MySQL项目-淘宝用户购物行为数据可视化分析
一、项目背景与目的
1.1 项目背景
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。
1.2 项目目标
本次分析的目的是想通过对淘宝用户行为数据分析,为以下问题提供解释和改进建议:
- 分析用户使用淘宝过程中的常见电商分析指标,建立用户行为转化漏斗模型,确定各个环节的流失率,找到需要改进的环节;
- 研究用户在不同时间尺度下的行为规律,找到用户在不同时间周期下的活跃规律,据此提出相应的营销策略;
- 分析用户对不同种类商品的偏好,提出针对不同商品的营销策略;
- 通过RFM模型对用户进行分层,对不同类型用户的行为进行分析,并提出相应的运营策略。
1.3 数据集来源与介绍
数据源:淘宝用户购物行为数据集_数据集-阿里云天池 (aliyun.com)
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。
| 文件名称 | 说明 | 包含特征 |
|---|---|---|
| UserBehavior.csv | 包含所有的用户行为数据 | 用户ID,商品ID,商品类目ID,行为类型,时间戳 |
UserBehavior.csv
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
注意到,用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
关于数据集大小的一些说明如下
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 用户数量 | 987,994 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
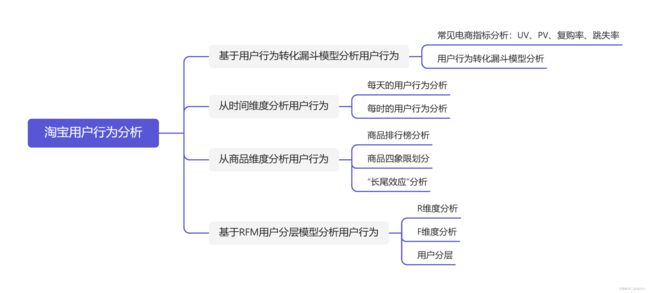
二、分析框架
三、数据清洗
3.1 数据导入
使用MySQL新建一个数据库
CREATE DATABASE IF not EXISTS 淘宝用户行为
CHARACTER SET 'utf8mb4';导入外部数据源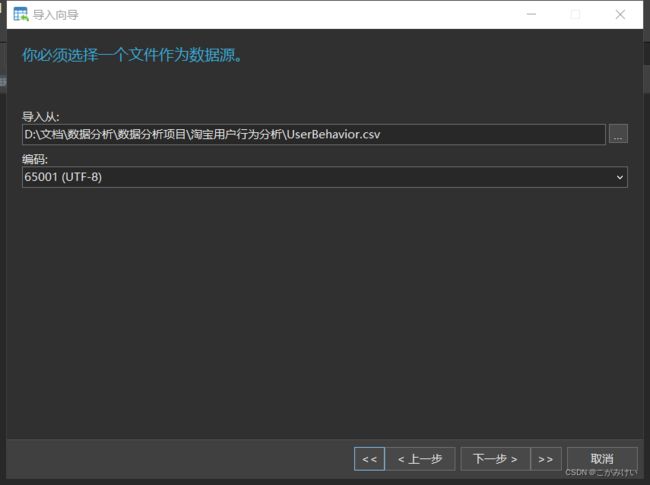
因为数据量过大,所以选择导入前1000000行数据
源数据集中不包含字段名称行,导入时字段名行设置为0,第一个数据行设置为1。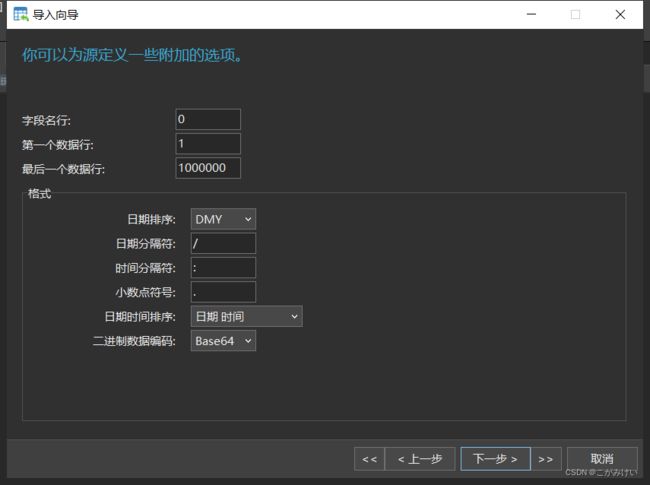
导入完成,耗时1分17秒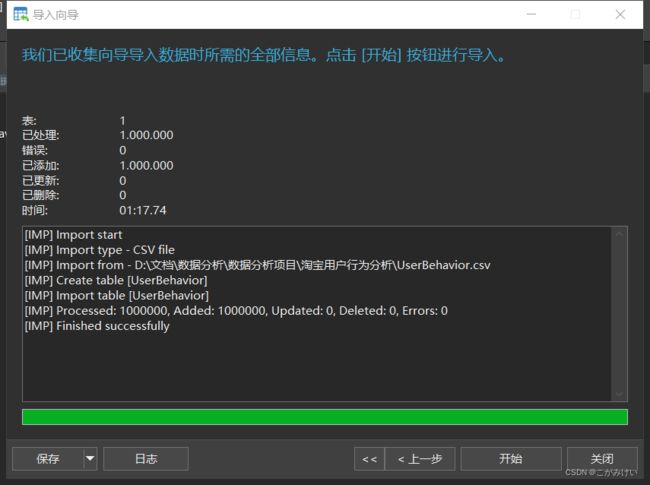
3.2 重命名列名
ALTER TABLE userbehavior
CHANGE f1 user_id VARCHAR (255),
CHANGE f2 item_id VARCHAR (255),
CHANGE f3 category VARCHAR (255),
CHANGE f4 behavior VARCHAR (255),
CHANGE f5 time_stamp VARCHAR (255);也可以直接在导入数据时重命名
3.3 去除重复值
去除重复值这里,可以将user_id,item_id,time_stamp三者进行联合,形成联合主键,对数据集进行分组。如果数据集中没有重复值,则理论上用三者进行联合分组之后,count(*)应该是不大于1的;如果数据集中有重复值,则理论上用三者进行联合分组之后,count(*)应该是大于1的。因此在这里判断count(*)是否大于1可以用having函数。
SELECT user_id, item_id, time_stamp
FROM userbehavior
GROUP BY user_id, item_id, time_stamp
HAVING COUNT(*) > 1;
结果显示没有重复值。
3.4 查看缺失值
查看缺失值,可以统计每一个字段下有多少行,如果行数是相等的说明没有缺失值。
SELECT count(user_id), count(item_id), count(category), count(behavior), count(time_stamp)
FROM userbehavior;
结果显示各字段行数相等,不存在缺失值。
3.5 时间格式转换
-- 新增date、hour时间列
ALTER TABLE userbehavior
ADD time TIMESTAMP,
ADD date VARCHAR(10),
ADD hour VARCHAR(10);
-- 时间格式转换
UPDATE userbehavior
SET time = FROM_UNIXTIME(time_stamp, '%Y-%m-%d %H:%i:%s'),
date = FROM_UNIXTIME(time_stamp, '%Y-%m-%d'),
hour = FROM_UNIXTIME(time_stamp, '%H');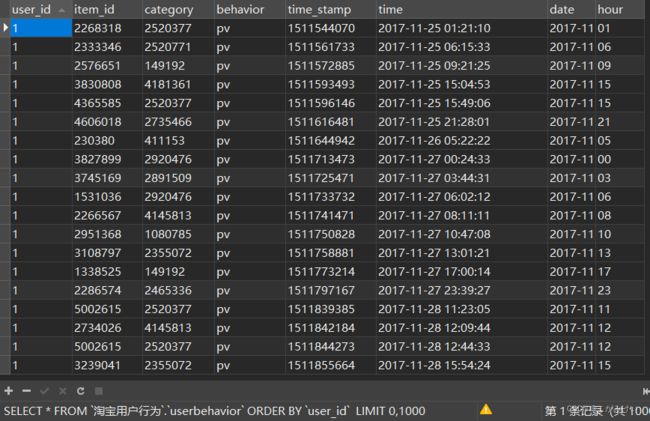
3.6 剔除异常值
需要检查日期是否都在需要分析的时间范围内,即2017年11月25日至2017年12月3日之间。
-- 检查日期是否都在2017年11月25日至2017年12月3日之间
SELECT MIN(date), MAX(date)
FROM userbehavior;
剔除异常值
-- 排除日期不在2017年11月25日至2017年12月3日之间的数据
DELETE FROM userbehavior
WHERE date < '2017-11-25' OR date > '2017-12-03'; 
总共过滤掉470条异常值
检查是否剔除干净
SELECT MIN(date), MAX(date)
FROM userbehavior; 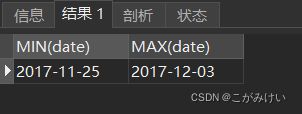
四、数据分析
4.1 基于用户行为转化漏斗模型分析用户行为
4.1.1 常见电商指标分析
4.1.1.1 UV、PV、UV/PV
-- UV、PV、UV/PV指标统计
SELECT COUNT(DISTINCT user_id) AS UV
,SUM(IF(behavior = 'pv', 1, 0)) AS PV
,SUM(IF(behavior = 'buy', 1, 0)) AS Buy
,SUM(IF(behavior = 'cart', 1, 0)) AS Cart
,SUM(IF(behavior = 'fav', 1, 0)) AS Fav
,SUM(IF(behavior = 'pv', 1, 0)) / COUNT(DISTINCT user_id) AS 'PV/UV'
FROM userbehavior;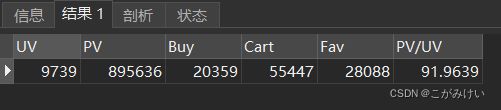
访问用户总数(UV):9739
页面总访问量(PV):895636
统计区间平均每人页面访问量(UV/PV):约为92
4.1.1.2 复购率
复购率定义:在某时间窗口内重复消费用户(消费两次及以上的用户)在总消费用户中占比(按天非去重)。
创建一个以user_id分组的用户行为数据视图,方便后续查询
-- 创建以user_id分组的用户行为数据视图
CREATE VIEW 用户行为数据 AS
SELECT user_id
,COUNT(behavior) AS 用户行为总数
,SUM(IF(behavior = 'pv', 1, 0)) AS '浏览数'
,SUM(IF(behavior = 'fav', 1, 0)) AS '收藏数'
,SUM(IF(behavior = 'cart', 1, 0)) AS '加购数'
,SUM(IF(behavior = 'buy', 1, 0)) AS '购买数'
FROM userbehavior
GROUP BY user_id
ORDER BY 用户行为总数 DESC;
SELECT * FROM 用户行为数据;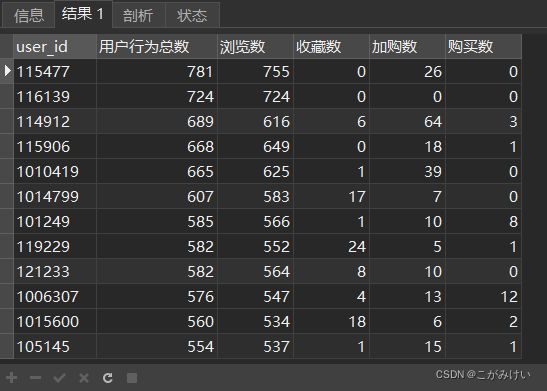
复购率
-- 复购率
SELECT SUM(IF(购买数 > 1, 1, 0)) AS '复购总人数'
,COUNT(user_id) AS '购买总人数'
,ROUND(100 * SUM(IF(购买数 > 1, 1, 0)) / COUNT(user_id), 2) AS '复购率'
FROM 用户行为数据
WHERE 购买数 > 0; 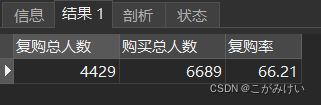
从结果来看,复购率高达66.21%,反映出淘宝的用户忠诚度较高。
4.1.1.3 跳失率
跳失率定义:仅仅访问了单个页面的用户占全部访问用户的百分比,或者从首页离开的网站的用户占所有访问用户的百分比。
跳失率可以反映用户对网站内容的认可程度,或者说网站是否对用户有吸引力。而网站的内容是否能够对用户有所帮助留住用户也直接可以在跳失率中看出来,所以跳失率是衡量网站内容质量的重要标准。
-- 跳失率
SELECT COUNT(*) AS '仅访问一次页面的用户数'
FROM 用户行为数据
WHERE 用户行为总数 = 1;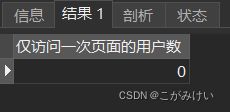
结果表明,统计区间内,没有用户仅浏览一次页面就离开淘宝,即跳失率为0。反映出商品或者商品详情页的内容对于用户具有较强的吸引力,使得用户在淘宝驻留。
综合复购率和跳失率来看,淘宝的用户忠诚度较高,且内容质量高,可以吸引用户持续使用,因此,需要重视用户关系,维系用户忠诚度。
4.1.2 用户行为转化漏斗模型分析
漏斗分析模型已经广泛应用于各行业的数据分析工作中,用以评估总体转化率、各个环节的转化率,以科学评估促销专题活动效果等,通过与其他数据分析模型结合进行深度用户行为分析,从而找到用户流失的原因,以提升用户量、活跃度、留存率,并提升数据分析与决策的科学性等。
常用漏斗模型:首页—商品详情页—加入购物车—提交订单—支付订单
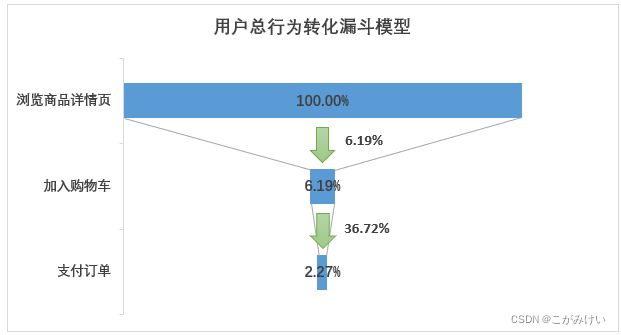
本数据集只包含商品详情页(pv)、加入购物车(cart)、支付订单(buy)数据,因此将漏斗模型简化为:商品详情页—加入购物车—支付订单。
用户总行为(PV)的转化漏斗
-- 用户总行为漏斗
SELECT behavior, COUNT(*)
FROM userbehavior
GROUP BY behavior
ORDER BY behavior DESC;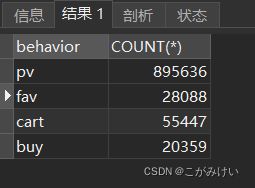
用户总行为转化漏斗图
独立访客(UV)的转化漏斗
-- 独立访客转化漏斗
SELECT behavior, COUNT(DISTINCT user_id)
FROM userbehavior
GROUP BY behavior
ORDER BY behavior DESC; 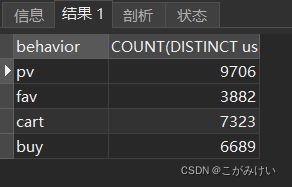
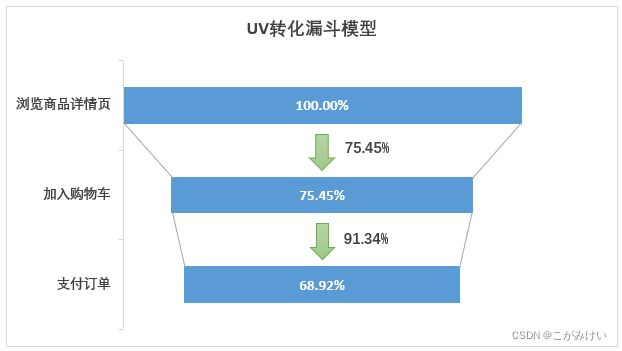
综合用户总行为转化漏斗图和独立访客转化漏斗图可以发现:
- 从浏览商品详情页PV到有购买意向只有6.19%的转化率,而从浏览商品详情页UV到有购买意向有75.45%的转化率,且通过计算可知,用户平均每次购买产生的浏览商品详情页次数为pv/buy=89 5636/20359≈44次,这说明用户在购买商品前会大量浏览商品详情页进行对比筛选。因此,浏览商品详情页这一环节是指标提升的重点环节,可以从推荐机制入手,根据用户日常浏览行为,尽量做到精准推荐,减少用户寻找信息的成本。
- 支付订单用户数占浏览商品详情页用户数的68.92%,反映出淘宝用户的购买转化率较高,淘宝上的商品能满足大部分用户的购买需求。
根据上述环节改善转化率的建议:
- 优化平台的搜索匹配度和推荐策略,主动根据用户喜好推荐相关度更高的商品,优化商品搜索的准确度和聚合能力,对搜索结果排序优先级进行优化。
- 在商品详情页的展示上突出用户关注的重点信息,精简信息流的呈现方式,减少用户寻找信息的成本。
4.2 从时间维度分析用户行为
4.2.1 每天的用户行为分析
-- 每天的用户行为分析
SELECT date
,COUNT(DISTINCT user_id) AS '每日用户数'
,SUM(IF(behavior = 'pv', 1, 0)) AS '浏览数'
,SUM(IF(behavior = 'fav', 1, 0)) AS '收藏数'
,SUM(IF(behavior = 'cart', 1, 0)) AS '加购数'
,SUM(IF(behavior = 'buy', 1, 0)) AS '购买数'
FROM userbehavior
GROUP BY date;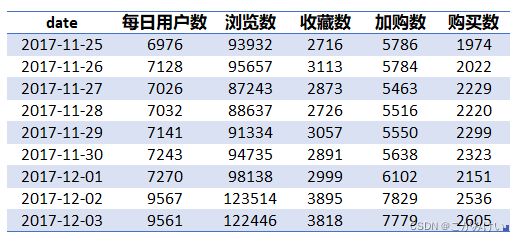
每日用户行为数据变化
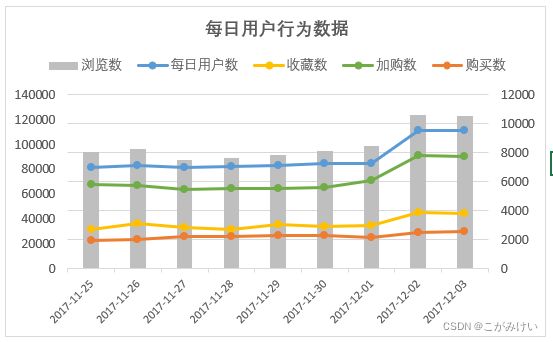
在2017年11月25日-2017年12月3日统计窗口内,11月25日-26日及12月2日-3日为周末。
通过每日用户行为数据变化可知,11月25日-12月1日,数据波动变化范围很小,12月2日-12月3日,各项数据指标明显上涨,高于前7天的各项数据指标。但上一个周末(11月25日-11月26日)的各项数据指标并未存在明显涨幅,所以12月2日-12月3日数据指标的上涨与周末的相关度较小,并且由每日用户行为数据图可知,日活跃用户数、浏览数、收藏数、加购数的涨幅相比于购买数更为明显,因此推测12月2日-12月3日数据指标的上涨可能与淘宝双十二预热活动有关,预热会使购买前置动作的浏览、收藏、加购行为量增长。
4.2.2 每时的用户行为分析
-- 每时用户行为分析
SELECT hour
,COUNT(DISTINCT user_id) AS '每日用户数'
,SUM(IF(behavior = 'pv', 1, 0)) AS '浏览数'
,SUM(IF(behavior = 'fav', 1, 0)) AS '收藏数'
,SUM(IF(behavior = 'cart', 1, 0)) AS '加购数'
,SUM(IF(behavior = 'buy', 1, 0)) AS '购买数'
FROM userbehavior
GROUP BY hour;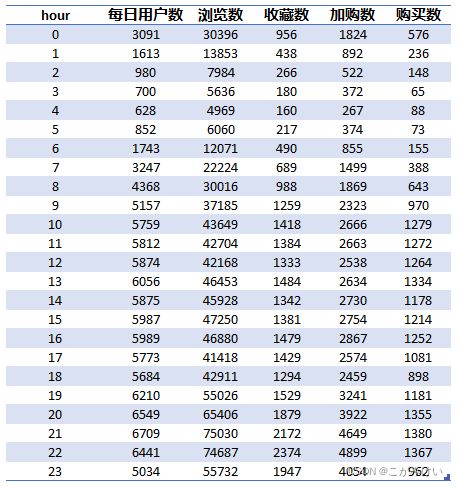
每时用户行为数据变化
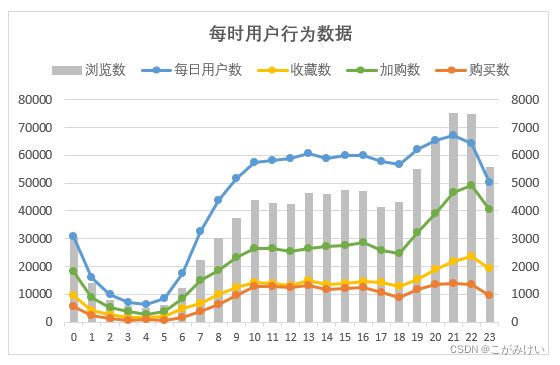
通过每时用户行为数据变化可知,在2-5点左右,各项数据指标进入低谷期,在9-18点,数据呈现一个小高峰,波动变化较小(其中,在12点和16-17点有小幅度下降),在18-23点,各数据指标呈现一个大高峰,并且在21点左右达到日数据的最大峰值,数据的变化趋势符合大部分用户的正常作息规律。
在制定运营策略时,可以利用这个规律进行创收,选择在用户最活跃的时间段20-22点间使用直播带货、优惠活动等营销手段。
4.3 从商品维度分析用户行为
可以从销量和浏览量两个维度对商品受欢迎程度进行分析。浏览量高的商品可能是因为被页面或广告等吸引而来,或者只是感兴趣,用户并不一定会购买;而销量高的商品可能才是用户真正需要的,用户搜索和点击购买的目标比较明确。因此需要同时结合销量与浏览量两个维度进行分析。
4.3.1 商品排行榜分析
4.3.1.1 商品销量排行榜前10
查询销量前十的商品
-- 售出商品总数
SELECT COUNT(DISTINCT item_id)
FROM userbehavior
WHERE behavior = 'buy';
-- 商品销量排行榜前10
SELECT item_id, COUNT(behavior) AS '购买次数'
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY item_id
ORDER BY 购买次数 DESC
LIMIT 10; 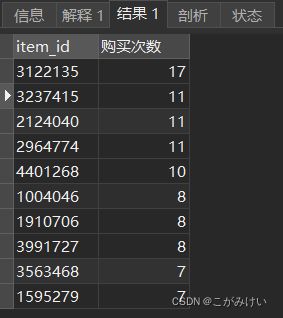
从商品销量排行榜可以发现,售出的17565件商品中,单个商品销量最多不超过17次,且仅有5件商品销量超过10次。可见在分析的数据集中没有爆款商品,满足客户需求靠的还是商品的多样化,所以可以将注意力更多放在增加商品的多样性上,而非打造爆款商品。
4.3.1.2 商品浏览量排行榜前10
查询浏览量前十的商品
-- 商品浏览量排行榜前10
SELECT item_id, COUNT(behavior) AS '浏览次数'
FROM userbehavior
WHERE behavior = 'pv'
GROUP BY item_id
ORDER BY 浏览次数 DESC
LIMIT 10;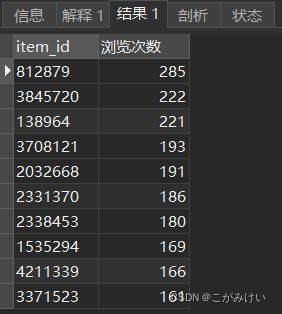
连接销量前十和浏览量前十的表,对销量和浏览量的相关性进行初步分析
-- 商品销量榜单与浏览量榜单表连接(top10)
SELECT a.item_id, a.购买次数, b.浏览次数
FROM (
SELECT item_id, COUNT(behavior) AS '购买次数'
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY item_id
ORDER BY 购买次数 DESC
LIMIT 10
) AS a
LEFT JOIN (
SELECT item_id, COUNT(behavior) AS '浏览次数'
FROM userbehavior
WHERE behavior = 'pv'
GROUP BY item_id
ORDER BY 浏览次数 DESC
LIMIT 10
) AS b
ON a.item_id = b.item_id;

连接销量前20和浏览量前20的表
-- 商品销量榜单与浏览量榜单表连接(top20)
SELECT a.item_id, a.购买次数, b.浏览次数
FROM (
SELECT item_id, COUNT(behavior) AS '购买次数'
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY item_id
ORDER BY 购买次数 DESC
LIMIT 20
) AS a
LEFT JOIN (
SELECT item_id, COUNT(behavior) AS '浏览次数'
FROM userbehavior
WHERE behavior = 'pv'
GROUP BY item_id
ORDER BY 浏览次数 DESC
LIMIT 20
) AS b
ON a.item_id = b.item_id
WHERE 浏览次数 IS NOT NULL; 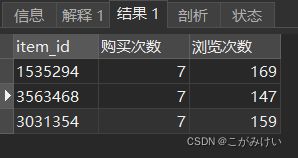
连接商品销量、浏览量、收藏量、加购量前20的表
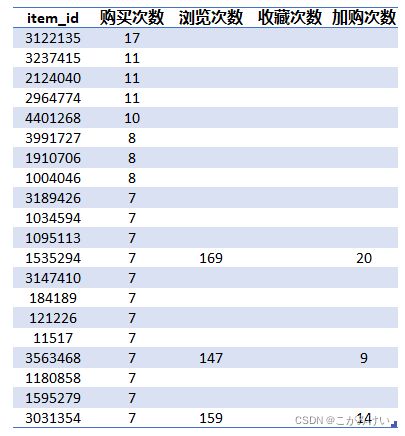
结果显示,销量前10的商品其浏览量均未排到前10,销量前20的商品中也只有3件商品的浏览量、加购量排到了前20。反映出销量与浏览量(以及收藏、加购量)的相关性较差,销量高的商品浏览量(以及收藏、加购量)不一定高,因此需要同时结合销量与浏览量两个维度进行分析。下面将以商品销量和浏览量两个维度对商品进行四象限划分,分析不同商品对应的用户行为,并提出相应的改进措施。
4.3.2 商品四象限划分
销量和浏览量两个维度的界限值分别取4、40(需要根据实际业务场景确定界限值),将商品按照销量和浏览量划分为四个象限。
-- 查询所有商品的浏览量与销量
SELECT item_id
,SUM(IF(behavior = 'pv', 1, 0)) AS '浏览次数'
,SUM(IF(behavior = 'buy', 1, 0)) AS '购买次数'
FROM userbehavior u
GROUP BY item_id
ORDER BY 购买次数 DESC;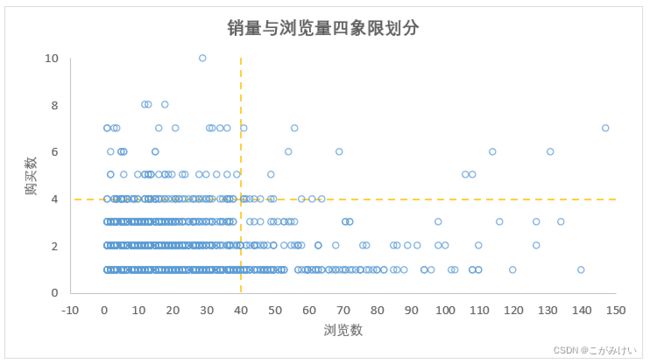
第Ⅰ象限:商品浏览量与销量都较高,说明商品转化率较高,属于受用户欢迎的商品。
优化方法:重点推送该象限内的商品,提高曝光量,同时可以多做活动,吸引更多的潜在用户。
第Ⅱ象限:商品的销量较高,但浏览量较低。产生这种现象可能有以下两种原因:
①该象限内的商品可能属于某类特定群体的刚需产品,特定受众搜索和浏览的目标比较明确;
②该象限内的商品受众广,本身转化率就高,但是引流入口数量少,导致曝光量少。
优化方法:收集购买与浏览该象限内商品的用户的信息,分析用户画像,并结合商品特点,核实商品是否存在特定受众。
①若存在,平台可以针对该类用户进行定向推送、精准推送,还可以建立该类用户的专属社群,为用户交流提供更便捷的平台,进一步增加用户粘性;
②若不存在,则可以对该象限内的商品多做推广,设置高频率搜索关键词,从而提高曝光率,并增加引流入口,浏览量增加,销量可能会随之提升。
第Ⅲ象限:商品的浏览量和销量都较低,需要考虑引流入口和商品本身两方面的原因。
优化方法:
①考虑是否对商品的宣传力度过小,引流入口数量少,可以尝试提高商品的曝光量。
②若提高曝光量后商品的销量还是比较低迷,说明用户对商品不感兴趣,就需要考虑商品是否是用户真正需要的,效果不好的商品可以考虑直接优化掉。
第Ⅳ象限:商品的浏览量较高,但销量较低,说明商品的转化率低,可以从以下几方面分析原因:
①目标人群:商品本身的宣传非常有吸引力,但是指向性不够明确,导致很多非目标用户点击商品,但是没有购买;
②商品定价:商品定价过高,存在同类可替代的高性价比商品,用户就会转向其他同类商品;
③商品详情页、客服及评价:用户无法从详情页和客服处得到需要的商品详细信息,或者商品差评较多,或者评价中提到了用户比较介意的问题,导致用户没有购买;
④购买流程:商品优惠券使用方式复杂,或凑单购买流程复杂,使用户放弃购买。
优化方法:根据上述可能的原因使用调研、A/B测试等方法查明原因、对症下药。
4.3.3 “长尾效应”分析
长尾效应,英文名称Long Tail Effect。“头”(head)和“尾”(tail)是两个统计学名词。正态曲线中间的突起部分叫“头”;两边相对平缓的部分叫“尾”。从人们需求的角度来看,大多数的需求会集中在头部,而这部分我们可以称之为流行,而分布在尾部的需求是个性化的,零散的小量的需求。而这部分差异化的、少量的需求会在需求曲线上面形成一条长长的“尾巴”,而所谓长尾效应就在于它的数量上,将所有非流行的市场累加起来就会形成一个比流行市场还大的市场。
长尾效应的根本就是强调“个性化”,“客户力量”和“小利润大市场”,也就是要赚很少的钱,但是要赚很多人的钱。要将市场细分到很细很小的时候,然后就会发现这些细小市场的累计会带来明显的长尾的效应。
根据商品销量对商品进行分类统计
-- 根据商品销量对商品进行分类统计
SELECT t.购买次数, COUNT(t.item_id) AS '商品量'
FROM (
SELECT item_id, COUNT(item_id) AS '购买次数'
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY item_id
ORDER BY 购买次数 DESC
) AS t
GROUP BY t.购买次数
ORDER BY 商品量 DESC;

根据不同销量对应的商品量数据,在售出的17565件商品中,只购买一次的商品有15536件,占下单总商品数的88.45%,说明淘宝的商品售卖主要是依靠长尾商品的累积效应,并非爆款商品的带动。
4.4 基于RFM用户分层模型分析用户行为
由于数据集中不包含订单金额,故本次分析中不考虑M维度,只从R、F两个维度来分析,对两个维度的指标进行分级打分,最终按照综合得分对用户分层。
4.4.1 R维度分析
计算用户的最近消费时间间隔R值(R值越小,说明用户最后消费时间越近),并对R值进行打分。根据R值结果,将其均分为三个区间[0:2],[3:5],[6:8],分别赋予R_score值3、2、1分。
-- RFM模型——R维度分析
CREATE VIEW r_value AS
SELECT user_id, DATEDIFF('2017-12-03', MAX(date)) AS R
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY user_id;
-- 进行R维度打分
CREATE VIEW r_score AS
SELECT user_id, R
,CASE
WHEN R BETWEEN 0 AND 2 THEN 3
WHEN R BETWEEN 3 AND 5 THEN 2
ELSE 1
END AS R_score
FROM r_value;
-- 统计R_score数量
SELECT R_score, COUNT(R_score)
FROM r_score
GROUP BY R_score
ORDER BY R_score DESC;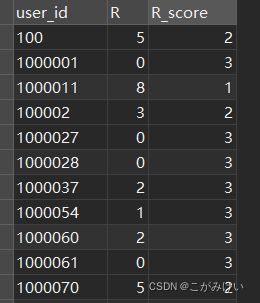
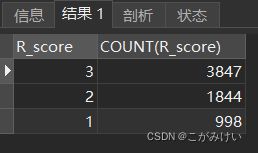
统计不同R_score的占比
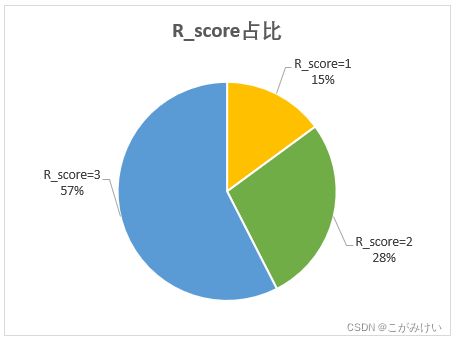
从R_score占比中可以发现,有超过半数的用户最近一次购买时间在近3天内,说明淘宝有较好的用户粘性。
4.4.2 F维度分析
计算用户的消费频率F值(F值越小,说明用户一段时间内消费次数越多),并对F值进行打分。根据F值结果(最大值为72),将其分为6个区间[1:9],[10:19],[20:29],[30:39],[40:49],[50:72],分别赋予R_score值1、2、3、4、5、6分。
-- RFM模型——F维度分析
CREATE VIEW f_value AS
SELECT user_id, COUNT(behavior) AS F
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY user_id;
-- 进行F维度打分
CREATE VIEW f_score AS
SELECT user_id, F
,CASE
WHEN F BETWEEN 1 AND 9 THEN 1
WHEN F BETWEEN 10 AND 19 THEN 2
WHEN F BETWEEN 20 AND 29 THEN 3
WHEN F BETWEEN 30 AND 39 THEN 4
WHEN F BETWEEN 40 AND 49 THEN 5
ELSE 6
END AS F_score
FROM f_value;
-- 统计F_score数量
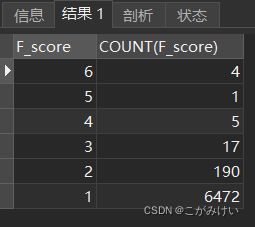
SELECT F_score, COUNT(F_score)
FROM f_score
GROUP BY F_score
ORDER BY F_score DESC;
统计不同的F_score占比
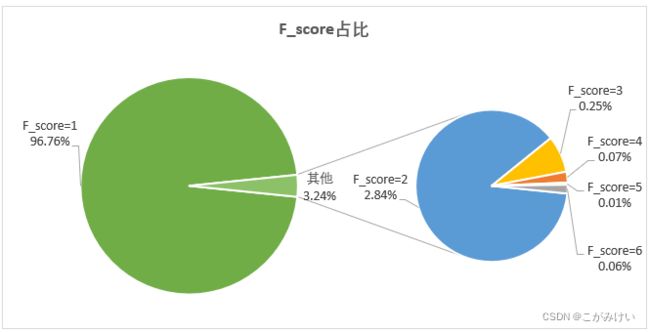
从F_score占比中可以发现,在统计区间内,96.76%的用户在淘宝消费了1-9次,只有3.24%用户在淘宝消费了10次及以上。
4.4.3 用户分层
对R和F进行综合打分,并据此分数对用户分层:将用户分为2-3分、4-5分、6-7分、8-9分四个等级,分别对应易流失用户、挽留用户、发展用户、忠诚用户。
-- RF综合打分
CREATE VIEW rf_score AS
SELECT r.user_id, R_score, F_score
,R_score + F_score AS RF_score
FROM r_score r join f_score f
ON r.user_id = f.user_id;
-- 用户分层并统计不同类型用户数量
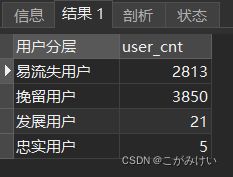
SELECT 用户分层, COUNT(*) AS user_cnt
FROM (
SELECT *
,CASE WHEN RF_score BETWEEN 2 AND 3 THEN '易流失用户'
WHEN RF_score BETWEEN 4 AND 5 THEN '挽留用户'
WHEN RF_score BETWEEN 6 AND 7 THEN '发展用户'
ELSE '忠实用户' END AS '用户分层'
FROM rf_score
) AS t
GROUP BY 用户分层;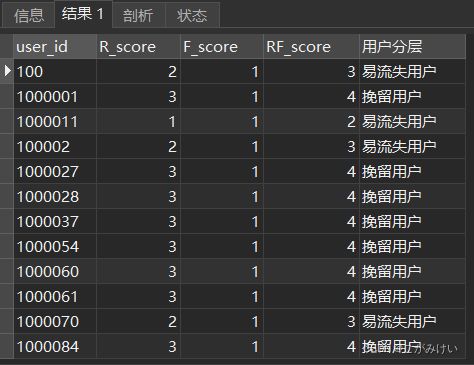
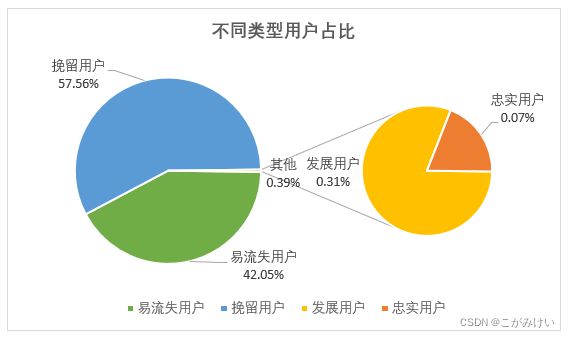
统计不同类型用户占比
用户分层结果:
- 挽留用户的占比最高,这部分用户待挖掘的潜在价值很大,应该对这部分用户进行定时促活,如上新提醒、优惠发放、提供更精准的商品推荐等,留住用户并提高其消费频率;
- 易流失用户占比较高,这部分用户可能找到了其他平台的替代品或是产品体验不佳,可以通过对该部分用户进行调研找到易流失原因,并采取价格激励、优惠发放等方式及时召回用户;
- 发展用户占比较低,可以对这部分用户定期推送新品和促销活动来进一步提高消费频率;
- 忠诚用户占比最低,这部分用户属于高价值用户,需要制定专属的运营策略来保持用户粘性,如专属优惠、专属客服等。
用户分层效果分析:
从不同用户占比上来看,本次用户分层的效果不佳,可能有以下两方面原因:
- 两个维度的打分区间划分的不合理,没有很好的区分用户,应该在做区间划分时提前看下各维度的用户分布情况,结合实际业务场景需求进行区间划分;
- 两个维度划分的区间数不一致,且赋予的分值区间差异较大,这相当于给两个维度赋予了不同的权重。
可能采取RF两个维度的四象限划分散点图效果会更好。
五、结论与建议
本文从四个维度分析了淘宝用户行为数据近100万条,整体结论和建议如下:
5.1 用户行为转化漏斗分析
- 根据复购率和跳失率来看,淘宝平台的商品对用户具有足够的吸引力(复购率高,跳失率低),说明淘宝平台目前处于“忠诚度模式”中,重点为维系老用户的忠诚度。
- 根据用户行为转化分析来看,淘宝平台的商品能够满足大部分用户的需求(购买转化率较高)。从浏览商品详情页UV到有购买意向有75.45%的转化率,而从浏览商品详情页PV到有购买意向只有6.19%的转化率,说明用户在购买商品前会大量浏览商品详情页进行对比筛选。浏览商品详情页这一环节是指标提升的重点环节,可以从推荐机制入手,根据用户日常浏览行为,尽量做到精准推荐,减少用户寻找信息的成本。
针对上述环节改善转化率的建议:
- 优化平台的搜索匹配度和推荐策略,主动根据用户喜好推荐相关度更高的商品,优化商品搜索的准确度和聚合能力,对搜索结果排序优先级进行优化。
- 在商品详情页的展示上突出用户关注的重点信息,精简信息流的呈现方式,减少用户寻找信息的成本。
5.2 时间维度用户行为分析
- 从日期维度来看,用户的各种行为数据指标在周末和工作日的差别不大,但是受双12等大型平台活动影响较大。可以进一步扩大分析范畴,比如以一年为单位进行环比分析,标注出各个比较大的购物节,重点关心购物节前后的用户行为数量变化,同时对每周末进行比较,分析购物节推广活动安排在周末/非周末对用户行为的影响;在一年中对各个月进行同比分析,对比购买行为的趋势,找出整月中是否有购买行为上升的规律(结合用户年龄数据进行分析,购买行为上升可能与发工资的时段有关)。
- 从时间维度来看,用户的各种行为活跃高峰期都在晚间的20-22点,在制定运营策略时,可以利用这个规律进行创收,选择在用户最活跃的时间段20-22点间使用直播带货、优惠活动等营销手段。
5.3 商品维度分析用户行为
商品销量与商品浏览量的相关性较差,浏览量高的商品销量不一定高,销量高的商品浏览量不一定高,所以没有必要一味提高浏览量, 销量并不会随之增加。根据四象限划分图的分析,应重点提升第二、三、四象限内的商品:
- 针对第二象限的商品(销量高,浏览量低)应分析用户画像,若存在特定受众,平台可以针对该类用户进行定向推送、精准推送,还可以建立该类用户的专属社群,为用户交流提供更便捷的平台,进一步增加用户粘性;若不存在特定受众,则可以对该象限内的商品多做推广,设置高频率搜索关键词,提高曝光率,并增加引流入口;
- 针对第三象限的商品(销量低,浏览量低)应尝试提升商品的曝光量,分析销量是否会随之提升,若提高曝光量后商品的销量还是比较低迷,说明用户对商品不感兴趣,就需要考虑商品是否是用户真正需要的,效果不好的商品可以考虑直接优化掉;
- 针对第四象限的商品(销量低,浏览量高)应从目标人群、商品定价、商品详情页、客服及评价、购买流程这几个方面着手,根据可能的原因使用调研、A/B测试等方法查明原因、对症下药。
5.4 “二八定律”or“长尾效应”
通过分析发现,淘宝平台商品的销量主要是依靠“长尾效应”而非爆款商品的带动,但是繁多的种类对于商家来说其实是一种经营负担,成本也较高。根据“二八定律”,商家其实可以通过打造爆款商品来获利。对于爆款商品,建议品控上提高产品质量,宣传上增大力度(在其他平台上引流),展现上突出产品优势(主图、详情页、评论)等。
5.5 RMF模型分析
通过RFM模型对用户进行分层,并对不同类型的用户采取不用的运营策略:
- 挽留用户:这部分用户待挖掘的潜在价值很大,应该对这部分用户进行定时促活,如上新提醒、优惠发放、提供更精准的商品推荐等,留住用户并提高其消费频率;
- 易流失用户:这部分用户可能找到了其他平台的替代品或是产品体验不佳,可以通过对该部分用户进行调研找到易流失原因,并采取价格激励、优惠发放等方式及时召回用户;
- 发展用户:可以对这部分用户定期推送新品和促销活动来进一步提高消费频率;
- 忠诚用户:这部分用户属于高价值用户,需要制定专属的运营策略来保持用户粘性,如专属优惠、专属客服等。