i], y_score[:, i])
# A "micro-average": quantifying score on all classes jointly
precision["micro"], recall["micro"],_ = precision_recall_curve(y_test.ravel(), y_score.ravel())
average_precision["micro"] = average_precision_score(y_test, y_score, average="micro")
return precision, recall, average_precision
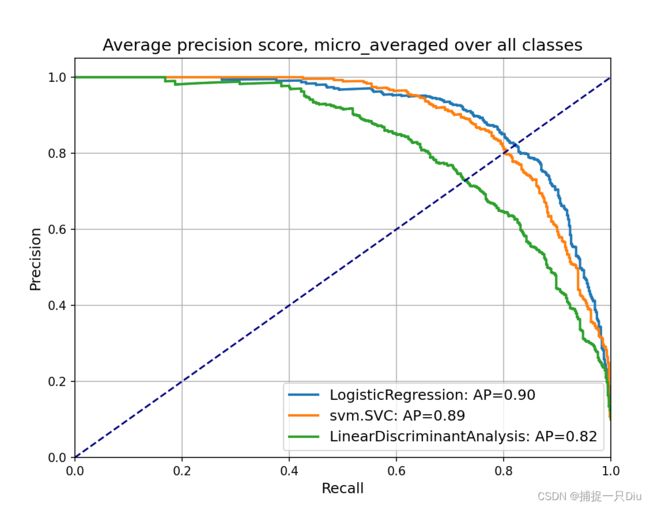
def plt_PR_curve(precision, recall, average_precision, label):
# 绘制P-R曲线
label = label + ': AP={0:0.2f}'.format(average_precision["micro"])
plt.step(recall['micro'], precision['micro'], where='post', lw=2, label=label) # 绘制接替图
X_train, X_test, y_train, y_test = data_preproce()
y_score = model_trian(LogisticRegression())
precision, recall, average_precision = micor_PR(y_test, y_score)
plt.figure(figsize=(8, 6))
plt_PR_curve(precision, recall, average_precision, "LogisticRegression")
y_score = model_trian(SVC())
precision, recall, average_precision = micor_PR(y_test, y_score)
plt_PR_curve(precision, recall, average_precision, "svm.SVC")
y_score = model_trian(LinearDiscriminantAnalysis())
precision, recall, average_precision = micor_PR(y_test, y_score)
plt_PR_curve(precision, recall, average_precision, "LinearDiscriminantAnalysis")
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlabel('Recall', fontsize=12)
plt.ylabel('Precision', fontsize=12)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.grid()
plt.title('Average precision score, micro_averaged over all classes', fontsize=14)
plt.legend(fontsize=12)
plt.show()
from itertools import cycle
# setup plot details
y_score = model_trian(LogisticRegression())
precision, recall, average_precision = micor_PR(y_test, y_score)
plt.figure(figsize=(9, 8))
f_scores = np.linspace(0.2, 0.8, num=4)
lines, labels = [], [] # 图例线条和标签值
# F-score 等高线绘制
for f_score in f_scores:
x = np.linspace(0.01, 1)
y = f_score * x / (2 * x - f_score)
line, = plt.plot(x[y >= 0], y[y >= 0], color='gray', ls='--', alpha=0.5)
# alpha参数用于设置透明度,0~1之间,alpha越小,线条越透明
plt.annotate('f1={0:0.1f}'.format(f_score), xy=(0.9, y[45] + 0.02)) # annotate注释
lines.append(line)
labels.append('iso-f1 curves')
line, = plt.plot(recall["micro"], precision["micro"], ls="-.", lw=2)
lines.append(line)
labels.append('micro-average(area = {0:0.2f})'.format(average_precision["micro"]))
for i in range(y_score.shape[1]):
line, = plt.plot(recall[i], precision[i], lw=1.5)
lines.append(line)
labels.append('class {0} (area = {1:0.2f})'.format(i, average_precision[i]))
fig = plt.gcf()
fig.subplots_adjust(bottom=0.25)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall', fontsize=12)
plt.ylabel('Precision', fontsize=12)
plt.title('Extension of Precision-Recall curve to multi-class', fontsize=14)
plt.legend(lines, labels, loc=(1.02, 0), prop=dict(size=12))
plt.tight_layout()
plt.show()